
Resumen | Este codelab fue creado para comprender los diferentes paradigmas de programación en sistemas embebidos. Se estudian las técnicas como el super loop, las interrupciones, las máquinas de estado finito y los planificadores de tareas. Con este recurso se espera que usted al finalizar esté en capacidad de:
|
Fecha de Creación: | 2024/03/01 |
Última Actualización: | 2024/03/01 |
Requisitos Previos: | |
Adaptado de: | |
Referencias: | |
Escrito por: | Fredy Segura-Quijano |
En la programación software de dispositivos hardware, existen varios paradigmas que permiten gestionar y controlar de manera eficiente los dispositivos y sistemas embebidos. Uno de estos paradigmas es la programación por super loop, donde el código se ejecuta en un bucle/ciclo infinito que itera continuamente a través de las tareas, verificando condiciones y actuando en consecuencia, lo cual es simple pero puede ser ineficiente para sistemas más complejos o que ejecuten muchas funciones. Por otro lado, la programación usando interrupciones se basa en un esquema de Background/Foreground, donde las tareas críticas (foreground) son manejadas por rutinas de interrupción que se ejecutan en respuesta a eventos específicos, mientras que el bucle principal (background) realiza tareas de menor prioridad. También se puede hablar de la programación usando máquinas de estado finitas (FSM), las cuales organizan el comportamiento del sistema en estados discretos, facilitando el diseño y el seguimiento de sistemas que requieren transiciones claras y bien definidas entre diferentes modos de operación. Esta estrategia es muy frecuente en dispositivos de lógica programable, como las FPGAs o los lenguajes de descripción de hardware; sin embargo claramente aplica en programación software, siendo una muy buena forma de definir las transiciones y funcionalidad del sistema. Finalmente, la programación usando planificadores de tareas se implementa en sistemas operativos en tiempo real (RTOS), que proporcionan mecanismos de planificación avanzada para gestionar múltiples tareas simultáneamente, garantizando la respuesta en tiempo real mediante el uso de prioridades, interrupciones y sincronización eficiente entre tareas. Estos paradigmas ofrecen diferentes niveles de control y complejidad, adaptándose a las necesidades específicas de cada aplicación en el diseño de sistemas embebidos.
Programación del tipo espagueti (anti patrón).
Antes de explicar los paradigmas de programación más representativos, podemos hablar de la "programación del tipo espagueti"; que es un término que se usa para describir un estilo de programación caracterizado por un código desordenado y difícil de seguir. Este término se refiere a la maraña o enredo de código que resulta de malas prácticas de programación, donde el flujo del programa se entrelaza de manera confusa y complicada, similar a un plato de espaguetis enredados. Este estilo de programación es considerado un antipatrón, es decir, una práctica de diseño de software que se reconoce como ineficiente y problemática. A continuación describimos este estilo de programación para evidenciar principalmente elementos que deben tenerse en cuenta a la hora de programar y de esta manera aprender a evitar malas prácticas en el desarrollo de software, sobre todo para Sistemas Embebidos donde los recursos son limitados y el programador debe ser cuidadoso en cuanto a uso de memoria y tiempos de ejecución.
Características de la Programación del Tipo Espagueti.
A continuación se presentan algunas características de este tipo de programación:
- Uso de de saltos arbitrarios:
- Uso excesivo de saltos incondicionales (como el comando goto en muchos lenguajes de programación).
- Flujos de control difíciles de seguir debido a múltiples puntos de entrada y salida en bloques de código.
- Código sin modularizar:
- Ausencia de funciones o procedimientos bien definidos.
- Grandes bloques de código sin una estructura clara o lógica.
- Dependencias no claras:
- Variables globales y estados compartidos que se modifican en lugares no evidentes.
- Funciones y procedimientos que dependen unos de otros de maneras complejas y ocultas.
- Difícil mantenimiento:
- El código es difícil de entender, lo que dificulta su mantenimiento y la corrección de errores.
- Añadir nuevas funcionalidades o modificar las existentes se vuelve arriesgado y complicado.
Ejemplo (1) de programación tipo espagueti.
A continuación presentamos un ejemplo simple en C que ilustra la programación tipo espagueti mediante el uso excesivo de la sentencia goto:
#include <stdio.h>
void spaghetti() {
int x = 0;
start:
printf("Start\n");
x++;
if (x < 3) {
goto middle;
} else {
goto end;
}
middle:
printf("Middle\n");
if (x % 2 == 0) {
goto start;
} else {
goto end;
}
end:
printf("End\n");
}
int main() {
spaghetti();
return 0;
}En este ejemplo se puede evidenciar que el flujo del programa es difícil de seguir debido a los saltos arbitrarios entre las etiquetas start, middle y end. Adicionalmente la lógica de la función es confusa y no modularizada, lo que hace que sea difícil entender y mantener el código.
Ejemplo (2) de programación tipo espagueti.
const int ledPin = 13;
int mode = 0; // 0: Off, 1: Blinking, 2: On
unsigned long previousMillis = 0;
const long interval = 1000; // Intervalo de parpadeo en milisegundos
void setup() {
pinMode(ledPin, OUTPUT);
}
void loop() {
// Bloque de código espagueti
if (mode == 0) {
// Modo apagado
digitalWrite(ledPin, LOW);
if (/* alguna condición */) {
mode = 1;
}
else if (/* otra condición */) {
mode = 2;
}
// Aquí se bloquea en modo 0 si no se cumple ninguna condición
}
if (mode == 1) {
// Modo parpadeo
unsigned long currentMillis = millis();
if (currentMillis - previousMillis >= interval) {
previousMillis = currentMillis;
int state = digitalRead(ledPin);
digitalWrite(ledPin, !state);
}
if (/* alguna condición */) {
mode = 0;
}
else if (/* otra condición */) {
mode = 2;
}
// Aquí se bloquea en modo 1 si no se cumple ninguna condición
}
if (mode == 2) {
// Modo encendido continuo
digitalWrite(ledPin, HIGH);
if (/* alguna condición */) {
mode = 0;
}
else if (/* otra condición */) {
mode = 1;
}
// Aquí se bloquea en modo 2 si no se cumple ninguna condición
}
}En este ejemplo se puede evidenciar que existe bloqueo del flujo de control dado que cada bloque if controla un modo y puede bloquear la ejecución si las condiciones no cambian, lo que hace que el flujo de control sea difícil de seguir. También se puede evidenciar falta de Modularidad dado que el código para cada modo está mezclado dentro del bucle loop(), lo que dificulta la comprensión y el mantenimiento. Finalmente hay confusión en las condiciones, esto porque las condiciones para cambiar de modo no están claramente definidas, lo que añade confusión y dificulta la predicción del comportamiento del programa.
Consecuencias de la programación tipo espagueti.
Una de las consecuencias de una programación de este estilo es la baja legibilidad, lo que representa que es difícil para otros desarrolladores (o incluso para el mismo desarrollador después de un tiempo) entender el código. Adicionalmente hay una clara dificultad para depurar el código, de manera que localizar y corregir errores es complicado debido al flujo de control no intuitivo. Finalmente se tiene un mantenimiento costoso, lo que hace que hacer cambios o añadir nuevas funcionalidades puede introducir nuevos errores y complicar aún más el código y el resultado del mismo.
Cómo Evitar la programación tipo espagueti.
Dentro de las recomendaciones generales que se tiene para evitar este tipo de programación y en general para cualquier desarrollo de código es importante tener en cuenta:
- Usar buenas prácticas de programación: esto se logra al modularizar el código dividiéndolo en funciones y procedimientos claros y bien definidos. También se debe evitar el uso de goto y otros constructos que rompan el flujo de control estructurado. Este es un claro momento donde una Máquina de Estados Finita permite organizar la ejecución de los eventos del sistema evitando perder ese flujo de control.
- Adoptar principios de diseño sólidos: esto se refiere a seguir principios de diseño como SOLID (acrónimo que representa cinco principios de diseño orientado a objetos destinados a crear sistemas más comprensibles, flexibles y mantenibles), DRY (Don't Repeat Yourself: principio de desarrollo de software que enfatiza la reducción de duplicidad en el código ), y KISS (Keep It Simple, Stupid: que es un principio de diseño que enfatiza la simplicidad y sugiere que los sistemas deben ser tan simples como sea posible, evitando la complejidad innecesaria). Finalmente se recomienda utilizar patrones de diseño reconocidos para organizar el código de manera clara y mantenible.
- Documentar el código: se deben añadir comentarios y documentación que expliquen la lógica y el propósito del código, usando nombres de variables y funciones descriptivas para mejorar la legibilidad.
- Revisiones de código: se deben realizar revisiones de código regulares para identificar y corregir problemas de diseño, al igual que fomentar una cultura de calidad de código dentro del equipo de desarrollo.
