Objetivos
Al finalizar el tutorial el estudiante estará en capacidad de:
- Hacer uso del sistema de monitoreo de GCP para la consulta de métricas y creación de alarmas.
- Hacer uso de un gestor de paquetes para instalar aplicaciones sobre Kubernetes.
- Desplegar una versión del servicio de prometheus para captura de métricas y logs del cluster de k8s
- Habilitar el servicio de grafana para visualizar los datos expuestos por prometheus
- Comprender el uso de herramientas desplegadas sobre kubernetes para el monitoreo y captura de métricas.
Pasos previos
En particular se utilizarán los siguientes recursos:
- Para este taller se requiere que estén corriendo aplicaciones sobre el cluster. Le recomendamos ejecutar nuevamente el conjunto de aplicaciones del tutorial de ingress o puede realizarlo con las aplicaciones de su proyecto.
- gcloud SDK para acceder a los servicios del proveedor Google Cloud Platform a partir de la consola. En caso de no tenerla instalada puede consultar el siguiente manual de instalación:https://cloud.google.com/sdk/docs/install
- Herramienta de control de Kubernetes, kubectl. En caso de no tenerla instalada puede consultar el siguiente manual de instalación:https://kubernetes.io/docs/tasks/tools/
GKE ya ofrece dentro de su plataforma herramientas de observabilidad que le permitirán conocer en tiempo cercano al real, el estado de su cluster.
Diríjase a Kubernetes Engine > Cargas de trabajo y encontrará que hay una pestaña con el nombre de Observabilidad.
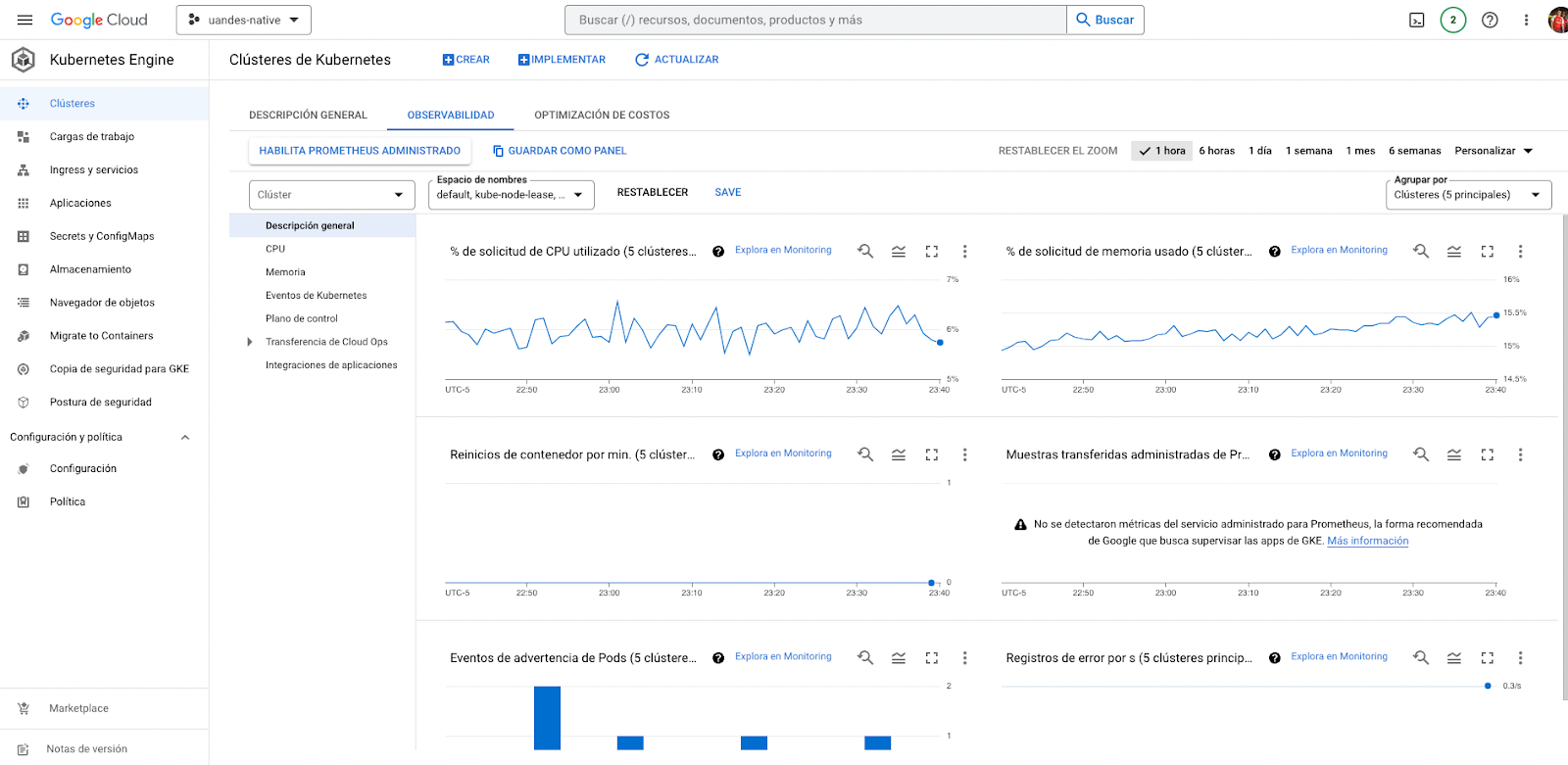
Al ingresar podrá encontrar un menú con las distintas métricas que se están tomando de su cluster. Revise las opciones CPU, Memoria y Eventos de Kubernetes; puede modificar el tiempo de muestra en la parte superior derecha.
Ahora diríjase al menú de cargas de trabajo, encontrará que hay otra pestaña con el nombre Observabilidad.
En esta pestaña ahora encontrará métricas que corresponden a los pods que están en ejecución. Puede revisar sus consumos de CPU y memoría.
