¿Qué aprenderá?
- Durante este tutorial identificará diferentes alternativas de diseño de la función de almacenamiento de la capa de datos y analizará el desempeño de dichas alternativas a través de pruebas de carga.
¿Qué hará?
- Durante este tutorial desplegará una aplicación con una base relacional Postgre y otra aplicación con una base de datos de series de tiempo (Timescale). Pondrá en práctica dos de los patrones de diseño vistos en los videos, a saber: esquema estrella y Blob. También comparará el desempeño de ambas aplicaciones.
¿Cuáles son los prerrequisitos?
- Cuenta de AWS Academy para desplegar las aplicaciones en ese proveedor de nube. Las instrucciones para la creación de la cuenta fueron dadas en un tutorial previo.
- Conocimientos de AWS, SQL, Python, Django y JMeter.
- Aplicación Web REMA introducida previamente.
En este tutorial se usan dos aplicaciones IoT, funcionalmente iguales, pero diferentes en el diseño e implementación de la capa de datos. Las referenciamos como aplicación Postgre y aplicación Timescale teniendo en cuenta la tecnología de base de datos que usan. Postgre es una base relacional y Timescale una base de series de tiempo. Adicionalmente, la aplicación Postgre usa un patrón de diseño llamado esquema estrella y la aplicación Timescale un patrón llamado blob. El objetivo es comprender el efecto que tienen las decisiones de diseño e implementación en el rendimiento de las aplicaciones.
Postgre es una base de datos relacional open-source. Actualmente, es de los sistemas más populares entre bases de datos al lado de MySQL y SQL Server. Postgre es usada en grandes empresas como Spotify, Apple o la NASA.
Timescale es una base de datos de series de tiempo (open-source) basada en Postgre. Esta tecnología aprovecha lo mejor de ambos mundos: el rendimiento sobre consultas de datos basados en series de tiempo y la robustez de Postgre como base de datos relacional. Timescale es usada por Prometheus una tecnología para ingestar y consultar grandes volúmenes de datos de monitoreo.
Timescale agrega índices adicionales y compresiones de datos sobre la tabla que tiene los registros relacionados al tiempo. En el caso de este tutorial se trabajará sobre la tabla de las muestras captadas por los sensores.
En la siguiente tabla se encuentra una síntesis de las características principales de cada una de las aplicaciones:
Características | Postgre | Timescale |
Tipo | Relacional | Relacional, optimizada para series de tiempo |
Patrón de diseño | Esquema estrella | Blob |
Licenciamiento | Open-source | Open-source |
Tabla 1. Características principales de Postgre y Timescale
Encuentre más información sobre Postgre y Timescale en los siguientes enlaces:
Este tutorial ha sido construido para permitirle explorar el código de las aplicaciones con el fin de entender cómo se implementan los patrones de diseño de la capa de datos IoT en las tecnologías Postgre y Timescale. Luego, es necesario desplegar las aplicaciones en AWS y probarlas con Jmeter para comparar resultados de desempeño (latencia). La siguiente figura ilustra el despliegue que usaremos en el tutorial. En la parte derecha de la figura se ven dos máquinas EC2, en una se ejecutará una versión de la aplicación REMA implementada con Postgre y en la otra una versión de la aplicación REMA implementada con Timescale. Por su parte, en la izquierda está su máquina personal desde donde se envían peticiones al backend ya sea desde JMeter o desde el navegador.

Figura 1. Diagrama de despliegue del tutorial
El código que explicaremos se encuentra en este repositorio:
https://github.com/SELF-Software-Evolution-Lab/Realtime-Monitoring-webApp
En el repositorio existen varias ramas; entre esas "Postgre" y "Timescale", las cuales se usarán en este tutorial. Las dos ramas presentan diferencias en los siguientes aspectos, que se explicarán más adelante:
- Modelo de datos.
- Configuración de Timescale.
- Código de la capa de datos.
Los diagramas de los modelos de datos de ambas aplicaciones se presentan a continuación. Analícelos e identifique sus semejanzas y diferencias.
Postgre:

Figura 2. Modelo de datos: Postgre
Timescale:
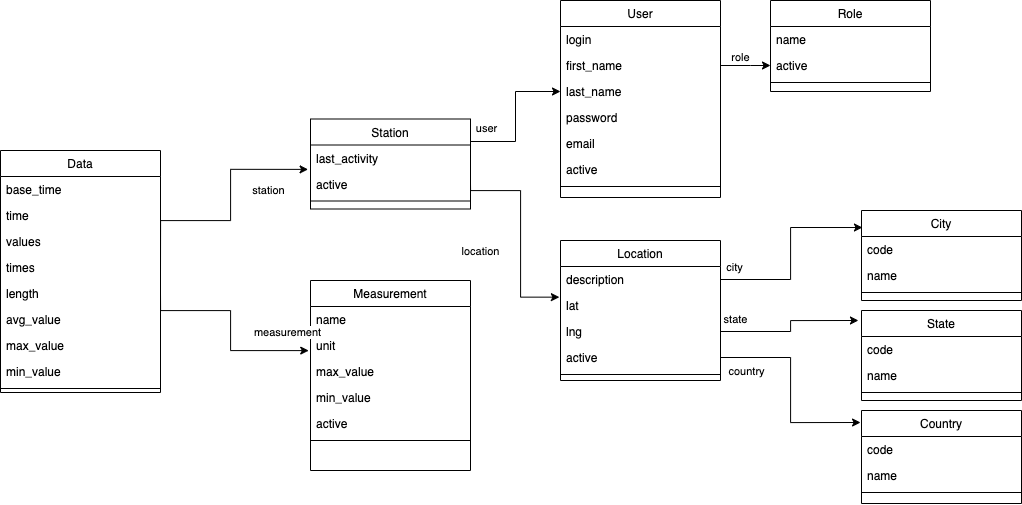
Figura 3. Modelo de datos: Timescale
Con respecto a los modelos de datos, note que son casi iguales en el número de entidades, atributos y relaciones, sin embargo se diferencian en la entidad "Data". En Postgre se crea un registro en la base de datos por cada muestra y en Timescale se crean registros donde cada uno tiene compresión de varias muestras tomadas en un periodo de tiempo. En Postgre, la entidad Data es la tabla principal del patrón de diseño estrella, de allí hay foreign keys a las tablas "Station" y "Measurements". Vale la pena notar que en la tabla "Data" de Postgre se almacena un registro por muestra colectada. En cambio, en Timescale se está usando el patrón de diseño Blob, donde se almacenan en cada registro dos aspectos: 1) en la lista de valores "values" se almacenan muestras tomadas en un periodo de tiempo; y 2) en la lista "times" se almacenan los tiempos en los que se toma cada muestra. De esta manera la base de datos Timescale crecerá mucho más lento de manera vertical que la base Postgre sencilla. Esto tiene un impacto en el desempeño que descubriremos a lo largo del tutorial.
También, el modelo Timescale tiene 2 variables adicionales que hacen referencia al tiempo: "base_time" y "time":
- "base_time" guarda el tiempo base para calcular el momento exacto en que se almacenaron las mediciones usando los valores dentro de la lista "times". Es decir, en el tiempo base se guarda el inicio de la hora en punto y dentro de "times" está el tiempo (en segundos) que ha transcurrido entre ese tiempo base y el momento en que se almacenó la medición.
- "time" es el identificador único del registro y corresponde al tiempo exacto (en microsegundos) en el que este se crea. Usamos microsegundos para evitar problemas de colisión en la generación del ID del registro, por ej., en caso que más de un dato llegue al mismo tiempo. Este identificador es usado por Timescale para mejorar el desempeño de la base de datos.
Por su parte para la configuración de Timescale, la rama correspondiente ("Timescale") tiene un archivo adicional que se ejecutará únicamente al momento de hacer las migraciones a la base de datos. El archivo se llama to_timescale.py y se encuentra bajo la carpeta migrations. A continuación se muestra el script SQL que configura la base de datos Timescale.
# Crea la hipertabla de timescale con chunks de 3 días.
migrations.RunSQL(
"SELECT create_hypertable('\"realtimeGraph_data\"', 'time', chunk_time_interval=>259200000000);"
),
# Configura la compresión para estaciones y variables. Son llaves foráneas de la tabla principal.
migrations.RunSQL(
"ALTER TABLE \"realtimeGraph_data\" \
SET (timescaledb.compress, \
timescaledb.compress_segmentby = 'station_id, measurement_id, time');"
),
# Comprime los datos cada 7 días.
migrations.RunSQL(
"SELECT add_compression_policy('\"realtimeGraph_data\"', 604800000000);"
),Primero, se le indica a Timescale que la tabla que tiene las muestras con los valores y tiempos es "realtimeGraph_data". Timescale la crea como hipertabla con la función create_hypertable. Una hipertabla permite tener hasta cientos/miles de columnas. Adicionalmente, el llamado a la función se debe parametrizar con el nombre de la columna ("time") que contiene el tiempo del registro y también el tamaño de los chunks expresado en tiempo. Un chunk es una partición de datos, en este caso la partición se hace por la dimensión "time" lo que quiere decir que cada chunk va a tener muestras de tres días consecutivos. En el script se expresan estos días en microsegundos porque la columna "time" está en esa unidad de tiempo. Uno de los propósitos de armar chunks es comprimir los datos de cada chunk y controlar el crecimiento vertical de la base Timescale.
Luego, en la segunda sentencia ("ALTER TABLE..."), se agrega una column list donde se van a comprimir por cada muestra los foreign keys a las tablas de "Station" y "Measurement" y también "time". Esto permite saber dada una muestra cuál fue el dispositivo que la colectó y a qué variable del ambiente hace referencia (por ej., temperatura, humedad, etc.).
Por último, se configura con qué frecuencia se hace la compresión de chunks, en este caso se hace cada 7 días, recuerde que está expresado en microsegundos en el script.
Este script se ejecuta al momento de correr el comando python manage.py migrate que está más adelante en los pasos de instalación de la app Web.
A continuación puede ver las diferencias principales en el código de inserción de las aplicaciones Postgre y Timescale.
Inserción de datos patrón estrella (Postgre):
def create_data(value: float, station: Station, measure: Measurement):
data = Data(value=value, station=station, measurement=measure)
data.save()
station.last_activity = data.time #tiempo de creación del registro
station.save()
return(data)Inserción de datos patrón Blob (Timescale):
def create_data(
value: float,
station: Station,
measure: Measurement,
time: datetime = timezone.now(),
):
base_time = datetime(time.year, time.month, time.day,
time.hour, tzinfo=time.tzinfo)