En general este tipo de programación no es un patrón, ni un estándar. Se puede tener uso recurrente de sentencias condicionales anidadas (if – then – else – while), que generan dificultad en la estructura del código. Hay repetición de partes del código para comprobación o por simple descuido, que pueden hacerse en una misma función y finalmente se usan "códigos de bloqueo" p.e. while(!condicion), lo que hace que el programa quede esperando tiempo indefinido hasta que la condición se valide. Optimizar este tipo de código siempre será difícil, ya que desde el entendimiento del mismo se puede tardar tiempo el desarrollador.
Programación por super loop.
La técnica de Super loop es un paradigma de programación utilizado comúnmente en sistemas embebidos simples. Consiste en un bucle principal que se ejecuta indefinidamente, iterando a través de todas las tareas o funciones que el sistema necesita realizar. No necesariamente el uso de super loop es una mala estrategia, lo que sucede es que a medida que aumenta el número de funciones / métodos, aparecen retardos en la ejecución de cualquiera de las otras funciones / métodos. En caso de que dichos retardos sean significativos; puede no ser una técnica adecuada de programación. A continuación se describe en detalle cómo funciona y sus características principales:
Descripción de la técnica de Super Loop
Un programa basado en Super loop tiene una estructura simple donde todas las inicializaciones se realizan al principio (setup), seguidas por un bucle infinito (while o for) que contiene el código para las tareas del sistema. Dentro del bucle, cada tarea se verifica y ejecuta si es necesario, una tras otra, de forma secuencial.
Ejemplo de Código:
void setup() {
// Inicializaciones: configuración de pines, periféricos, etc.
}
void loop() {
while (1) {
// Tarea 1: leer un sensor
leerSensor();
// Tarea 2: procesar datos
procesarDatos();
// Tarea 3: actualizar display
actualizarDisplay();
// Tarea 4: comunicarse con otro dispositivo
comunicarDispositivo();
// Se pueden incluir condiciones o retardos
if (condicion) {
realizarAccion();
}
// Retardo para evitar consumir todo el tiempo de CPU
delay(10);
}
}
void leerSensor() {
// Código para leer un sensor
}
void procesarDatos() {
// Código para procesar datos
}
void actualizarDisplay() {
// Código para actualizar el display
}
void comunicarDispositivo() {
// Código para comunicarse con otro dispositivo
}Características Principales:
El Super loop es fácil de implementar y entender, adecuado para aplicaciones sencillas donde no se requieren tiempos de respuesta estrictos. Las tareas se ejecutan en el orden en que están escritas en el bucle, lo que puede resultar en tiempos de respuesta inconsistentes si algunas tareas toman más tiempo que otras. No se utilizan interrupciones (o se minimizan), lo que significa que la ejecución de una tarea no puede ser preemptada (interrumpida por otra de mayor prioridad). No hay verdadera concurrencia, ya que cada tarea debe esperar a que las tareas anteriores se completen antes de ejecutarse. Si una tarea se bloquea o toma demasiado tiempo, puede afectar el rendimiento y la capacidad de respuesta del sistema.
Dentro de las ventajas de esta técnica se tiene que es fácil de implementar, ideal para proyectos pequeños o prototipos rápidos con un bajo overhead o uso de recursos, por lo que no hay necesidad de un sistema operativo o un planificador de tareas.
Dentro de las desventajas se tiene que no es adecuado para aplicaciones complejas con múltiples tareas que requieren tiempos de respuesta rápidos y predecibles. Puede ser ineficiente en términos de uso de CPU si se requiere polling continuo o si las tareas tienen tiempos de ejecución variables y a medida que las aplicaciones crecen en complejidad, el Super loop puede volverse difícil de mantener y depurar.
La técnica de Super loop es adecuada para aplicaciones simples donde la simplicidad y el bajo overhead son más importantes que la eficiencia y la capacidad de respuesta. Es comúnmente utilizada en sistemas embebidos pequeños, como controladores de dispositivos simples, juguetes electrónicos, y proyectos de hobby que no requieren multitarea o tiempos de respuesta estrictos.
Para aplicaciones más complejas o críticas en tiempo real, se recomiendan otros paradigmas de programación, como el uso de interrupciones, máquinas de estado finitas, o sistemas operativos en tiempo real (RTOS).
Consideraciones para una codificación eficiente en aplicaciones embebidas.
Para lograr una codificación eficiente en aplicaciones embebidas, es fundamental tener en cuenta varias consideraciones que van desde el rendimiento, el uso de recursos y la mantenibilidad del código. Entre otras consideraciones se tiene:
- Optimización del código: se debe escribir código eficiente. Esto se logra utilizando estructuras de datos y algoritmos eficientes y evitando el uso de operaciones costosas en términos de tiempo y memoria. También se puede optimizar el compilador, usando las opciones de optimización del compilador (-O2, -O3 en GCC) para mejorar el rendimiento del código generado (memoria vs velocidad de ejecución). Finalmente se puede evitar el código innecesario, eliminando el código muerto (dead code) y evitar redundancias.
- Gestión de memoria: se debe hacer uso eficiente de la memoria. Una posibilidad es preferir variables locales a globales y estáticas para reducir el uso de memoria RAM. También se puede minimizar el uso de heap, es decir evitar la asignación dinámica de memoria (uso de malloc y free) en sistemas críticos y de tiempo real debido al riesgo de fragmentación de memoria. Finalmente es muy importante verificar el tamaño de datos de manera que se use el tipo de dato adecuado para cada variable (por ejemplo, uint8_t en lugar de int si solo se necesitan almacenar valores entre 0 y 255).
- Gestión de energía: en general varios microcontroladores permiten usar modos de bajo consumo o (sleep modes) cuando el sistema no está activo para ahorrar energía. También se puede apagar los periféricos y componentes que no estén en uso.
- Eficiencia del tiempo de ejecución: Se deben usar interrupciones para manejar eventos en lugar de polling constante, lo que puede ahorrar tiempo de CPU. También se puede optimizar bucles/ciclos y condiciones para reducir el tiempo de ejecución y evitar bucles innecesarios y condiciones complejas.
- Confiabilidad y robustez: Para mejorar las características del sistema se debe implementar un control de errores robusto para manejar situaciones inesperadas y mejorar la confiabilidad del sistema. Igualmente se deben realizar pruebas exhaustivas para asegurar que el sistema funciona correctamente bajo todas las condiciones esperadas.
- Modularidad y mantenibilidad: Es importante dividir el código en módulos y funciones pequeñas y manejables. Esto mejora la legibilidad y facilita el mantenimiento. Igualmente se debe documentar el código adecuadamente para que otros desarrolladores (o usted mismo en el futuro) puedan entender y mantener el código fácilmente. Por otro lado como hemos mencionado es importante codificar bien las variables con nombres descriptivos que reflejen su propósito.
- Consistencia y estilo de codificación: se debe buscar un estilo de codificación consistente en todo el proyecto para mejorar la legibilidad y reducir errores. Es importante conocer las Normas de Codificación como MISRA para C/C++, especialmente en aplicaciones críticas.
- Uso de bibliotecas y herramientas adecuadas: Es importante usar bibliotecas optimizadas y específicas para sistemas embebidos que ya estén probadas y optimizadas. Adicionalmente se deben usar herramientas de análisis estático y dinámico para identificar posibles problemas de eficiencia y seguridad en el código.
- Planificación y Gestión del Tiempo Real: siempre que se pueda se debe considerar el uso de un sistema operativo en tiempo real (RTOS) para gestionar tareas concurrentes y mejorar la eficiencia del tiempo de ejecución. Adicionalmente se pueden asignar prioridades adecuadas a las tareas para asegurar que las más críticas se ejecuten en el momento adecuado.
- Seguridad: Siempre se debe validar las entradas para evitar errores y posibles vulnerabilidades de seguridad. También es importante tener protección de acceso a la memoria, asegurando que el acceso a la memoria esté bien gestionado para evitar desbordamientos y accesos no autorizados.
Optimización de código y codificación eficiente.
A continuación presentaremos algunos ejemplos de optimización de código y codificación eficiente:
1. Uso eficiente de memoria con el uso adecuado de tipos de datos. Usar tipos de datos adecuados puede ahorrar memoria y mejorar el rendimiento.
2. Eliminación de código innecesario o código muerto. Eliminar código que nunca se ejecuta o no es necesario.
3. Optimización de bucles. Minimizar las operaciones dentro de los bucles.
4. Reducción de funciones costosas: Reemplazar operaciones matemáticas costosas con operaciones más eficientes.
5. Uso eficiente de memoria dinámica. Reducir o evitar el uso de malloc y free en sistemas críticos de tiempo real.
6. Optimización de acceso a memoria. Las variables locales son más rápidas de acceder que las variables globales.
7. Optimización de control de flujo. Simplificar las condiciones para mejorar la claridad y la eficiencia.
8. Uso de interrupciones en lugar de polling. Usar interrupciones para manejar eventos en lugar de verificar constantemente el estado.