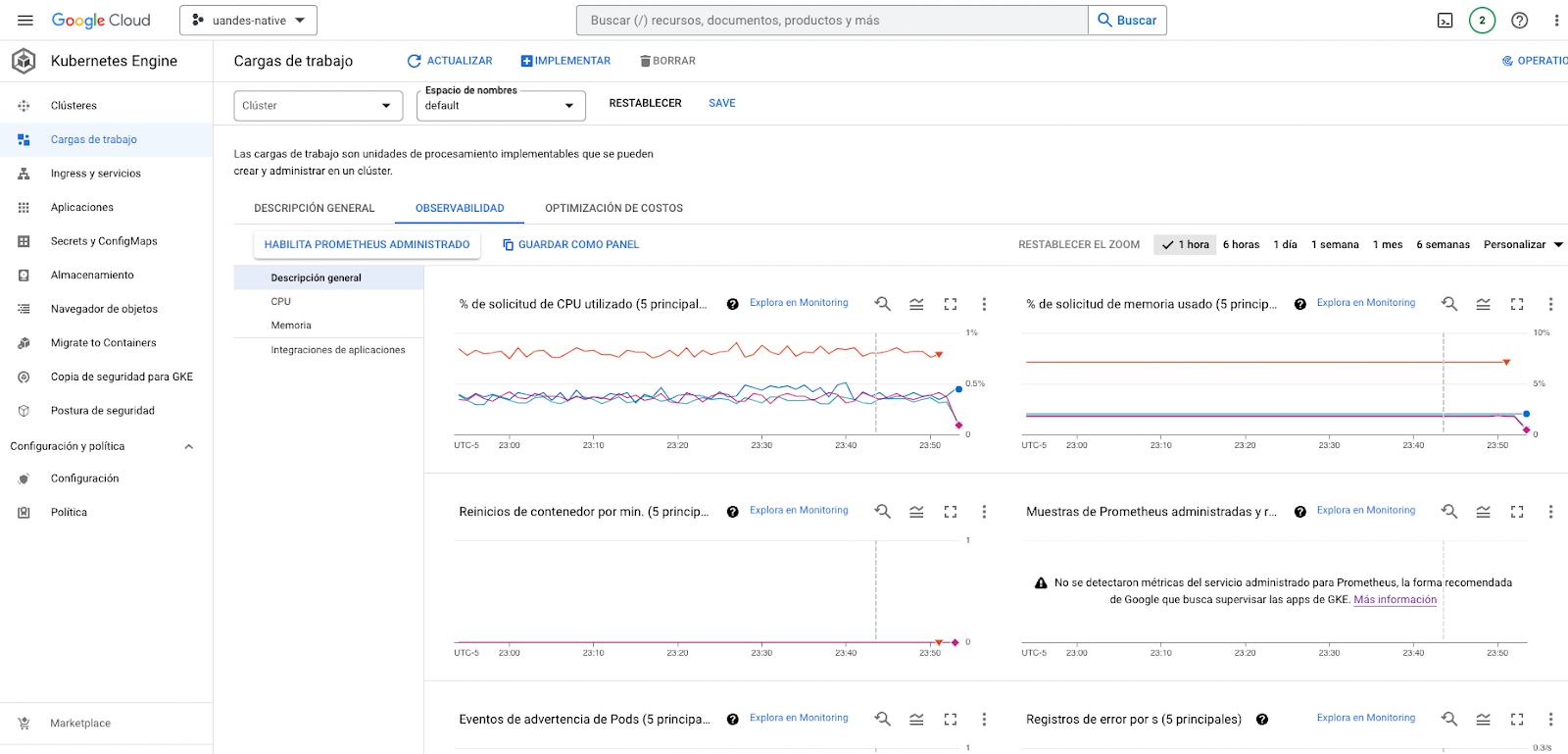
Si selecciona la opción "Explora en Monitoring" será dirigido al servicio de monitoreo de GCP; Cloud Monitoring.
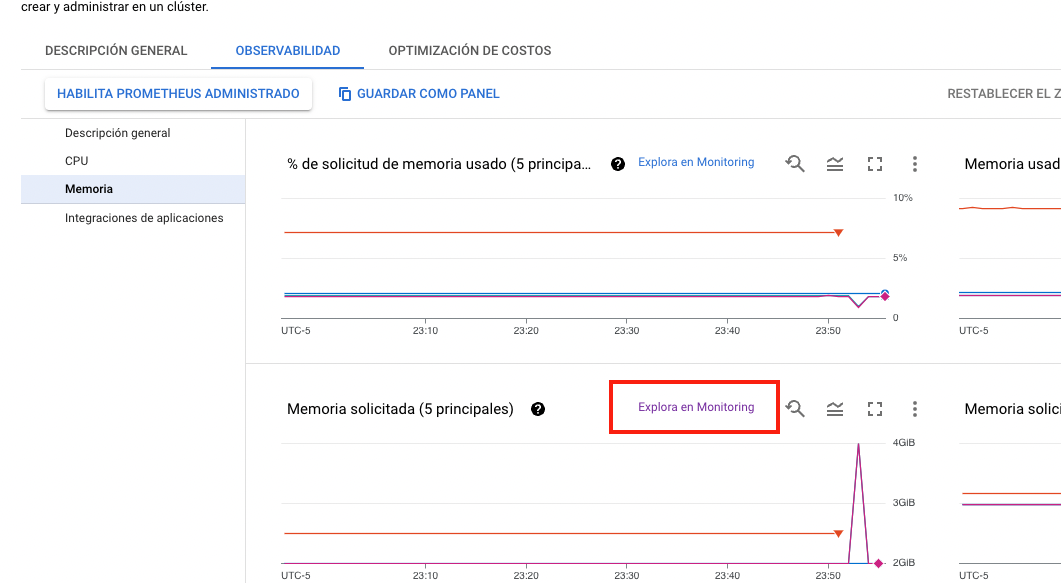
Este servicio está diseñado para poder monitorear todos los servicios de los que usted haga uso en GCP. Le recomendamos revisar la documentación del servicio si desea conocer más del mismo.
Al seguir el link anterior nos encontraremos en el explorador de métricas. Este explorador permite crear y guardar consultas sobre los servicios de los que usted está haciendo uso. Para realizar las consultas y crear métricas puede hacer uso de lenguajes como PromQL o MQL. En este ejemplo autogenerado, estamos comparando el uso de CPU por parte de nuestras tres aplicaciones.

Para crear una primera alerta haremos uso de la opción de Alertas que encontrará en el menú de Cloud Monitoring. Seleccione "EDIT NOTIFICATION CHANNELS".