ts = int(base_time.timestamp() * 1000000) # ts se usa para inicializar "time", se multiplica por 1 millón para que quede en microsegundos
secs = int(time.timestamp() % 3600) # el módulo se usa para hallar los segundos que han pasado desde el inicio de "base_time", esto es el desfase
data, created = Data.objects.get_or_create(
base_time=base_time, station=station, measurement=measure, defaults={
"time": ts,
}
)
if created:
values = []
times = []
else:
values = data.values
times = data.times
values.append(value)
times.append(secs)
length = len(times)
data.max_value = max(values) if length > 0 else 0
data.min_value = min(values) if length > 0 else 0
data.avg_value = sum(values) / length if length > 0 else 0
data.length = length
data.values = values
data.save()
station.last_activity = time
station.save()
return dataA primera vista, la diferencia en la inserción de datos de Postgre y Timescale se evidencia en el número de líneas de código. En el primer fragmento de código (Postgre) el programa sólo necesita crear un registro "Data" y guardarlo, mientras que con Blob se tiene que hacer un procesamiento adicional: se trata de recuperar un registro "Data" cuyo tiempo coincida con la variable "base_time" y si no existe dicho registro se crea. Luego, agrega el valor y el tiempo de la muestra a las listas "values" y "times" y se calculan unos valores agregados, a saber: mínimo, máximo y promedio de los valores. Estos valores son pre-calculados y almacenados en la base para optimizar el desempeño de algunas consultas. Al final, se guarda el registro en la base de datos.
Por último, puede ver las diferencias principales en el código de consulta de las aplicaciones Postgre y Timescale.
Consulta de datos patrón estrella (Postgre):
data = []
for location in locations:
stations = Station.objects.filter(location=location)
locationData = Data.objects.filter(
station__in=stations, measurement__name=selectedMeasure.name, time__gte=start.date(), time__lte=end.date())
if locationData.count() <= 0:
continue
minVal = locationData.aggregate(
Min('value'))['value__min']
maxVal = locationData.aggregate(
Max('value'))['value__max']
avgVal = locationData.aggregate(
Avg('value'))['value__avg']
data.append({
'name': f'{location.city.name}, {location.state.name}, {location.country.name}',
'lat': location.lat,
'lng': location.lng,
'population': stations.count(),
'min': minVal if minVal != None else 0,
'max': maxVal if maxVal != None else 0,
'avg': round(avgVal if avgVal != None else 0, 2),
})Consulta de datos patrón Blob (Timescale):
data = []
# se filtran los registros cuyo "time" está en el rango (start_ts, end_ts), se multiplica por 1 millón para que quede en microsegundos que es la unidad de "time"
start_ts = int(start.timestamp() * 1000000)
end_ts = int(end.timestamp() * 1000000)
for location in locations:
stations = Station.objects.filter(location=location)
locationData = Data.objects.filter(
station__in=stations, measurement__name=selectedMeasure.name, time__gte=start_ts, time__lte=end_ts,
)
if locationData.count() <= 0:
continue
minVal = locationData.aggregate(Min("min_value"))["min_value__min"]
maxVal = locationData.aggregate(Max("max_value"))["max_value__max"]
avgVal = locationData.aggregate(Avg("avg_value"))["avg_value__avg"]
data.append(
{
"name": f"{location.city.name}, {location.state.name}, {location.country.name}",
"lat": location.lat,
"lng": location.lng,
"population": stations.count(),
"min": minVal if minVal != None else 0,
"max": maxVal if maxVal != None else 0,
"avg": round(avgVal if avgVal != None else 0, 2),
}
)La consulta de los datos es muy similar en los dos escenarios. Esta consulta busca por cada locación (desde donde se están colectando datos, por ej., Bogotá), el valor mínimo, máximo y promedio de un "Measurement" (por ej., temperatura, humedad) en esa ciudad. Esta consulta se usa en la aplicación REMA para generar la visualización "datos por ciudad" en un rango de fechas ("start", "end") establecido por el usuario.
Lo que cambia usando Blob es que el filtro de fecha se hace con el timestamp en microsegundos pues es como está configurada la columna "time" en Timescale. También, cambia el cálculo de las diferentes agregaciones como el mínimo, el máximo y el promedio. En el caso de Blob, estos cálculos no se realizan sobre los valores sino sobre las agregaciones ya precalculadas en la inserción de cada registro.
Note que en la consulta de Blob no es necesario recorrer las listas "values" internas de cada registro ya que en la inserción se calculó el mínimo, máximo y promedio de los valores de cada lista. Esto tiene un impacto en el desempeño de las inserciones y consultas en Timescale.
El siguiente paso después de explorar el código es crear las bases de datos. Para esto necesitará el archivo de CloudFormation con el que AWS creará la infraestructura necesaria. En resumen, el archivo tiene instrucciones para crear dos EC2 (máquinas virtuales de AWS), en una de ellas se desplegará una base de datos relacional (Postgre) y en la otra una base de series de tiempo (Timescale).
Realice estos pasos para crear las bases de datos:
- Ingrese a AWS Academy con sus credenciales y luego escoja el curso "Learner Lab...". En "Modules" inicie el laboratorio con el botón "Start lab":