9. Optimización de Cálculos Repetitivos. Precalcular valores que no cambian dentro de un bucle.
Finalmente entre otras recomendaciones tenemos que se debe seleccionar los tipos de datos (int, char, float, double) más adecuados dependiendo del alcance de las variables y los posibles valores que puedan tomar. Si un apuntador no se va usar para modificar datos declararlo como const (ej. const char *p). En un microcontrolador sin coprocesador matemático o unidad de punto flotante, las operaciones de punto flotante son ineficientes en tiempo de ejecución y uso de memoria, se debe reconsiderar la forma de hacer dichos cálculos. Las constantes de punto flotante por defecto son double, excepto que se las especifique como float. Ejemplo: A += 1.0 // double, contrario a A += 1.0f // float.
PREGUNTA DE COMPRENSIÓN. ¿Cuál es una técnica para mejorar la eficiencia del código en sistemas embebidos?
Programación usando Plano Secundario (Background) / Plano principal (Foreground).
La programación usando plano secundario (background) y plano principal (foreground) es un concepto importante en el desarrollo de aplicaciones, especialmente en aquellas que requieren la ejecución de múltiples tareas simultáneamente, como las aplicaciones de escritorio, móviles y principalmente Sistemas Embebidos. La programación se basa en el Super Loop, sumando el uso de Interrupciones. Así, el código se agrupa en dos segmentos principales: el lazo principal (Main Loop), llamado Plano Secundario o "Background" donde hay operaciones que no requieren un tratamiento en tiempo real; y la sección de rutina(s) de Interrupción, llamado también Plano Principal o "Foreground", donde están las funciones que requieren una operación en tiempo real (tratamiento inmediato) en el sistema.
Plano Principal (Foreground): El plano principal, también conocido como hilo principal o hilo de la interfaz de usuario (UI thread), es donde se ejecutan las tareas que requieren una interacción directa e inmediata con el usuario. Esto incluye la actualización de la interfaz gráfica, la respuesta a eventos de usuario (como clics de botones y entradas de teclado), y cualquier otra operación que necesite una respuesta rápida. Entre otros ejemplos de uso se tiene: la actualización de elementos de la interfaz de usuario, manejo de eventos de usuario, y tareas que deben completarse rápidamente para mantener una experiencia de usuario fluida.
Plano Secundario (Background): El plano secundario se refiere a tareas que se ejecutan fuera del hilo principal. Estas tareas pueden realizarse en hilos separados o procesos separados. Se utilizan para operaciones que son intensivas en tiempo o recursos, y que podrían bloquear o retrasar la interfaz de usuario si se ejecutan en el hilo principal. Entre otros ejemplos de uso se tiene operaciones de entrada/salida (I/O) como la lectura/escritura de archivos, solicitudes de red, cálculos complejos, y otras tareas que pueden tardar en completarse.
Dentro de las ventajas de usar este tipo de programación se tiene la responsividad que quiere decir que mantener las operaciones intensivas en el plano secundario asegura que la interfaz de usuario permanezca responsiva. También se logra eficiencia, porque se logra que el sistema utilice mejor los recursos de hardware, como los núcleos de CPU disponibles. Adicionalmente se logra que los usuarios perciban una experiencia más fluida y sin interrupciones.
Dentro de las desventajas de usar este tipo de programación se tiene que introducir la programación en múltiples hilos aumenta la complejidad del código y puede llevar a errores difíciles de depurar, como condiciones de carrera (race conditions) y bloqueos (deadlocks). Otro reto tiene que ver con asegurar que los hilos secundarios se sincronicen correctamente con el hilo principal, algo que puede ser complicado.
Código de Ejemplo:
Super Loop: Este código muestra cómo realizar dos tareas usando un super loop. Una tarea se ejecuta cada 500 ms y la otra cada 1000 ms.
unsigned long lastTask1Time = 0;
unsigned long lastTask2Time = 0;
void setup() {
Serial.begin(9600);
Serial.println("Super Loop Example");
}
void loop() {
unsigned long currentMillis = millis();
// Tarea 1: Ejecutar cada 500 ms
if (currentMillis - lastTask1Time >= 500) {
Serial.println("Task 1 running...");
lastTask1Time = currentMillis;
}
// Tarea 2: Ejecutar cada 1000 ms
if (currentMillis - lastTask2Time >= 1000) {
Serial.println("Task 2 running...");
lastTask2Time = currentMillis;
}
// Otras tareas del loop pueden ir aquí...
}Explicación del Código:
- Variables de Tiempo: lastTask1Time y lastTask2Time se utilizan para registrar el último momento en que se ejecutaron las tareas.
- Setup: Inicializa el puerto serie para la depuración.
- Loop: Comprueba si han pasado 500 ms desde la última ejecución de la tarea 1 y, de ser así, ejecuta la tarea. Comprueba si han pasado 1000 ms desde la última ejecución de la tarea 2 y, de ser así, ejecuta la tarea.
Interrupciones: Este código muestra cómo realizar las mismas dos tareas utilizando interrupciones. La tarea 1 se maneja mediante el temporizador 1, y la tarea 2 se maneja mediante el temporizador 2.
#include <TimerOne.h>
#include <TimerThree.h>
volatile bool task1Flag = false;
volatile bool task2Flag = false;
void setup() {
Serial.begin(9600);
Serial.println("Interrupts Example");
// Configurar Timer1 para disparar cada 500 ms (0.5 s)
Timer1.initialize(500000); // 500,000 microsegundos = 0.5 segundos
Timer1.attachInterrupt(task1ISR);
// Configurar Timer3 para disparar cada 1000 ms (1 s)
Timer3.initialize(1000000); // 1,000,000 microsegundos = 1 segundo
Timer3.attachInterrupt(task2ISR);
}
void loop() {
// Comprobar si la tarea 1 ha sido disparada
if (task1Flag) {
task1Flag = false;
Serial.println("Task 1 running...");
}
// Comprobar si la tarea 2 ha sido disparada
if (task2Flag) {
task2Flag = false;
Serial.println("Task 2 running...");
}
// Otras tareas del loop pueden ir aquí...
}
// ISR para la tarea 1
void task1ISR() {
task1Flag = true;
}
// ISR para la tarea 2
void task2ISR() {
task2Flag = true;
}Explicación del Código:
- Flags Volátiles: task1Flag y task2Flag son variables volátiles utilizadas para indicar si una tarea debe ejecutarse.
- Setup: Inicializa el puerto serie para la depuración. Configura los temporizadores 1 y 3 para disparar las interrupciones cada 500 ms y 1000 ms, respectivamente.
- Loop: Comprueba las banderas task1Flag y task2Flag y ejecuta las tareas correspondientes si las banderas están activadas.
- ISRs (Interrupt Service Routines): task1ISR() y task2ISR() son las rutinas de servicio de interrupción que se ejecutan cuando los temporizadores disparan. Estas funciones simplemente establecen las banderas para indicar que las tareas deben ejecutarse.
Una forma de comprender el concepto es validar el funcionamiento de ambos códigos y hacer una estadística del funcionamiento y tiempos de las dos tareas; comparando desempeño.
Programación usando Máquinas de estado finitas (MEF) o autómatas finitos.
La programación usando máquinas de estado finitas (MEF) o autómatas finitos es una técnica muy útil para manejar sistemas que tienen una serie de estados definidos y transiciones entre esos estados basadas en eventos o condiciones.
Una máquina de estado finito (MEF) es un modelo de comportamiento compuesto por:
- Estados: diferentes condiciones/momento en las que el sistema puede estar.
- Transiciones: reglas que determinan cómo y cuándo el sistema pasa de un estado a otro.
- Eventos/Condiciones: circunstancias que desencadenan transiciones de estado.
- Acciones: operaciones que se llevan a cabo cuando se entra o se sale de un estado, o durante una transición. De hecho normalmente las acciones ocurren dentro de cada estado, lo que simplifica su lógica de implementación.
Ejemplo de Máquina de Estado Finito:
Condideremos un semáforo con tres estados (verde, amarillo, rojo) y transiciones basadas en el tiempo.
+-------+
| Verde |
+-------+
|
v
+--------+
| Amarillo|
+--------+
|
v
+-------+
| Rojo |
+-------+
|
v
+-------+
| Verde |
+-------+Definición de estados: primero, se definen los estados del semáforo como una enumeración (enum) para mayor claridad y facilidad de uso.
enum TrafficLightState {
GREEN,
YELLOW,
RED
};Variables globales y temporizadores: se declaran las variables necesarias para el estado actual del semáforo y los temporizadores para controlar las transiciones.
- currentState mantiene el estado actual del semáforo.
- stateStartTime guarda el tiempo en que el estado actual comenzó.
- greenDuration, yellowDuration y redDuration especifican la duración de cada estado.