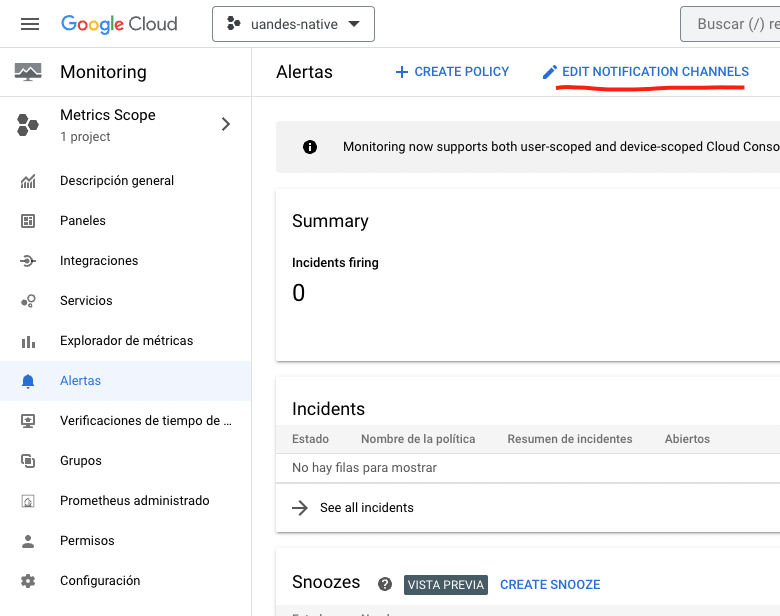
En esta página encontrará varios tipos de integraciones por defecto que tiene el servicio con el fin de enviar notificaciones: desde el servicio de slack, webhooks, correos y el servicio de pub-sub para construir integraciones custom.

Seleccionamos Add New y llenamos el formulario con su correo electrónico, y seleccionamos guardar.
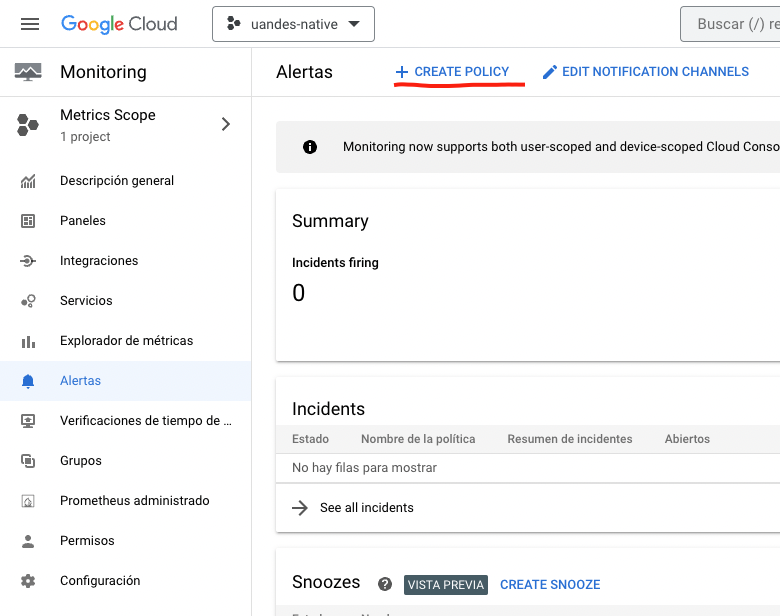
De regreso al menú de Alertas Seleccionamos CREATE POLICY.
Debemos seleccionar una métrica para nuestra alerta. En nuestro caso será una métrica que indique que nuestra aplicación está transmitiendo datos en exceso. Para ello seleccionamos Kubernetes Pod > Pod > Bytes transmitted y seleccionamos Aplicar.
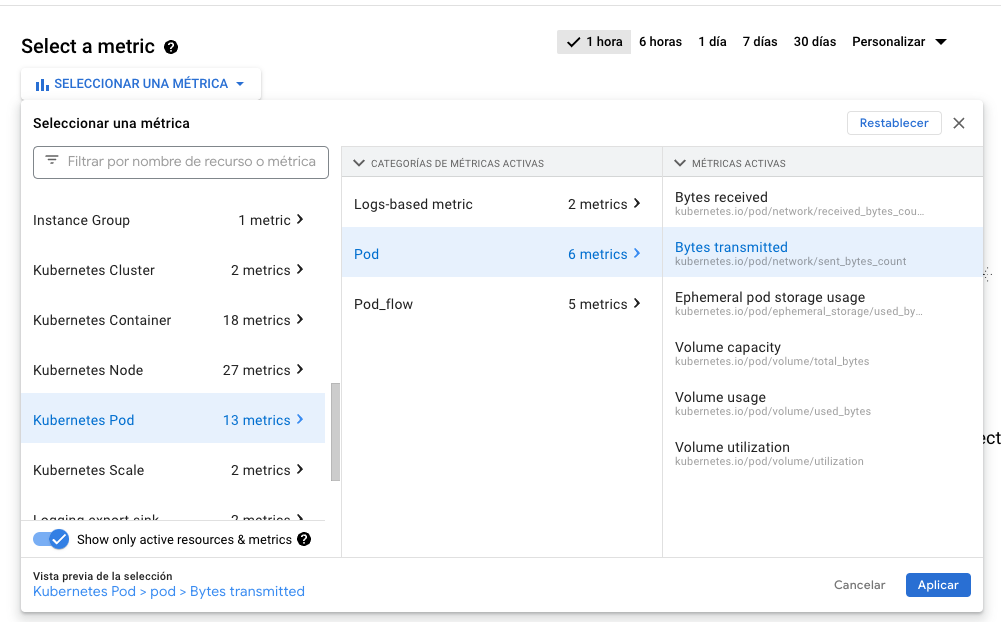
En la siguiente pantalla, agregaremos un filtro que indique que solo nos interesan los pods del servicio de la aplicación suma. Dejamos los demás valores por defecto y seleccionamos siguiente.
