En este ejercicio nos concentraremos en construir un sistema de recompensas para los agentes de aprendizaje por refuerzo.
Como sabemos, las recompensas son otorgadas al agente en la transición entre estados del sistema una vez se ha tomado una acción. El propósito del agente es maximizar su recompensa, por lo tanto, preferirá más frecuentemente optar por las acciones que otorgan una mayor recompensa.
El sistema de recompensas es la piedra angular del aprendizaje por refuerzo. Teniendo en cuenta el comportamiento del agente, las recompensas nos ayudan a modelar el objetivo del agente. De esta forma el objetivo del agente debería representarse con una mayor recompensa, y cualquier comportamiento no deseado (i.e., que se aleje del objetivo) se representará con una menor recompensa o una penalización (i.e., recompensa negativa). De esta forma el agente tenderá a presentar el comportamiento que esperamos ver en el agente.
Para introducir el sistema de recompensas vamos a reutilizar la implementación del agente que desarrollamos en el tutorial anterior (link).
Recuerden que nuestro agente se mueve en el modelo de GridWorld de una dimensión con cinco posiciones. El agente se encuentra en la posición inicial de la grilla y el objetivo en la casilla más lejana del agente, como se muestra en la figura.
En la implementación inicial tenemos dos clases definidas, el ambiente (Environment) y el agente (Agent). El agente se encarga de ejecutar sus propias acciones y llevar el estado actual. El ambiente contiene la evaluación de las acciones realizadas por el agente y maneja el cambio de estado.
Para desarrollar este ejercicio vamos a definir las recompensas para el agente. Dado que las recompensas se otorgan cuando el agente cambia de estado, el sistema de recompensas no puede ser definido como parte del agente, sino asociado al ambiente.
La definición del sistema de recompensas se realizará en 8 pasos.
1.Definir la clase Learner
Para mantener la modularidad del sistema, vamos a separar la definición del ambiente y el estado del sistema del sistema de recompensas, para ello implementaremos una nueva clase, Learner, donde implementaremos la función action que ejecuta el ciclo de aprendizaje.
- Para permitir el aprendizaje correcto del agente, la clase Learner será inicializada con el agente, el ambiente y tres parámetros por defecto utilizando la siguiente especificación
def __init__(self, agent, env, alpha=0.1, gamma=0.6, epsilon=0.1):
Los parámetros alpha, gamma y epsilon se conocen como los hiper-parámetros de aprendizaje, los cuales son los encargados de balancear la tasa de aprendizaje, la importancia de las acciones previas sobre las nuevas y la opción de tomar acciones desconocidas
- La clase
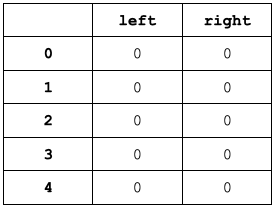
Learneradicionalmente define una tabla,table, de dimensionesestados x accionesque almacena los valores de recompensa de cada una de las acciones para cada estado. Por facilidad,tablepuede ser definida como un diccionario de Python. Defina una función additional__inittable__que se encarga de crear la tabla e inicializar sus posiciones en 0. Puede utilizar la funciónzerosdenumpypara realizar esta acción.
Recuerde que para el escenario de GridWorld, los estados están dados por la posición del agente en el tablero; de esta forma, la tabla debe ser una matriz como se muestra a continuación
2. Ejecución del Learner
En la clase Learner cree una nueva función run sin parámetros. Esta función se encargará de escoger la mejor acción a ejecutar para cada estado, mientras no se alcance el objetivo.
- Defina una variable
doneinicializada aFalsepara llevar el registro de terminación del episodio. - La función de run es ejecutar un loop mientras no se alcance el objetivo. En cada iteración el agente deberá calcular su estado actual (
current_state) y decidir si toma una nueva acción o una acción al azar. Esta decisión depende del parámetroepsilon. Si un valor aleatorio es menor que epsilon, se debe tomar una acción aleatoria (randomAction), de lo contrario se debe tomar la mejor acción para el estado actual, basado en los valores de recompensa almacenados entable. - Calcule el nuevo estado (
next_state), la recompensa (reward) y la condición de terminación (done) del agente ejecutando la funciónstepcon la acción seleccionada como parámetro. - Calcule el valor actual de recompensa (
old_value) para el estado actual y la acción tomada - Calcule el siguiente mejor valor (
next_max) dentro detablepara el próximo estado (next_state) - Calcule el nuevo valor de recompensa (
new_value) con la función de aprendizaje
(1 - self.alpha)*old_value + self.alpha*(reward + self.gamma*next_max)
- Asigne el nuevo valor (
new_value) atablepara el estado actual y la acción tomada
3. Escoger la acción del agente
Implemente la función randomAction en la clase Learner. Esta función retorna la posición de una de las acciones definidas dentro de la tabla de acciones del agente, actions.
4. Implementar la ejecución de la acción del agente
Implemente la función step que:
- Calcula el estado actual del agente (old_state),
- La recompensa para el estado actual y la acción tomada (
getReward), - Avanza el estado del agente ejecutando la acción tomada (
Agent.action), - Calcula el nuevo estado del agente
- Retorna cada una de las variables calculadas (recuerde que Python permite retornar múltiples valores separados por comas).
5. Implementar el sistema de recompensa
Implemente la función getReward que define el sistema de recompensas del agente. Para nuestro agente queremos reforzar el comportamiento de alcanzar el objetivo, la posición más a la derecha del tablero (4). Por lo tanto vamos a recompensar llegar dicha posición (con un valor de 10) retornando el valor de la recompensa y la terminación del episodio (True).
Para cualquier otro caso, retornaremos una recompensa neutra (un valor de 0, False).
6. Limpiar el ambiente
Elimine las funciones action, isDone y reset junto con la variable steps del ambiente.
7. Limpiar el Agente
- Modifique la función
actiondentro de la claseAgentpara que el agente reciba un identificador de acción y no el ambiente. - Implemente la función
getActionque recibe el número de la acción a tomar y retorna su nombre (forwardoback) - Modifique las funciones
forwardybackpara que no reciban parámetros - Agregue un parámetro (
rightBound) a la creación del agente como el tamaño del tablero del ambiente
8. Ejecute el loop del agente
Dentro de la función main, realice las siguientes modificaciones
- Agregue la creación del objeto
Lerner, pasando como parámetros el agenteay el ambientee - Reemplace el contenido del loop por el llamado a la función
rundelLernery elimine el llamado a la funciónresetdel ambiente
Entrega del ejercicio
Envíe la implementación completa del agente, el ambiente y el sistema de recompensas (la clase Learner) desarrollado dentro de un ambiente de Jupyter Notebooks.