TrafficLightState currentState = GREEN; // Estado inicial del semáforo
unsigned long stateStartTime = 0; // Tiempo en que el estado actual comenzó
const unsigned long greenDuration = 5000; // Duración del verde en milisegundos
const unsigned long yellowDuration = 2000; // Duración del amarillo en milisegundos
const unsigned long redDuration = 5000; // Duración del rojo en milisegundosConfiguración inicial: En la función setup(), inicializamos los pines de salida y se establece el estado inicial.
- Inicialización del puerto serie para depuración.
- Configuración del pin del LED integrado como salida.
- Establecimiento del estado inicial y el tiempo de inicio.
void setup() {
Serial.begin(9600);
pinMode(LED_BUILTIN, OUTPUT); // Utilizamos el LED integrado para indicar el estado (en un semáforo real, utilizarías varios pines)
currentState = GREEN; // Comenzamos en el estado verde
stateStartTime = millis(); // Guardamos el tiempo de inicio del estado
}Función para manejar estados: Se crea una función para manejar las transiciones de estado y las acciones asociadas.
- En la función handleState(), se utiliza un switch para manejar cada estado.
- En cada caso del switch, se verifica si el tiempo transcurrido ha superado la duración del estado actual.
- Si ha transcurrido suficiente tiempo, se cambia al siguiente estado y se actualiza stateStartTime.
void handleState() {
unsigned long currentTime = millis(); // Obtenemos el tiempo actual
switch (currentState) {
case GREEN:
digitalWrite(LED_BUILTIN, HIGH); // Encender LED (simbolizando verde)
if (currentTime - stateStartTime >= greenDuration) {
currentState = YELLOW; // Transición a amarillo
stateStartTime = currentTime; // Actualizamos el tiempo de inicio del nuevo estado
}
break;
case YELLOW:
digitalWrite(LED_BUILTIN, LOW); // Apagar LED (simbolizando amarillo)
if (currentTime - stateStartTime >= yellowDuration) {
currentState = RED; // Transición a rojo
stateStartTime = currentTime; // Actualizamos el tiempo de inicio del nuevo estado
}
break;
case RED:
digitalWrite(LED_BUILTIN, LOW); // Apagar LED (simbolizando rojo)
if (currentTime - stateStartTime >= redDuration) {
currentState = GREEN; // Transición a verde
stateStartTime = currentTime; // Actualizamos el tiempo de inicio del nuevo estado
}
break;
}
}Bucle/ciclo principal: en el bucle principal (loop()), simplemente se llama a la función handleState() repetidamente para manejar las transiciones y acciones.
void loop() {
handleState();
}Entre otras ventajas de usar máquinas de estado finitas (MEFs) está que se tiene un código más entendible lo que lleva a la minimización del código espagueti. Cada estado "guarda memoria", o es una "instantánea" de eventos y estados pasados. Las MEFs reducen la cantidad de variables globales y banderas en el código. Sin embargo, las MEFs no son apropiadas para todas las aplicaciones. Las siguientes son las desventajas del uso de MEFs:
- Complejidad creciente: a medida que el sistema crece en complejidad, el número de estados y transiciones puede aumentar exponencialmente. Esto puede hacer que la MEF sea difícil de mantener y entender. Además, un diagrama de estado muy complejo puede ser difícil de visualizar y manejar, lo que puede llevar a errores y dificultades en el desarrollo y mantenimiento.
- Escalabilidad limitada: para sistemas con un gran número de estados y condiciones, las MEF pueden volverse inmanejables. La gestión de muchas transiciones y estados puede requerir una lógica de control muy compleja. Por otro lado, las interacciones complejas entre múltiples estados y sub-estados pueden hacer que la lógica de la MEF sea difícil de implementar y depurar.
- Mantenimiento y evolución: cambiar la lógica de estados o añadir nuevos estados y transiciones puede ser complicado y propenso a errores, especialmente en sistemas grandes y complejos. Para asegurar que el sistema sea comprensible y mantenible, se necesita una documentación rigurosa y actualizada del diagrama de estado y sus transiciones.
- Consumo de recursos: en sistemas embebidos con recursos limitados (como memoria y procesamiento), una MEF muy grande puede consumir más recursos de los disponibles. La implementación de MEF puede añadir un overhead adicional en términos de memoria y tiempo de ejecución, lo cual puede ser crítico en sistemas con recursos restringidos.
Las MEF no son adecuadas en sistemas donde la lógica es lineal o secuencial y no requiere cambios de estado complejos, las MEF pueden ser innecesarias y añadir complejidad innecesaria. Tampoco son útiles en tareas que implican procesamiento de datos complejo, como algoritmos de inteligencia artificial o procesamiento de señales, o en sistemas altamente basados en eventos o con procesamiento paralelo/concurrente.
Programación usando planificadores de tareas (task schedulers).
La programación usando planificadores de tareas (task schedulers) es una técnica utilizada para gestionar la ejecución de múltiples tareas en sistemas embebidos y otros sistemas donde es necesario coordinar y optimizar el uso de recursos. Los planificadores de tareas permiten ejecutar tareas de manera periódica, basada en eventos, o en función de prioridades, sin necesidad de intervención manual constante.
Un planificador de tareas es un componente del sistema operativo o un módulo en un sistema embebido que gestiona la ejecución de varias tareas (o procesos). El planificador decide qué tarea ejecutar y cuándo, en función de un conjunto de reglas y prioridades.
Características Principales:
- Multiprogramación: permite que múltiples tareas se ejecuten aparentemente al mismo tiempo, aunque realmente se alternen en el uso del procesador.
- Prioridades: asigna diferentes niveles de prioridad a las tareas para garantizar que las tareas críticas se ejecuten primero.
- Gestión del tiempo: ejecuta tareas en intervalos regulares o en momentos específicos, garantizando una distribución eficiente del tiempo de CPU.
- Sincronización: coordina la ejecución de tareas para evitar conflictos y asegurar la correcta secuencialidad.
Tipos de planificadores de tareas: Se pueden identificar varios tipos de programadores de tareas. En general se puede hablar de:
- Planificadores cooperativos: Las tareas se ejecutan hasta que ellas mismas deciden ceder el control. Tiene menor overhead y son fáciles de implementar, pero menos control sobre el tiempo de ejecución de cada tarea.
- Planificadores preemptivos: El planificador puede interrumpir una tarea en ejecución para ceder el control a otra tarea más prioritaria. Proporciona mejor control sobre el tiempo de ejecución y permite una respuesta más rápida a eventos críticos.
Como se conoce, una CPU tradicional solo puede ejecutar un programa a la vez. La aparente ejecución simultánea de múltiples subprocesos o tareas se logra mediante el intercambio rápido del control de la CPU entre varios subprocesos de código. Este proceso de intercambio lo gestiona el planificador. Llevar a cabo ese intercambio del control se puede hacer de las siguientes maneras específicas:
- Planificador ejecutar hasta completar (Run to Completion RTC): Es el planificador más simple. La idea es que una tarea se ejecute hasta que haya completado su trabajo y luego finalice. Luego, la siguiente tarea se ejecuta de manera similar; y así sucesivamente hasta que se hayan ejecutado todas las tareas, momento en que la secuencia comienza de nuevo. De hecho lo anteriormente descrito es un Super Loop. La facilidad de este esquema tiene en contrapeso el inconveniente de que la asignación de tiempo de cada tarea se ve totalmente afectada por todas las demás. El sistema no será muy determinista, pero para algunas aplicaciones, esto es suficiente. Un nivel adicional de sofisticación podría ser el soporte para la suspensión de tareas, lo que significa que una o más tareas pueden excluirse de la secuencia de ejecución hasta que se requieran nuevamente.

[Representación planificador: Run to completion RTC.]
- Planificador todos contra todos (Round robin RR): Un planificador RR es el siguiente nivel de complejidad. Las tareas se ejecutan en secuencia de la misma manera (con la posibilidad de suspender una tarea), excepto que una tarea no necesita completar su trabajo, simplemente cede la CPU cuando es conveniente hacerlo. Cuando se programa nuevamente, continúa desde donde lo dejó. Cuando una tarea cede la CPU, su contexto (valores de registros de la máquina) debe guardarse para poder restaurarlo la próxima vez que se programe la tarea. Al igual que con RTC, un planificador RR depende de que cada tarea se comporte bien y no permanezca en el procesador por mucho tiempo. Tanto RTC como RR son "multitarea cooperativa".

[Representación planificador: Round Robin RR.]
- Planificador intervalo de tiempo (Time slice TS): Un programador TS es un ejemplo sencillo de "multitarea preventiva". La idea es dividir el tiempo en "intervalos", cada uno de los cuales podría ser típicamente 1 ms. Cada tarea se ejecuta en uno de esos espacios de tiempo. Al final del tiempo asignado, se interrumpe y se ejecuta la siguiente tarea. La programación ahora no depende de que las tareas previamente sean bien planeadas para ejecutarse en tiempos establecidos , ya que la utilización del tiempo se gestiona de manera justa. Un sistema construido con un programador TS puede ser completamente determinista (es decir, predecible). A esta técnica puede llamársele tiempo real.