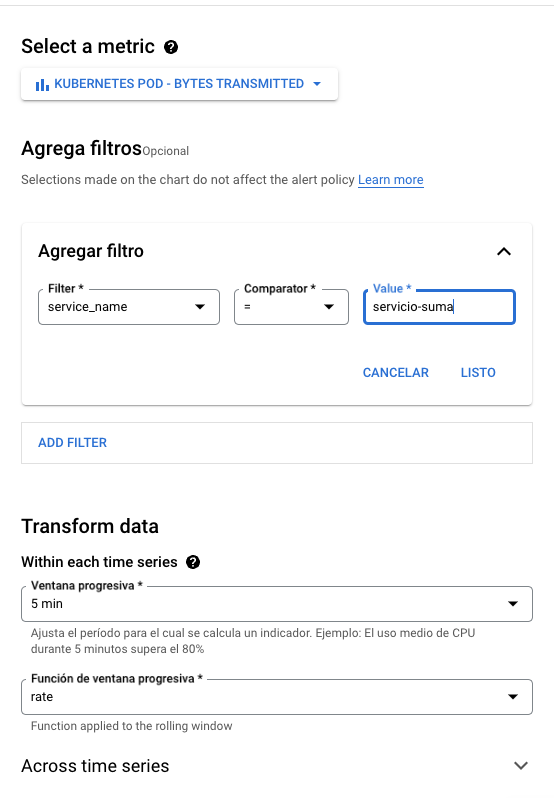
En la siguiente página colocamos el valor del umbral para la alerta. Use la gráfica de la derecha para colocar un valor con el que podamos probar. En nuestro caso será 40. Le damos un nombre a nuestra condición y seleccionamos siguiente.
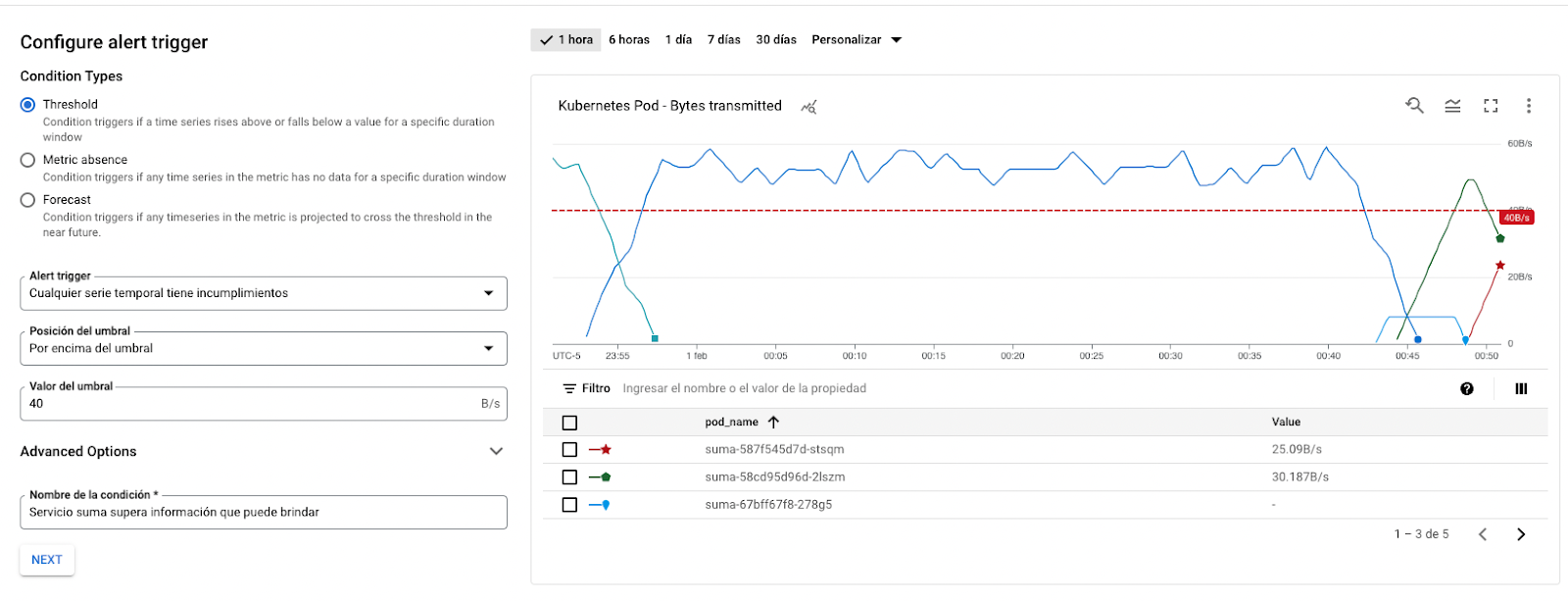
Por último, seleccionamos el canal de comunicación que configuramos con anterioridad. Colocamos un mensaje personalizado y el nombre de la alerta, y seleccionamos crear política.
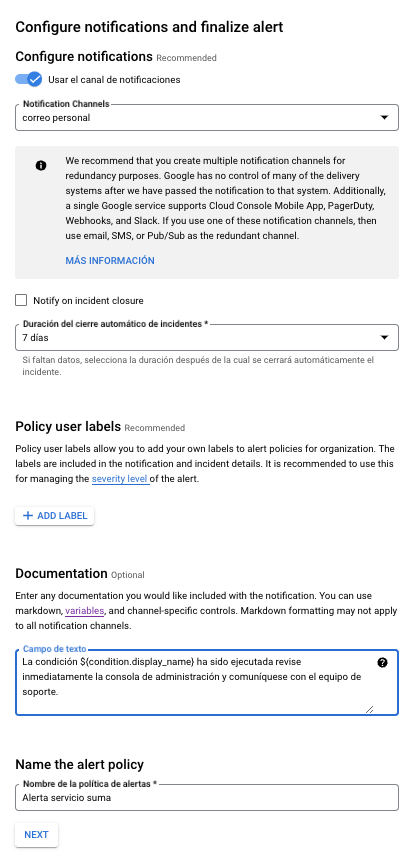
Con nuestra política activa nuestro tablero se verá similar a este ejemplo:
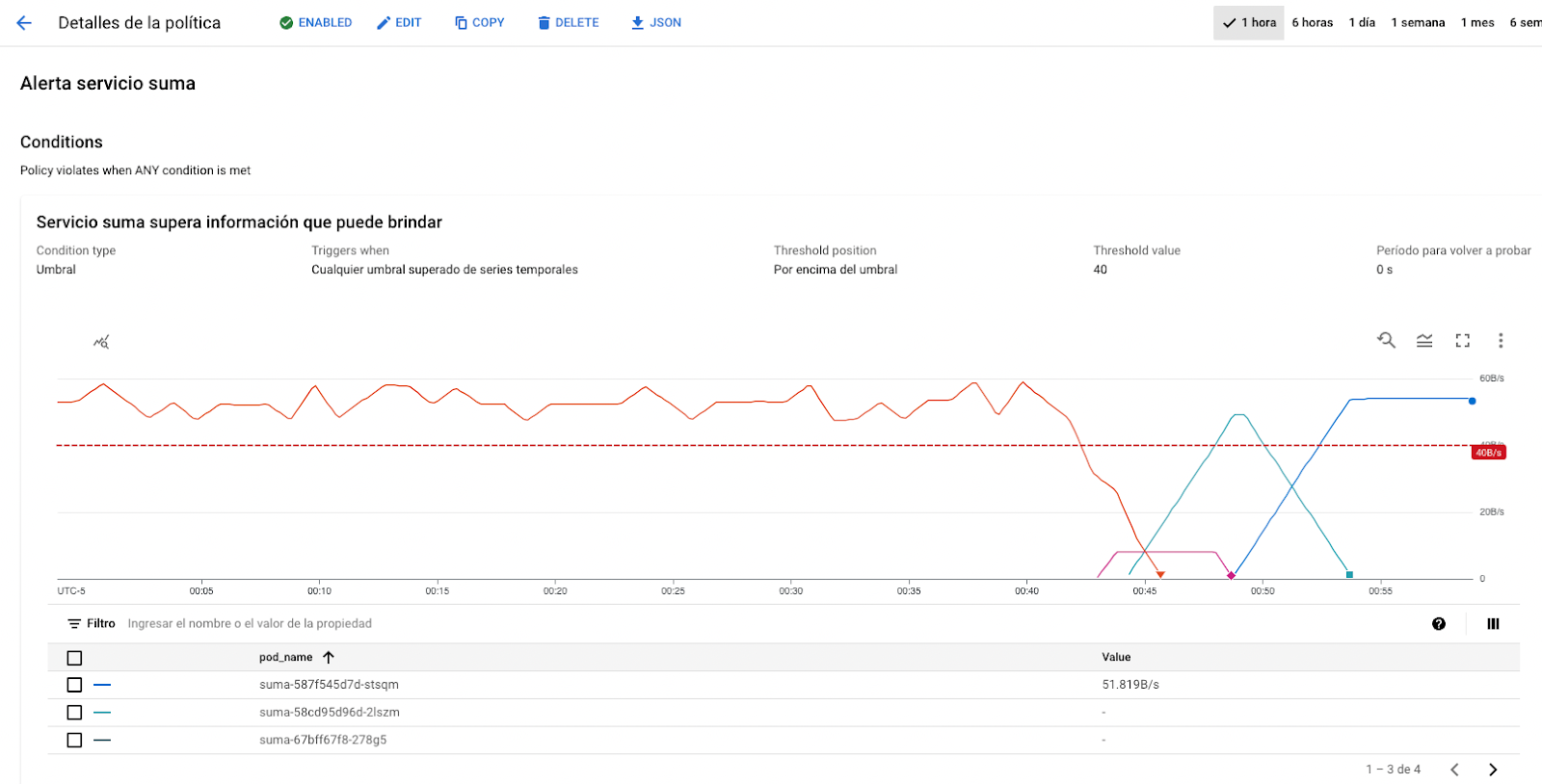
Con el fin de validar que la política funciona, accedemos a nuestro terminal y ejecutamos el siguiente comando. No olvide modificar el valor <IP-INGRESS> con la IP de su ingress.
user@192 ~ % curl --location --request POST 'http://<IP-INGRESS>/suma' \
--header 'Content-Type: application/json' \
--data-raw '{
"num_1" : 2,
"num_2": 3
}'
Si todo quedó correctamente configurado, debería recibir un correo similar al siguiente en los siguientes minutos.
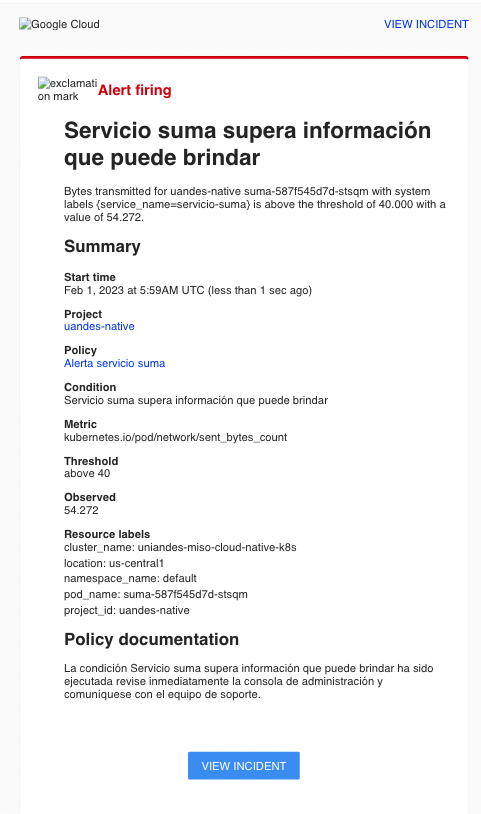
