Con este taller, se busca que usted pueda poner en práctica sus conocimientos sobre modelos de n-gramas. Particularmente realizaremos tres ejercicios en los que se desarrollan distintas estimaciones de probabilidad usando un modelo de bigramas que usted entrenará en el primer ejercicio.
Para cada uno de los ejecicios se presenta una solución guiada. Sin embargo, se propone que usted primero haga su mejor esfuerzo para resolver cada uno de los ejercicios por su cuenta antes de revisar la solución.
Considere el siguiente corpus de sentencias:
<s>Yo soy robot</s> |
<s>Robot yo soy</s> |
<s>Robot yo amar</s> |
<s>Robot yo no amar</s> |
<s>No yo amar Robot</s> |
<s>No amar Robot</s> |
Calcule las probabilidades de los siguientes bigramas:
P(robot|<s>)= | P(yo|<s>)= | |
P(yo|robot)= | P(</s>|robot)= | |
P(robot|soy)= | P(</s>|soy)= | |
P(soy|yo)= | P(amar|yo)= | P(no|yo)= |
P(robot|amar)= | P(</s>|amar)= | |
P(amar|no)= | P(yo|no)= |
Inicialmente, podemos construir el vocabulario del corpus y calcular la frecuencia de cada uno de los tokens en el corpus:
Tokens | Frecuencia |
<s> | 6 |
yo | 5 |
soy | 2 |
robot | 6 |
</s> | 6 |
amar | 4 |
no | 3 |
Recordando, la probabilidad de un token con un modelo de bigramas esta dada por:
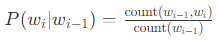
Entonces, la probabilidad de los bigramas, sería:
P(robot|<s>)= 0.5 | P(yo|<s>)= 0.167 | |
P(yo|robot)= 0.5 | P(</s>|robot)= 0.5 | |
P(robot|soy)= 0.5 | P(</s>|soy)= 0.5 | |
P(soy|yo)= 0.4 | P(amar|yo)= 0.4 | P(no|yo)= 0.2 |
P(robot|amar)= 0.5 | P(</s>|amar)= 0.5 | |
P(amar|no)= 0.667 | P(yo|no)= 0.333 |
¿Cuál es la palabra más probable para predecirse en las siguientes sentencias?
a. <s> Robot ________
b. <s> Robot yo no ________
c. <s> Robot yo soy Robot ________
d. <s> No yo amar _______
Debido a que estamos utilizando bígramas, la palabra más probable para continuar la sentencia estará condicionada únicamente por la última palabra de la secuencia.
Vea la siguiente tabla en donde las filas representarían la última palabra de cada una de las secuencias de texto, y los valores representan la probabilidad de todos los tokens dentro de nuestro vocabulario según el modelo de bigramas entrenado con el corpus del ejercicio 1.
Condición | <s> | yo | soy | robot | </s> | amar | no |
robot | - | 0.500 | - | - | 0.500 | - | - |
no | - | 0.333 | - | - | - | 0.667 | - |
amar | - | - | - | 0.500 | 0.500 | - | - |
De acuerdo a la información de la tabla, la solución del ejercicio 2, sería:
a. <s> Robot yo (</s> tiene la misma probabilidad)
b. <s> Robot yo no amar
c. <s> Robot yo soy Robot yo (</s> tiene la misma probabilidad)
d. <s> No yo amar robot (</s> tiene la misma probabilidad)
¿Cuál de las siguientes sentencias es más probable?
a. <s>Robot yo no yo amar </s>
b. <s>Robot yo soy </s>
c. <s>Yo no amar Robot yo soy </s>
Con un modelo de bigramas podemos calcular la probabilidad de una secuencia de texto como la multiplicación de la probabilidad de cada uno de los bigramas que componen la secuencia:
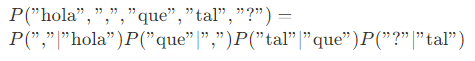
Así que el primer paso, es coger cada una de las secuencias de texto y descomponerlas en bigramas. Por ejemplo:
<s>Robot yo soy</s> -> (<s>, robot), (robot, yo), (yo, soy), (soy, </s>)
La probabilidad de la secuencia corresponde a la multiplicación de la probabilidad de cada uno de los bigramas:
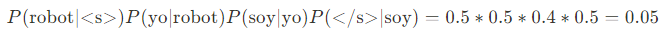
Realizando esta misma operación para cada una de las secuencias, tenemos que:
a. P(<s>Robot yo no yo amar </s>) = 0.0033
b. P(<s>Robot yo soy </s>) = 0.05
c. P( <s>Yo no amar Robot yo soy </s>) = 0.0011
La secuencia b sería la más probable. Lo cual es razonable teniendo en cuenta que es la secuencia más corta de las tres, y que la secuencia se encuentra en el corpus de entrenamiento.