[Representación planificador: Time Slice TS.]
- Planificador intervalo de tiempo con tarea en segundo plano (Time slice with background task TSBG): Aunque un planificador TS es claro y ordenado, existe un problema. Si una tarea descubre que no tiene trabajo que hacer, su única opción es realizar un ciclo (quemando tiempo de CPU) hasta que pueda hacer algo útil. Esto significa que podría desperdiciar una proporción significativa de su espacio y un número indefinido de espacios adicionales. Claramente, la tarea podría suspenderse (para ser reactivada nuevamente cuando sea necesario), pero esto altera el tiempo de las otras tareas. Esto compromete el determinismo del sistema. Una solución es mejorar el programador para que, si una tarea se suspende, el resto de su espacio sea ocupado por una "tarea en segundo plano (background BG)"; esta tarea también utilizará los espacios completos de cualquier tarea suspendida. Esto restaura la integridad de la sincronización. Lo que realmente hace la tarea en segundo plano depende de la aplicación, pero en términos generales debe ser un código que no requiera tiempo crítico, como una autoprueba, autocalibración o cálculo sencillo. Por supuesto, existe la posibilidad de que la tarea en segundo plano nunca se programe. Además, esta tarea especial no puede suspenderse.

[Representación planificador: Time Slice with Background task TSBG.]
- Planificador con prioridades (Priority PRI): un esquema de programación común y más sofisticado es con prioridades PRI, que se utiliza en muchos de los sistemas RTOS comerciales. La idea es que cada tarea tenga una prioridad y esté lista para ser ejecutada o suspendida. El planificador ejecuta la tarea con la mayor prioridad que esté lista. Cuando esa tarea se suspende, ejecuta la que tiene la siguiente prioridad más alta. Si ocurre un evento que puede haber preparado una tarea de mayor prioridad, se ejecuta el planificador. Aunque es más complejo, un planificador PRI ofrece mayor flexibilidad para muchas aplicaciones.
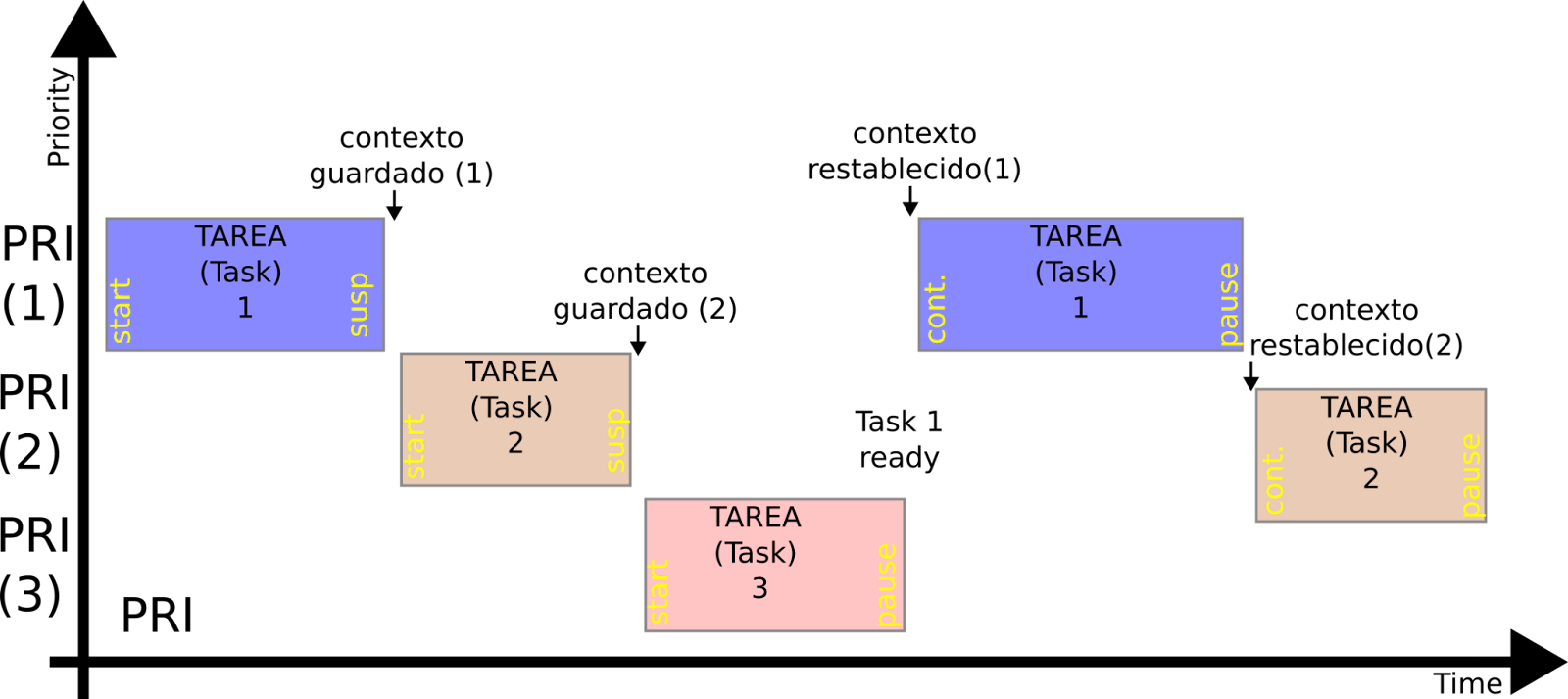
[Representación planificador: Priority PRI.]
Ventajas del Uso de Planificadores de Tareas
- Mejor gestión del tiempo: las tareas se ejecutan en momentos específicos o en intervalos regulares, garantizando una distribución eficiente del tiempo de CPU.
- Flexibilidad: Es fácil añadir, eliminar o modificar tareas sin afectar significativamente el flujo del programa principal.
- Modularidad: El código para cada tarea se puede mantener por separado, facilitando la organización y el mantenimiento del programa.
- Prioridades y control: Los planificadores permiten asignar prioridades a las tareas, garantizando que las tareas más críticas se ejecuten primero.
PREGUNTA DE COMPRENSIÓN. ¿Cuál es el principal desafío al implementar un planificador de tareas basado en prioridades en un sistema embebido?
Un Sistema operativo en tiempo real (RTOS) es un tipo de Sistema Operativo (SO), ligero, diseñado para ejecutar aplicaciones multiproceso (multi-threaded) y garantizar la ejecución de tareas dentro de plazos de tiempo específicos (real-time deadlines). La mayoría de los RTOS incorporan un planificador de tareas (scheduler), administración de recursos (resource management) y controladores para los dispositivos (device drivers). Cuando se habla de "plazos", no necesariamente se refiere "velocidad" o "rapidez", sino a la capacidad de cumplir ciertos tiempos con un alto grado de determinismo, lo que significa que se puede prever el momento en que se deben ejecutar todas las tareas para que el resultado sea el esperado.
Sistema Operativo de Propósito General (GPOS) vs Sistema Operativo en Tiempo Real (RTOS).
Cuando se habla de "Sistemas Operativos" (SOs), se piensa en sistemas como Windows, macOS y Linux, que realmente son alternativas de Sistemas Operativos de Propósito General (GPOS). Estos Sistemas Operativos están diseñados principalmente para interactuar con el usuario y proporcionan algún tipo de interfaz por línea de comandos (CLI) o una interfaz gráfica de usuario (GUI). Adicionalmente estos Sistemas Operativos tienen la capacidad de ejecutar múltiples aplicaciones o tareas, a menudo con múltiples subprocesos. También permiten ejecutar funcionalidades adicionales como la gestión de recursos y archivos, así como controladores de dispositivos. Dado que los (GPOS) están principalmente diseñados para interactuar con el usuario, se permite cierto nivel de latencia o retardo (siempre que los usuarios no experimenten demoras significativas). Esto hace que sea muy difícil predecir con precisión los plazos exactos de ejecución de tareas.
[Representación Sistema Operativo de Propósito General (GPOS). Creado por ChatGPT de OpenAI, 2024]
Comparado con un Sistema Operativo en Tiempo Real (RTOS), la mayoría de los RTOS están diseñados para funcionar en microcontroladores o dispositivos con menos recursos de procesamiento y memoria. Esto significa que normalmente no se necesitan interfaces de usuario complejas, como líneas de comandos o interfaces gráficas, ya que están diseñados para realizar tareas muy específicas; a la vez; sin requerir necesariamente interacción del usuario. Las aplicaciones desarrolladas para microcontroladores pueden tener plazos estrictos que deben cumplirse, como accionar un actuador cada cierto tiempo específico, controlar dispositivos de tráfico para mantener orden y evitar caos o activar mecanismos específicos en una planta de distribución.