Para evitar costos innecesarios puede eliminar la política que creó anteriormente.
Una solución muy común para observabilidad sobre clusters de Kubernetes es hacer uso de Prometheus y Grafana las cuales son herramientas open source apoyadas por la CNCF.
- Prometheus captura la información de los diferentes componentes del cluster (nodos, pods, ingress, aplicaciones, etc), la almacena en una base de datos Time Series y ofrece un api y una interfaz que permite consultar esa información muy rápido haciendo uso de PromQL.
- Grafana es una herramienta muy robusta para la visualización de la información, permite construir tableros de control ajustados a sus necesidades y tiene integración con diferentes fuentes de datos, como por ejemplo Prometheus.
La arquitectura base al trabajar con estas aplicaciones es la siguiente:
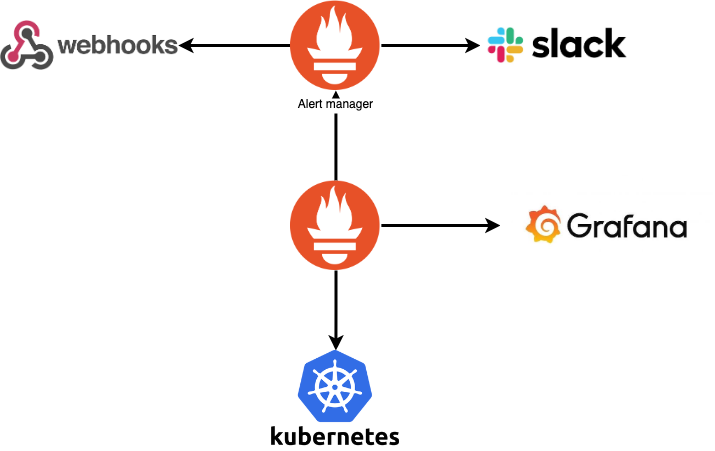
En esta arquitectura, Prometheus consume la información de nuestro cluster de kubernetes y grafana a su vez consume el api de prometheus para presentar sus dashboards. Prometheus puede usarse de dos formas, uno instalándolo directamente sobre su cluster o haciendo uso de un servicio administrado.