Figura 4. Interfaz de inicio del laboratorio
- En la terminal, ingrese el siguiente código para descargar el archivo de CloudFormation:
wget https://raw.githubusercontent.com/SELF-Software-Evolution-Lab/Realtime-Monitoring-webApp/main/tutoriales/Capa%20de%20Datos/IOT-Capa-Datos.template.json -O template --no-check-certificate- Ejecute lo siguiente para empezar la creación del stack (esto es, las máquinas EC2 y las bases de datos):
aws cloudformation create-stack --stack-name iot --template-body file://template --capabilities "CAPABILITY_IAM"Dicho comando debe retornar en consola una salida como la siguiente:
{
"StackId": "arn:aws:cloudformation:us-east-1:123456789012:stack/broker-mqtt/330b0120-1771-11e4-af37-50ba1b98bea6"
}- Diríjase a la consola de AWS, pulsando el botón "AWS" en la interfaz de inicio del laboratorio.

Figura 5. Inicio de la consola de AWS
- En el módulo "CloudFormation" (que se alcanza yendo a este enlace https://console.aws.amazon.com/cloudformation/) espere a que el stack se termine de crear, indicado por el estado "CREATE_COMPLETE":

Figura 5. Stacks creados en CloudFormation
- Diríjase a "EC2->Instances" y verifique que la máquina EC2 esté creada y en estado "Running". Puede usar este enlace https://console.aws.amazon.com/ec2/v2/:

Figura 6. Máquina EC2 creada y corriendo
- Desde su máquina personal, pruebe la conexión a las bases de datos previamente creadas; para esto use cualquier visor de bases de datos (por ejemplo, DBVisualizer es una opción gratuita para Windows y Mac), y conéctese a las bases utilizando la siguiente información:
Host:
Port: 5432
Database: iot_data
User: dbadmin
Password: uniandesIOT1234*
Para más información sobre cómo conectarse a una base desde DBVisualizer consulte la documentación: https://confluence.dbvis.com/display/UG130/Create+a+New+Database+Connection
Teniendo las bases de datos listas, hay que conectarlas con las aplicaciones REMA que contienen el código previamente explicado. Estas aplicaciones son las que se someterán a las pruebas de carga después. Repita las instrucciones que damos a continuación en ambas máquinas virtuales.
- Conéctese a la máquina EC2. Para esto, diríjase a "EC2->Instances" (https://console.aws.amazon.com/ec2/v2/) y entre al detalle de la máquina dando clic en el id de instancia.

Figura 7. Ingreso al detalle de una máquina EC2
- Una vez en la máquina oprima el botón "Connect". Luego, vaya a la pestaña "EC2 Instance Connect" y oprima "Connect".

Figura 8. Detalle de una máquina EC2

Figura 9. Ventana de conexión a una máquina EC2
Como resultado se abrirá la consola de la máquina EC2 con su información clave como id, nombre e ipmaquina debajo de ella, como se muestra en la imagen que sigue con el recuadro rojo.

Figura 10. Consola de una máquina EC2
- Entre a cada máquina EC2 creada en el paso anterior usando la consola. En una descargue la aplicación "Postgre" y en la otra la aplicación "Timescale" empleando los siguientes comandos. Un comando para cada máquina.
Para Postgre:
~$ wget https://github.com/SELF-Software-Evolution-Lab/Realtime-Monitoring-webApp/raw/main/tutoriales/Capa%20de%20Datos/postgresMonitoring.zip -O server.zipPara Timescale:
~$ wget https://github.com/SELF-Software-Evolution-Lab/Realtime-Monitoring-webApp/raw/main/tutoriales/Capa%20de%20Datos/timescaleMonitoring.zip -O server.zip- Luego de haber descargado el código de la aplicación (
server.zip) en cada máquina, éste se encontrará en la carpeta de trabajo. Descomprima el archivo con el comando:
~$ unzip server.zip- Ingrese a la carpeta
realtimeMonitoring/, instale el ambiente y actívelo con los siguientes comandos
~$ cd realtimeMonitoring/
~/realtimeMonitoring/$ pipenv install~/realtimeMonitoring/$ pipenv shell- Realice las migraciones a la base de datos. Esto consiste en estructurar las tablas y columnas según los modelos de datos de cada aplicación. No hay necesidad de configurar la conexión con las bases de datos porque ya están desplegadas en las máquinas EC2 y la conexión se realiza por localhost con las mismas credenciales. Entonces, para aplicar las migraciones ejecute en cada máquina:
(realtimeMonitoring) ~/realtimeMonitoring/$ python3 manage.py makemigrations(realtimeMonitoring) ~/realtimeMonitoring/$ python3 manage.py migrateAl ejecutar los comandos, en caso de que se generen errores de tipo "No module named xxx", utilice los siguientes comandos para instalar los módulos que generan el inconveniente:
pip3 install Django
pip3 install Django-crontab
pip3 install psycopg2
pip3 install ldap3
pip3 install django_cron
pip3 install requestsCon las aplicaciones instaladas en las máquinas EC2 y conectadas a las bases de datos, el siguiente paso es generar datos de prueba.
Para observar mejor la diferencia entre los patrones de diseño implementados y las tecnologías de bases de datos se necesita de una gran cantidad de datos. En esta parte se generarán 500000 muestras aleatorias para poblar la base de datos. Este proceso puede tomar un momento por lo que sí necesita tener más tiempo las máquinas EC2 activas, recuerde que en la interfaz de AWS Academy, puede restablecer el temporizador de su sesión presionando "Start lab"nuevamente.