[Representación Sistema Operativo en Tiempo Real (RTOS). Creado por ChatGPT de OpenAI, 2024]
Varias alternativas de RTOS incluyen bibliotecas de gestión de recursos que permiten operaciones como lectura y escritura de archivos, así como controladores para dispositivos de bajo nivel, como controladores de protocolos de comunicaciones de red, WiFi y Bluetooth y controladores para interfaces de visualización como pantallas o LCDs. Es importante señalar que los controladores de dispositivos en un RTOS suelen ser mucho más simples que los que se encuentran en un GPOS, ya que los microcontroladores generalmente no se utilizan para tareas como por ejemplo controlar tarjetas gráficas o manejar varias alternativas de almacenamiento como memorias usb, discos duros etc.
PREGUNTA DE COMPRENSIÓN. ¿Cuál es la diferencia principal entre un sistema operativo de propósito general (GPOS) y un sistema operativo en tiempo real (RTOS) en términos de manejo de tareas?
Super Loop vs Multiproceso.
Típicamente una aplicación embebida desarrollada en plataformas como Arduino utilizan la estrategia de programar usando un Ciclo Infinito (Super Loop). Este tipo de programación básica no usa un sistema operativo o librerías que de alguna manera organicen la ejecución en tiempo de las funciones o tareas del sistema. Por el contrario, de forma sencilla dentro de una función principal llamada main(), se configuran variables, funciones/tareas de controladores, bibliotecas, etc., y luego ejecuta una o más tareas de forma periódica/secuencial dentro de un ciclo while (true); sin control del tiempo dedicado a ejecutar cada tarea. En el caso específico de Arduino, esto se implementa mediante las funciones setup() y loop().
El tiempo en que se desarrolla el programa depende entonces del tiempo propio que tarda cada tarea en ejecutarse sumado al tiempo de ejecución de las demás tareas. Esto quiere decir que a medida que aumentamos la cantidad de tareas, aumentamos el tiempo en que cualquiera de las tareas se ejecuta. Esto con pocas tareas puede no ser un inconveniente, pero a medida que la cantidad de tareas aumenta, el retardo para volver a ejecutar cada una de ellas va a ser muy significativo. Por esto se deben plantear alternativas para sistemas con más tareas o una funcionalidad mayor.
El uso de estructuras de programación del tipo Ciclo Infinito (Super Loop) sigue siendo una de las formas más populares de programar un microcontrolador debido a su facilidad de implementación y depuración. Adicionalmente es posible incorporar interrupciones utilizando rutinas de servicio de interrupción (ISR) que detienen la ejecución del programa principal y ejecutan un código específico cuando se produce un evento externo, como la finalización de un temporizador, la pulsación de un botón o información de algún sensor.
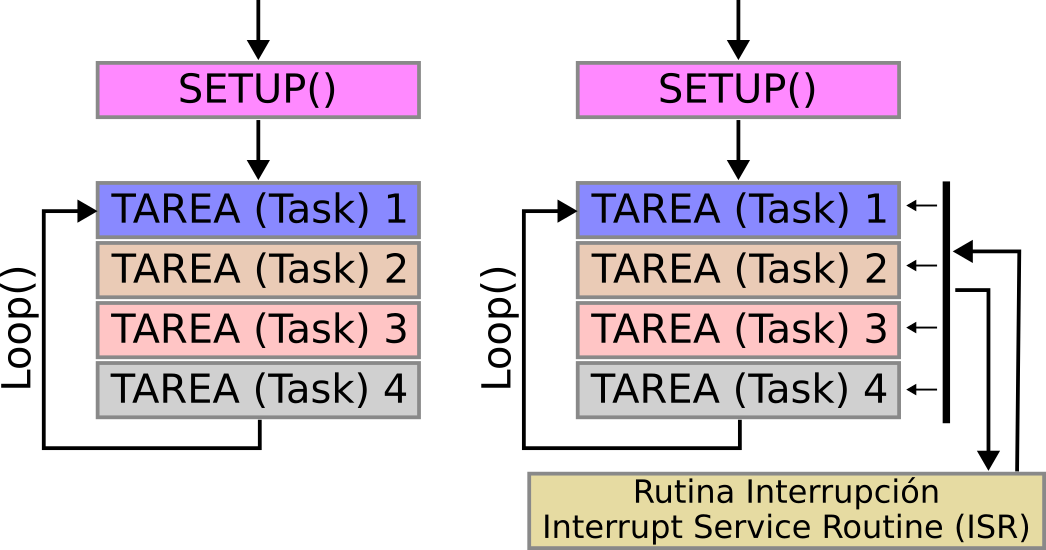
[Representación programación usando Super Loop sin y con Rutina de Interrupción.]
Así, cuando aumentan las funciones o tareas al ciclo principal que se ejecuta de forma circular (round-robin), se debe pensar en otro tipo de estructura de programación. Entre más tareas puede pasar que algunas de ellas incumplan sus plazos/tiempos o interfieran con el funcionamiento de otras.
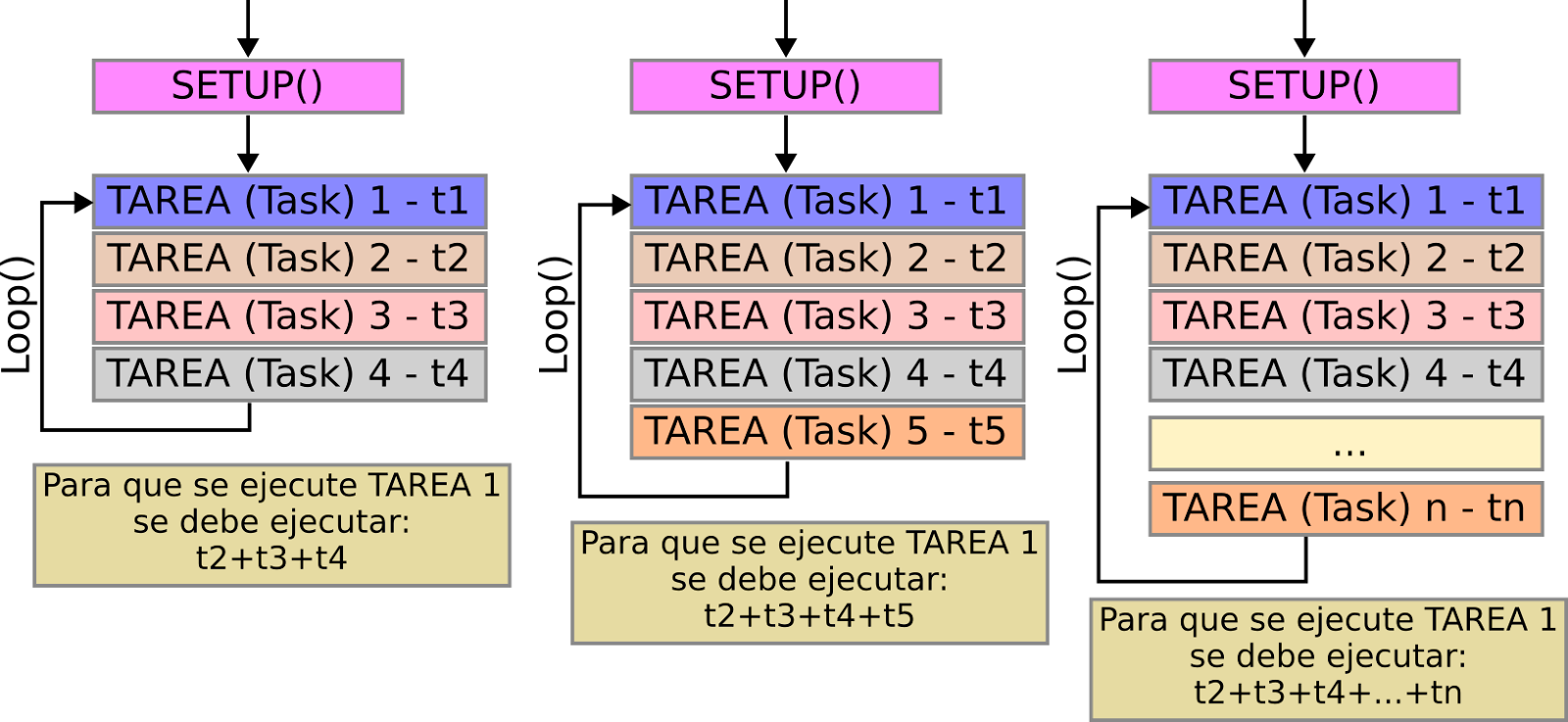
[Representación programación usando Super Loop a medida que aumentan las tareas que ejecuta el sistema.]