En este tutorial explicaremos como realizar la instalación sobre su cluster y si desea profundizar en el funcionamiento del servicio autoadministrado, lo invitamos a leer la documentación brindada anteriormente.
Para realizar la instalación de ambas plataformas sobre nuestro Kubernetes, podemos hacer uso de varios mecanismos. Dado que los componentes a crear no son pocos, haremos uso de un paquete estándar ya construido por la comunidad.
Para poder instalar este paquete debemos hacer uso de un gestor de paquetes para Kubernetes. En nuestro caso haremos uso de HELM.
HELM
Documentación: https://helm.sh/
Helm es un administrador de paquetes para Kubernetes que permite empaquetar, instalar y gestionar aplicaciones de manera sencilla y escalable en un cluster de Kubernetes. Algunas de sus características incluyen:
- Fácil instalación y despliegue de aplicaciones mediante plantillas y scripts (llamados Charts)
- Gestión de dependencias y versionamiento de paquetes
- Mantenimiento y actualización de aplicaciones
- Personalización y configuración de aplicaciones
- Comunidad activa y amplio catálogo de Charts disponibles.
Cuando trabajamos con HELM hacemos uso de Charts. Un chart en Helm es un paquete que contiene todos los recursos necesarios para desplegar una aplicación en un cluster de Kubernetes. Un chart puede incluir una combinación de archivos de configuración de Kubernetes, plantillas de archivos, scripts, imágenes de contenedor, recursos de redes, entre otros. Los charts son fácilmente compartibles y pueden ser utilizados en diferentes entornos y clusters.
Al utilizar Helm, puedes instalar y desplegar un chart en un cluster de Kubernetes con solo unos pocos comandos, lo que ahorra tiempo y esfuerzo en la configuración de los recursos de la aplicación. Además, los charts también permiten la gestión de versiones y la actualización de aplicaciones de manera sencilla y controlada.
Instalando HELM
Instale HELM haciendo uso del manual correspondiente dependiendo de su sistema operativo. Siga los pasos que encontrará en https://helm.sh/docs/intro/install/
Verifique la instalación del cliente ejecutando
user@192 ~ % helm version
Si está correctamente instalado deberá aparecer un mensaje como el siguiente
user@192 ~ % helm version
version.BuildInfo{Version:"v3.11.0", GitCommit:"472c5736ab01133de504a826bd9ee12cbe4e7904", GitTreeState:"clean", GoVersion:"go1.19.5"}
Para este tutorial manejaremos el repositorio de calculadora-numeros usado en los tutoriales pasados, en caso de no tenerlo clonado aún, puede consultarlo en el siguiente enlace. Trabajaremos sobre la rama feature/observability, para ello cambie la rama del repositorio actual a la respectiva rama, para hacerlo ejecute en su terminal:
user@192 ~ % git checkout feature/observability
Si ya se encuentra en esta rama, haga caso omiso al comando presentado anteriormente.
Para realizar la instalación de nuestras aplicaciones se recomienda primero crear un namespace distinto para nuestros nuevos componentes.
Para crear el namespace haremos uso del siguiente comando:
user@192 ~ % kubectl create namespace monitoring
Valide que haya sido correctamente creado por medio del comando:
user@192 ~ % kubectl get namespaces
Como se comentó anteriormente haremos uso de un paquete (Chart) estándar definido por la comunidad. En este chart ya se encuentra un stack completo con prometheus y grafana, El chart lo puede encontrar en su repositorio de github, si gusta puede revisarlo para darse cuenta de todos los componentes y configuraciones necesarias para su instalación.
Cabe aclarar que una instalación manual de prometheus no necesariamente requiere de todos los paquetes que se encuentran en el repositorio del Chart comunitario. Con el propósito académico de este tutorial haremos uso de este pero lo invitamos a leer la documentación de prometheus para encontrar guía de como poder configurarlo desde cero.
Agregamos el repositorio comunitario a nuestra lista de repositorios de Helm.
user@192 ~ % helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
Agregamos el repositorio de Charts estables y confiables de Helm
user@192 ~ % helm repo add stable https://charts.helm.sh/stable
Actualizamos el repositorio
user@192 ~ % helm repo update
Debido a que estamos usando un cluster autogestionado del tipo Auto-pilot, se pueden generar algunos errores en la instalación, es necesario modificar algunas configuraciones por defecto que trae el stack del Chart que instalaremos. Para ello ubique su terminal sobre la carpeta ./helm. Dentro encontrará un archivo values.yml con las configuraciones que estamos modificando. En la línea 17 estamos definiendo un password para el administrador de grafana. Modifíquelo por el que usted desee.
Ejecutamos la instalación de las herramientas por medio del siguiente comando:
user@192 ~ % helm install -f values.yml prometheus prometheus-community/kube-prometheus-stack --namespace monitoring
Tenga muy presente que estamos instalando sobre el namespace monitoring.
Si todo salió como se esperaba debería ver una pantalla como la siguiente:
user@192 ~ % helm install -f values.yml prometheus prometheus-community/kube-prometheus-stack --namespace monitoring W0201 02:52:22.539818 88670 warnings.go:70] Autopilot set default resource requests for Job monitoring/prometheus-kube-prometheus-admission-create, as resource requests were not specified. See http://g.co/gke/autopilot-defaults W0201 02:52:31.622845 88670 warnings.go:70] Autopilot set default resource requests for Deployment monitoring/prometheus-kube-state-metrics, as resource requests were not specified. See http://g.co/gke/autopilot-defaults W0201 02:52:31.658386 88670 warnings.go:70] Autopilot set default resource requests for Deployment monitoring/prometheus-kube-prometheus-operator, as resource requests were not specified. See http://g.co/gke/autopilot-defaults W0201 02:52:31.714428 88670 warnings.go:70] Autopilot set default resource requests for Deployment monitoring/prometheus-grafana, as resource requests were not specified. See http://g.co/gke/autopilot-defaults W0201 02:52:32.101267 88670 warnings.go:70] AdmissionWebhookController: mutated namespaceselector of the webhooks to enforce GKE Autopilot policies. W0201 02:52:50.905786 88670 warnings.go:70] Autopilot set default resource requests for Job monitoring/prometheus-kube-prometheus-admission-patch, as resource requests were not specified. See http://g.co/gke/autopilot-defaults NAME: prometheus LAST DEPLOYED: Wed Feb 1 02:51:49 2023 NAMESPACE: monitoring STATUS: deployed REVISION: 1 NOTES: kube-prometheus-stack has been installed. Check its status by running: kubectl --namespace monitoring get pods -l "release=prometheus" Visit https://github.com/prometheus-operator/kube-prometheus for instructions on how to create & configure Alertmanager and Prometheus instances using the Operator.