Figura 11. Interfaz de inicio del laboratorio
- Ejecute la instrucción que genera los datos de prueba:
(realtimeMonitoring) ~/realtimeMonitoring/$ python manage.py generate_data Durante la primera ejecución del comando generate_data podrá observar que se están generando los datos. El sistema automáticamente se detendrá cuando los datos generados lleguen al número de muestras mencionado previamente. En algunos casos y dependiendo de la conectividad, la generación de los datos podría tomar un tiempo considerable (por ej., 60 minutos). Si este es el caso, se recomienda interactuar con la consola AWS de conexión a la instancia (por ej., haciendo clic sobre esta) para evitar que se desconecte de la máquina por inactividad. Si por algún motivo la máquina se desconecta y no se han generado todos los datos, debe volver a ejecutar la instrucción anterior. Pero antes, asegúrese de haber activado el ambiente virtual dentro de ~/realtimeMonitoring/ a través del comando:
pipenv shell
- Cuando se termine la generación de datos, ejecute el siguiente comando para iniciar el servidor de aplicaciones:
(realtimeMonitoring) ~/realtimeMonitoring/$ python manage.py runserver 0.0.0.0:8000- Dado que el servidor de aplicaciones está corriendo, puede acceder desde su computador personal a éste y visualizar la información. Entre a http://<ip-máquina>:8000/mapJson o a http://<ip-máquina>:8000/rema. La
- Por otro lado, puede usar el visor de bases de datos y consultar los datos generados. Los datos de conexión a las bases de datos los dimos en el paso "Crear las bases de datos".

Figura 12. Captura de pantalla de la tabla "realtimeGraph_data" de Timescale en la herramienta DBVisualizer
Como son bastantes registros este proceso puede tomar un tiempo y el tiempo es diferente para Postgre y Timescale. ¡Mientras se generan los datos puede adelantar otra actividad!
Para esta sección, asegúrese de tener instalada la herramienta Jmeter en su computador personal. Si no lo tiene, puede acceder al sitio web de Apache para descargar la herramienta, posteriormente debe descomprimir el archivo.
Además, descargue el script de pruebas JMeter. El script tiene dos pruebas una para la aplicación Postgre y otra para la aplicación Timescale. Cada prueba consulta las muestras del "Measurement" temperatura dentro de un intervalo de tiempo (01/07/2021 - 31/07/2021). Hemos parametrizado cada prueba para enviar 60 peticiones en un período de 1 segundo. Hemos escogido 60 usuarios porque es el número promedio de estudiantes que usan la aplicación REMA. El paso a paso para ejecutar las pruebas es el que sigue:
- Abra Jmeter siguiendo las instrucciones adecuadas al sistema operativo que tenga en su computador. Dentro de la carpeta
apache-Jmeter-5.4.3/bin/:
Para Windows:
Abrir el archivo Jmeter.bat
Para Linux:
Ejecutar el archivo Jmeter.
Para Mac:
Ejecutar el archivo Jmeter con click derecho (abrir y confirmar la ventana emergente si sale).
- Dentro de Jmeter, oprima el botón "Open" (
 ) para buscar el script de pruebas previamente descargado.
) para buscar el script de pruebas previamente descargado.

Figura 13. Interfaz de inicio de Jmeter
- Seleccione el script de pruebas y cambie algunos parámetros para adaptarlo a su despliegue. En particular, debe cambiar las direcciones IP de los servidores. En el componente de variables cambie los valores de las variables
ip_Postgreeip_Timescalepor las IPs correspondientes que obtuvo en el paso "Instalar la aplicación Web". Al abrir el archivo, los valores por defecto sonlocalhost, sin embargo, debe cambiarlos por las IPs de AWS. Ej: 3.227.21.145

Figura 14. Configuración de prueba en Jmeter
- Ejecute las pruebas. Oprima la flecha verde y espere a que las pruebas corran. En la esquina superior se le informa cuántas pruebas hacen falta y el tiempo que está durando la prueba.

Figura 15. Resumen de estado de las pruebas en Jmeter
- Cuando terminen las pruebas revise y compare los resultados en los reportes "View Results Tree" y "Summary Report" de cada prueba.
Las siguientes preguntas lo invitan a reflexionar sobre lo que observó en el desarrollo de los pasos inmediatamente anteriores referidos como "Generar datos de prueba" y "Probar las aplicaciones Web":
- ¿Qué aplicación, la que usa Postgre o la de Timescale, tiene una mejor latencia en la inserción de datos y por qué?
- ¿Qué aplicación tiene una mejor latencia en la consulta y por qué?
Para responder los porqués piense en las características de los patrones de diseño y las tecnologías de bases de datos empleadas en el tutorial. ¡Traiga sus reflexiones a las sesiones sincrónicas!
Al finalizar este tutorial, se espera que haya evidenciado los beneficios y limitaciones en desempeño de usar ciertos patrones de diseño y bases de datos en un sistema IoT.
Créditos
Versión 1.0
Juan Avelino, Kelly Garcés | Autores |
Rocío Héndez, Andrés Bayona | Revisores |