Acá es donde un Sistema Operativo en tiempo real (RTOS) puede resultar de mucha ayuda. En lugar de ejecutar todas las tareas de forma secuencial, un RTOS permite ejecutarlas prácticamente de forma simultánea o concurrente, o por lo menos dar la sensación de que ocurre de esta manera. Cada tiempo de ejecución de una tarea puede estar limitado, y no necesariamente se debe esperar a que una tarea se ejecute por completo. A medida que el sistema asigna recursos para ejecutar cada tarea, el sistema puede retomar la ejecución de una tarea que se venía ejecutando. Con un RTOS aún puede haber interrupciones, que detendrían cualquier tarea que se estuviera ejecutando en determinado momento para ejecutar el servicio de interrupción (ISR) y luego volver a la ejecución de la tarea antes de ser llamada la interrupción.
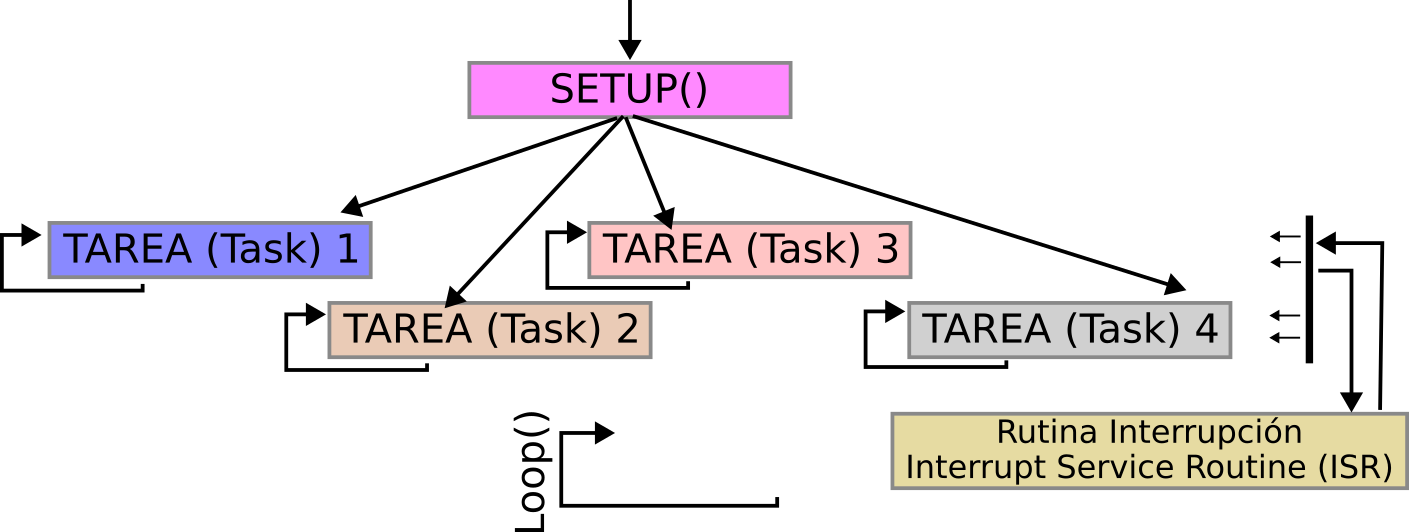
[Representación programación usando RTOS.]
Una tarea (task) se refiere a un conjunto de instrucciones almacenadas en memoria, o puede referirse a una unidad de trabajo o un objetivo específico que debe lograrse. FreeRTOS utiliza el término tarea (task) para hacer referencia a lo que generalmente se conoce como subprocesos (threads) (unidad de utilización de la unidad central de procesamiento (CPU) que cuenta con su propio contador de programa y memoria de pila). Por lo tanto se usa el término tareas (tasks) para describir las unidades de utilización de CPU. Las tareas son similares a los hilos (threads) en otros entornos (frameworks), como por ejemplo el modelo POSIX (conjunto de estándares definidos por el IEEE que especifica una interfaz estándar para sistemas operativos).
Similitudes entre Tareas en FreeRTOS y Hilos en POSIX
- Concurrencia: tanto las tareas en FreeRTOS como los hilos en un sistema operativo basado en POSIX permiten la concurrencia dentro de una aplicación. Permiten que múltiples flujos de control operen de manera pseudo-paralela (en un núcleo) o en paralelo real (en múltiples núcleos).
- Planificación (Scheduling): las tareas y los hilos son gestionados por un planificador que decide cuándo debe ejecutarse cada unidad de ejecución. Tanto FreeRTOS como los sistemas POSIX pueden usar planificadores preemptivos, lo que significa que una tarea o hilo de mayor prioridad puede interrumpir a otro de menor prioridad que está en ejecución.
- Prioridades: ambos modelos permiten la asignación de prioridades a las tareas o hilos, lo que afecta el orden de ejecución según la importancia o urgencia definida por el desarrollador.
- Sincronización y Comunicación: tanto en FreeRTOS como en POSIX, existen mecanismos para la sincronización y comunicación entre tareas o hilos, como semáforos, mutexes, colas de mensajes, etc.
Cuando se necesitan ejecutar múltiples tareas o procesos en un microcontrolador se puede utilizar un RTOS. La importancia de cumplir con los plazos en tiempo real puede variar según la aplicación. Si no requiere la ejecución de múltiples subprocesos (threads), puede ser más conveniente seguir utilizando la arquitectura de Ciclo Infinito (Super Loop), ya que resulta mucho más sencilla para la depuración y verificación del código. Pero, por otro lado, si se necesita usar múltiples subprocesos (threads), un RTOS resulta ser una buena alternativa. El RTOS permite modularizar el código de manera más eficiente, ya que las tareas (tasks) pueden escribirse de manera independiente. Esto facilita la asignación de tareas individuales a diferentes miembros de un equipo de desarrollo, lo que permite el trabajo concurrente. Sin embargo, es importante tener en cuenta que siempre será necesario realizar pruebas y depuración al final del proceso para garantizar una integración adecuada de todas las tareas.
En términos generales, un RTOS hace referencia a un conjunto de librerías lo que significa que se requiere de cierta sobrecarga, ya que se debe ejecutar una tarea en segundo plano (el planificador de tareas scheduler) de forma regular para cambiar/alternar de tarea. Esto ocupa memoria y algunos ciclos de CPU. Como resultado, muchos RTOS tienen requisitos mínimos de velocidad de reloj y memoria para funcionar adecuadamente.
Hardware necesario para ejecutar un RTOS.
En teoría, se puede ejecutar alguna versión de RTOS en un Arduino UNO (ATmega 328p). Sin embargo la sobrecarga del planificador de tareas (scheduler) es tan grande que no quedan muchos recursos (memoria) para la propia aplicación. Debido a esto, los microcontroladores de 8 y 16 bits se utilizan mejor con la arquitectura más simple de Ciclo Infinito (Super Loop). Con microcontroladores de 32 bits más potentes y con relojes más rápidos (por ejemplo, más de 20 MHz) y más memoria (por ejemplo, más de 32 kB de RAM), se pueden tener recursos disponibles para ejecutar un RTOS; sin embargo, cada alternativa de RTOS requiere diferente cantidad de recursos.
En estos tutoriales usaremos la ESP32, que tiene un reloj de 240 MHz, 520 kB de RAM y 2 núcleos. Debido a que fue diseñado como un sistema de Internet de las cosas (IoT), el ESP32 se beneficia de un RTOS. De hecho, la versión Arduino del ESP32 admite FreeRTOS. Las pilas de WiFi y Bluetooth por sí solas necesitan un RTOS, ya que deben ejecutarse simultáneamente con la aplicación del usuario para que puedan responder a las solicitudes de la red en el tiempo requerido.

[Comparación Arduino vs ESP32.]
Alternativas de RTOS.
El artículo de Circuit Digest compara varios sistemas operativos populares de IoT destacando sus principales características y aplicaciones para diferentes necesidades en el ámbito de los sistemas embebidos. En resumen se presenta que:
- RIOT OS: Es un sistema operativo de código abierto que se destaca por su poco uso de memoria y su compatibilidad con una gran variedad de microcontroladores. Está diseñado especialmente para dispositivos IoT de bajo consumo.
- Zephyr: Respaldado por "Linux Foundation". Este sistema operativo funciona en múltiples arquitecturas de hardware y está diseñado para lograr una buena conectividad, admitiendo tecnologías como Bluetooth LE y Wi-Fi.
- Apache Mynewt: Este OS es ideal para el desarrollo de aplicaciones IoT gracias a su bajo uso de memoria del kernel y su soporte para conectividad Bluetooth.
- FreeRTOS: Ampliamente utilizado en proyectos comerciales y no comerciales, se reconoce por sus requisitos mínimos de memoria y sus sólidas características de seguridad, lo que lo hace adecuado para una variedad de arquitecturas de microcontroladores.
- Mbed OS: Soporta microcontroladores ARM Cortex-M de 32 bits y es preferido por su completo soporte de pilas de protocolos y características de seguridad.
- Contiki-NG: Orientado a microcontroladores de bajo consumo, opera eficazmente con varios protocolos de internet y proporciona soporte para conjuntos de protocolos estándar inalámbricos.