Verifique que todo haya quedado instalado por medio de los siguientes comandos:
user@192 ~ % kubectl --namespace monitoring get pods -l "release=prometheus"
user@192 ~ % helm list --all-namespaces
Para acceder a la interfaz gráfica de Prometheus ejecute el siguiente comando en su terminal
user@192 ~ % kubectl port-forward svc/prometheus-kube-prometheus-prometheus 9090:9090 -n monitoring
El resultado debe ser el siguiente:
user@192 ~ % kubectl port-forward svc/prometheus-kube-prometheus-prometheus 9090:9090 -n monitoring Forwarding from 127.0.0.1:9090 -> 9090 Forwarding from [::1]:9090 -> 9090
Deje el terminal abierto y acceda por su browser a la ruta http://127.0.0.1:9090. Verá la interfaz de prometheus.
En la caja que encuentra en la parte superior puede hacer consultas a métricas preestablecidas de Prometheus. Por ejemplo prometheus_http_requests_total.
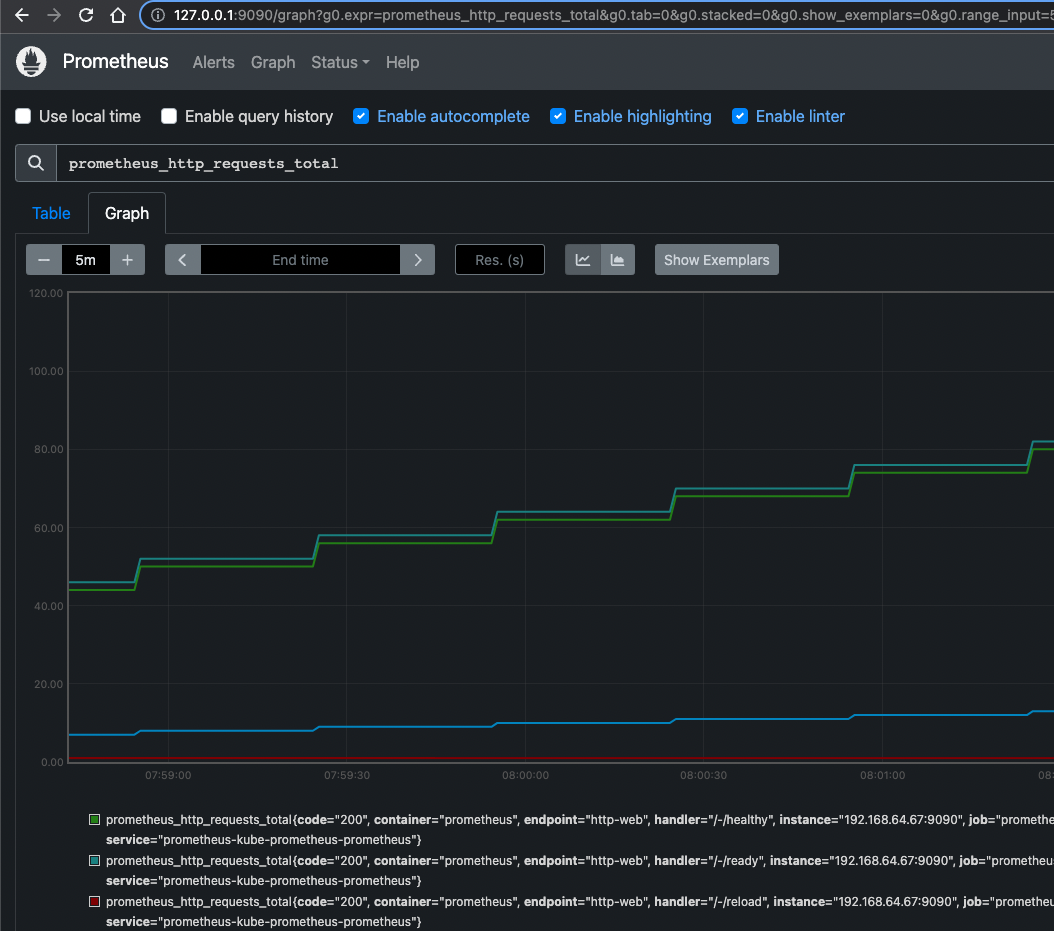
Como puede observar, esta interfaz no es tan intuitiva y fácil de manejar. Es por ello que para la visualización de datos se hace uso de grafana.
Para acceder a grafana abra un nuevo terminal y ejecute el siguiente comando:
user@192 ~ % kubectl port-forward deployment/prometheus-grafana 3000 -n monitoring
El resultado debe ser el siguiente:
user@192 ~ % kubectl port-forward deployment/prometheus-grafana 3000 -n monitoring Forwarding from 127.0.0.1:3000 -> 3000 Forwarding from [::1]:3000 -> 3000
Deje el terminal abierto y acceda por su browser a la ruta http://127.0.0.1:3000. Verá la interfaz de grafana.
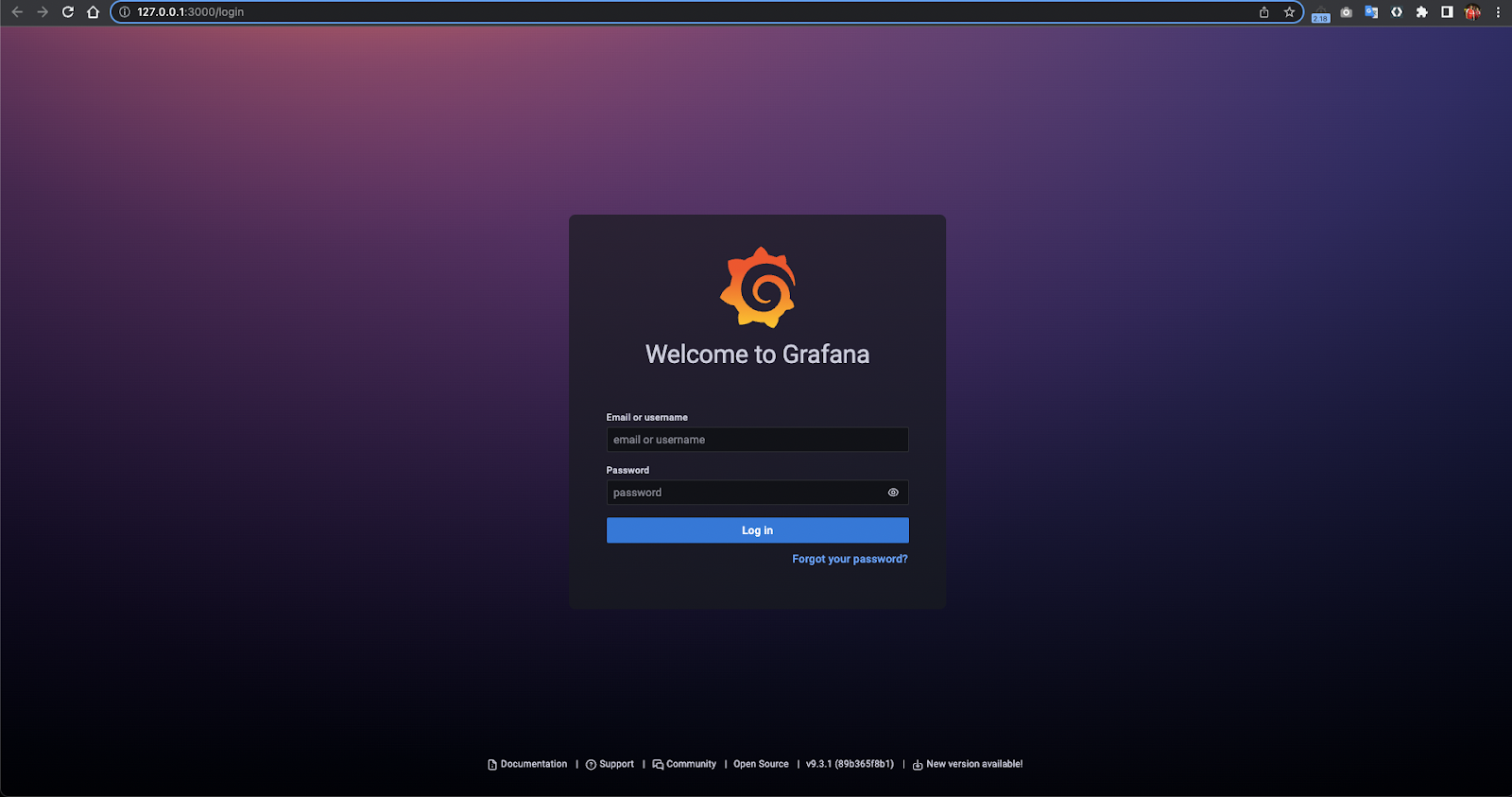
Acceda haciendo uso del usuario admin y la contraseña que definió en pasos anteriores. En el menú lateral busque la opción Dashboards > Browse.

Seleccione un dashboard predefinido como por ejemplo Kubernetes / Compute Resources / Pod
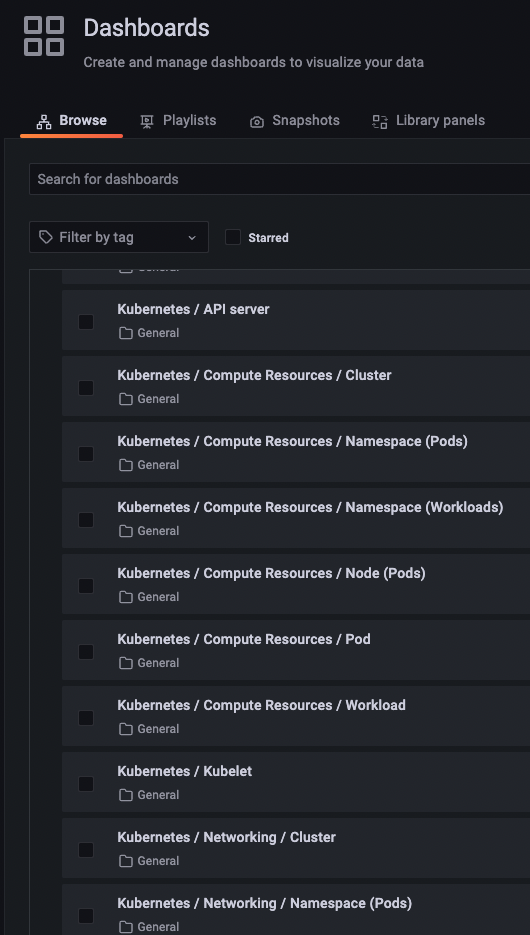
Revise los diferentes dashboards.
En ocasiones Grafana puede presentar un error en la muestra de los datos, dado las restricciones del cluster en modo autopilot.
Para finalizar y en caso que no quiera hacer uso de estos componentes debemos limpiar nuestro sistema para evitar costos innecesarios en nuestro cluster. Para ello primero debemos eliminar nuestro release.
user@192 ~ % helm uninstall prometheus -n monitoring
Verifique que el release no está instalado en su ambiente
user@192 ~ % helm list --all-namespaces
Verifique que ningún componente está ejecutándose en el namespace monitoring
user@192 ~ % kubectl get pods -n monitoring No resources found in monitoring namespace. user@192 ~ % kubectl get deployments -n monitoring No resources found in monitoring namespace. user@192 ~ % kubectl get services -n monitoring
Por último, elimine el namespace
user@192 ~ % kubectl delete namespace monitoring
¡Éxitos en el desarrollo del tutorial y nos vemos en una próxima oportunidad!
[1] Repositorio de Charts de la comunidad de prometheus:https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack.
[2] Página oficial de Helm https://helm.sh/
[3] Documentación oficial de Cloud monitoring https://cloud.google.com/stackdriver/docs/managed-prometheus?hl=es-419
[2] Página oficial de grafana https://grafana.com/
[2] Página oficial de Prometheus https://prometheus.io/