Cada uno de estos sistemas operativos ofrece características y beneficios únicos adaptados a diferentes aspectos del desarrollo de IoT, desde el control simple de dispositivos hasta soluciones en red a gran escala. La elección del sistema operativo generalmente depende de los requisitos específicos del proyecto, incluyendo el nivel de seguridad necesario, las opciones de conectividad y el hardware utilizado.
¿Por qué utilizar un RTOS?
Un sistema operativo en tiempo real (RTOS) proporciona una programación basada en prioridades que permite separar el procesamiento esencial del no crítico. Esto se logra a través de funciones de API que simplifican y reducen el código de la aplicación. Al abstraer las dependencias de tiempo y adoptar un diseño basado en tareas, se minimizan las interdependencias entre los distintos módulos del sistema. Además, el desarrollo modular basado en tareas facilita las pruebas modulares, ya que cada tarea suele tener una función claramente definida. Esto permite que los diseñadores y equipos trabajen de forma independiente en sus respectivas partes del proyecto. Un RTOS se rige por eventos, sin desperdiciar tiempo de procesamiento en eventos que no ocurren.
Algunas aplicaciones donde vale la pena usar un RTOS.
- Sistema de reservas de aerolíneas y Sistema de control de tráfico aéreo.
- Sistemas que proporcionan actualización inmediata.
- Sistema que proporcione información actualizada y minuciosa sobre los precios de las acciones.
- Sistemas de aplicación de defensa como radares.
- Sistemas de control de comando.
- Sistemas de frenos antibloqueo.
- Sistemas de control de vehículos.
- Dispositivos médicos.
- Instrumentación científica.
Desventajas de los RTOS.
Aquí se presentan las desventajas de utilizar un sistema operativo en tiempo real (RTOS):
- Limitación en la ejecución de tareas: Un RTOS se enfoca en un conjunto limitado de tareas críticas y se concentra en corregir errores cuando ocurren. Esto puede dificultar la gestión de múltiples tareas concurrentes.
- Complejidad para la multitarea: Debido a su enfoque en tareas específicas, los RTOS pueden tener dificultades para realizar multitareas eficientemente, lo que puede limitar su capacidad para gestionar una amplia gama de aplicaciones simultáneamente.
- Necesidad de controladores específicos: Para lograr tiempos de respuesta rápidos en la gestión de interrupciones, los RTOS a menudo requieren controladores específicos, lo que agrega complejidad y costos al sistema.
- Consumo de recursos elevado: Los RTOS tienden a utilizar una cantidad significativa de recursos del sistema, lo que puede aumentar los costos y no siempre es adecuado para sistemas con recursos limitados.
- Espera para tareas de baja prioridad: Las tareas de baja prioridad pueden experimentar largos tiempos de espera, ya que los RTOS se centran en mantener la precisión del programa en ejecución.
- Cambios de tareas mínimos: Los RTOS realizan cambios mínimos de tareas, lo que puede dificultar la administración eficiente de múltiples tareas concurrentes.
- Algoritmos complejos: Los RTOS utilizan algoritmos complejos para la planificación y el control de tareas, lo que puede resultar difícil de entender y depurar.
- Requisitos de recursos variables: El alto consumo de recursos por parte de los RTOS puede no ser adecuado para todos los sistemas, especialmente aquellos con limitaciones de recursos.
Multitarea versus concurrencia
Un sistema operativo multitarea puede crear la ilusión de ejecución simultánea al cambiar rápidamente entre tareas, aunque un procesador de un solo núcleo sólo puede ejecutar una tarea a la vez. En el siguiente diagrama se muestra el patrón de ejecución de cuatro tareas con respecto al tiempo. Los nombres de las tareas están codificados por colores. El tiempo va de izquierda a derecha y las líneas de colores muestran qué tarea se está ejecutando en un momento determinado. El diagrama superior demuestra el patrón de ejecución concurrente percibido y el inferior el patrón de ejecución multitarea real.
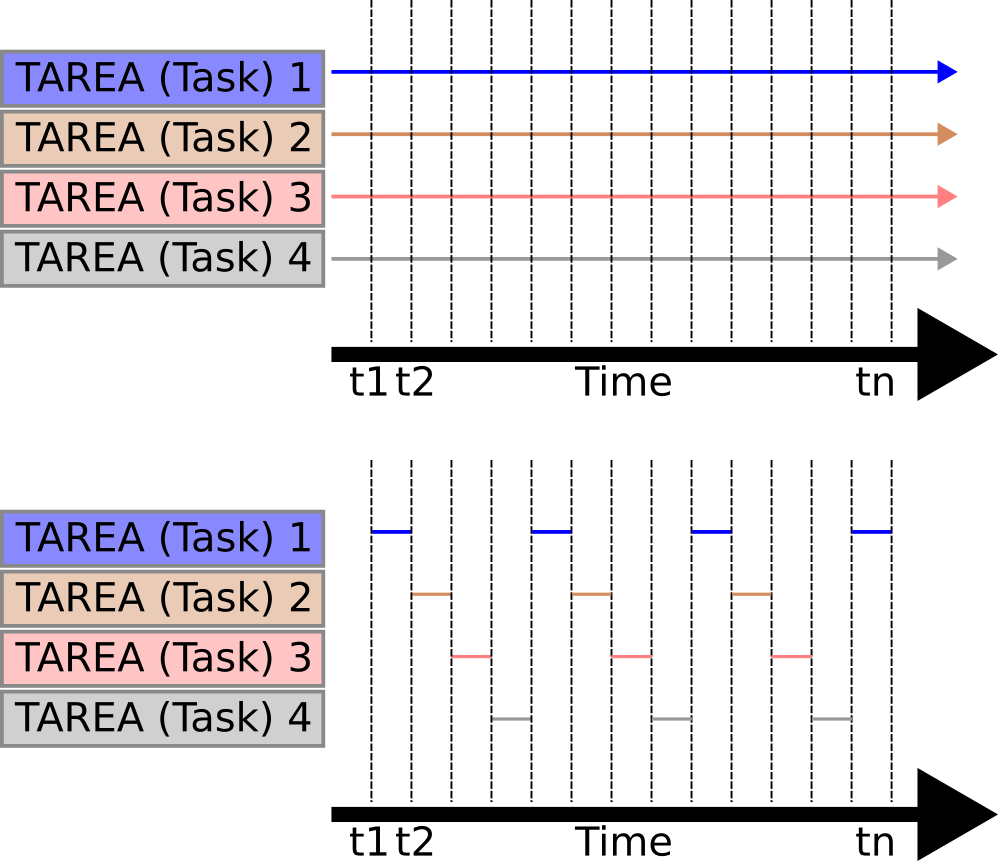
[Representación multitarea vs concurrencia.]
PREGUNTA DE COMPRENSIÓN. ¿Cuál es una ventaja de utilizar un RTOS en sistemas embebidos?
A continuación tienes realimentación a las preguntas de comprensión. Tus respuestas no quedan almacenadas, solo se busca hacer una reflexión sobre la lectura.
PREGUNTA DE COMPRENSIÓN. ¿Cuál es una técnica para mejorar la eficiencia del código en sistemas embebidos?
- Correcta: Precalcular valores constantes fuera de los bucles, porque esto puede mejorar la eficiencia del tiempo de ejecución. Respecto a variables globales y locales, las variables locales suelen ser más eficientes. Los bucles anidados complejos pueden disminuir la eficiencia y las interrupciones pueden mejorar la eficiencia en el manejo de eventos.
PREGUNTA DE COMPRENSIÓN. ¿Cuál es el principal desafío al implementar un planificador de tareas basado en prioridades en un sistema embebido?
- Correcta: Asignar prioridades adecuadas y gestionar la preemption lo cual es uno de los principales desafíos en sistemas de tiempo real.. Aunque determinar la duración exacta de cada tarea es importante, no es el desafío principal. Igualmente aunque reducir el consumo de RAM es relevante, no es el principal desafío relacionado con la planificación de tareas basada en prioridades.
PREGUNTA DE COMPRENSIÓN. ¿Cuál es la diferencia principal entre un sistema operativo de propósito general (GPOS) y un sistema operativo en tiempo real (RTOS) en términos de manejo de tareas?
- Correcta: Un GPOS permite tiempos de latencia más altos, mientras que un RTOS garantiza tiempos de respuesta específicos. Un GPOS y un RTOS pueden manejar múltiples tareas, pero de manera diferente y ambos pueden utilizar interrupciones.
PREGUNTA DE COMPRENSIÓN. ¿Cuál es una ventaja de utilizar un RTOS en sistemas embebidos?
- Correcta: Proporciona mejor gestión del tiempo y priorización de tareas. Un RTOS mejora la gestión del tiempo y permite asignar prioridades a las tareas. Un RTOS reduce la latencia, no la aumenta.Un RTOS promueve una programación estructurada y organizada. Aunque un RTOS puede consumir más recursos, su ventaja principal es la gestión eficiente del tiempo y las tareas.