En este tutorial construiremos el ambiente para un clásico ejemplo dentro del aprendizaje por refuerzo, Gridworld. Utilizaremos el ambiente de Gridworld para probar diferentes algoritmos de solución de los agentes de aprendizaje por refuerzo. De esta forma será posible resaltar las diferencias entre los algoritmos propuestos y comparar su eficiencia en un ambiente común.
El ambiente de gridworld está compuesto por :
- Una cuadrícula
- El estado inicial del agente
- Un conjunto de acciones (distintas) para cada casilla dentro de la cuadrícula
- Las recompensas de cada casilla.
Vamos a explorar el funcionamiento de los procesos de decisión de Markov, y en general del aprendizaje por refuerzo por medio de los ambientes de ejecución para los agentes. En particular implementaremos un ambiente común dentro del aprendizaje por refuerzo, que se llama Gridworld.
Gridworld consiste en un tablero de nxn, con estado inicial la casilla (0,0)(en azul). Dentro de cada una de las casillas, las acciones corresponden a los posibles movimientos del agente {arriba, abajo, izquierda, o derecha}, mientras que el agente se mantenga dentro del tablero. Algunas de las casillas del tablero están definidas como obstáculos, sobre los cuales el agente no puede pasar. Finalmente el tablero tiene una casilla objetivo, el lugar al cual debe llegar el agente, y una casilla trampa. Si el agente llega a la casilla de trampa, se considerará como un fallo en la ejecución. En la figura a continuación mostramos un ejemplo del ambiente de Gridworld.
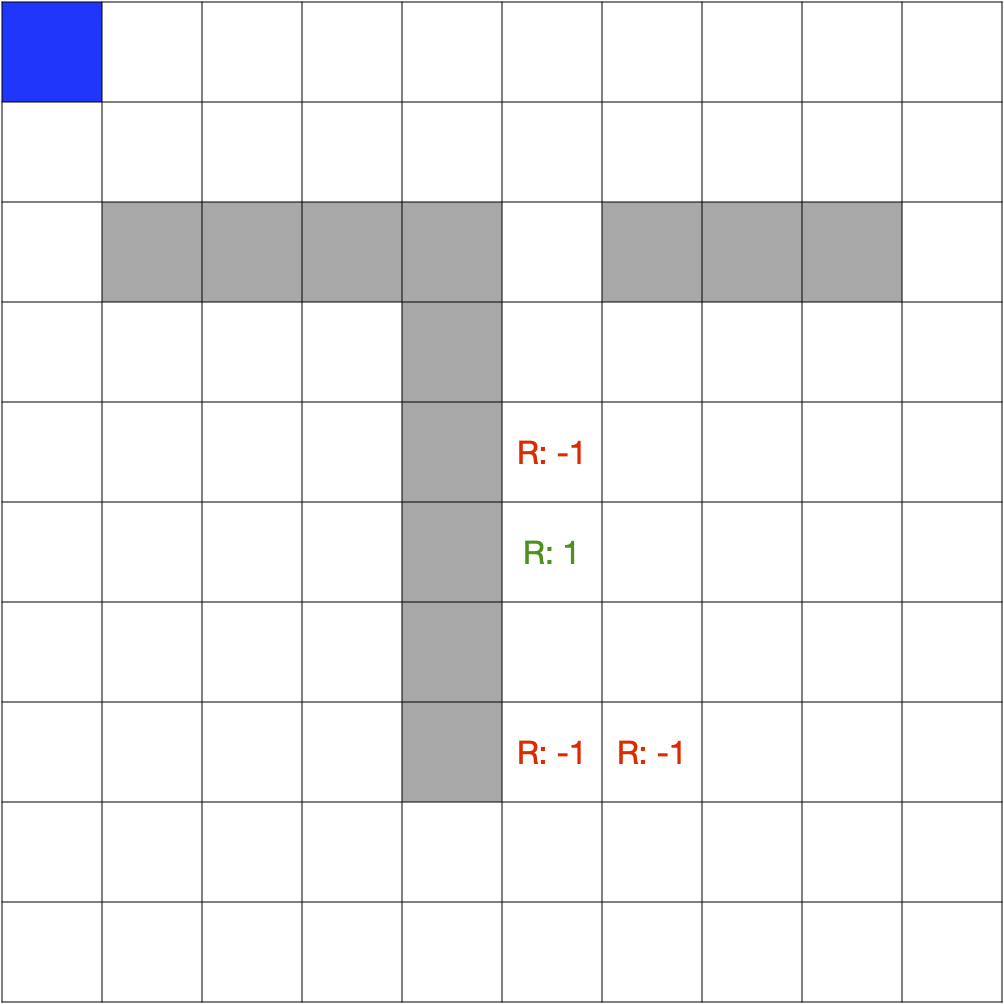
Definición del ambiente
El ambiente (dada por una clase Environment definida en el archivo gridworld_env.py) debe estar compuesto por la información relevante para el agente. En nuestro caso particular esto corresponde a la posición del agente dentro del laberinto.
Paso 1
Complete la definición del ambiente estableciendo por:
1. El tablero (board), con las dimensiones dadas por parámetro. Definiremos las casillas por las que puede pasar el agente con estado True y las casillas por las que no puede pasar el agente con un estado False. Por ejemplo, la casilla [2][1] estaría marcada con False así, self.board[2][1] = False
2. Un atributo (dimensions) para almacenar las dimensiones del tablero
3. Un atributo (rewards) que lleva las recompensas de cada casilla del tablero.
- 1 para la casilla objetivo
- -1 para las casillas de trampa
- 0 para las otras casillas
4. Un atributo con el estado actual (current_state) en el que se encuentra el agente. Por defecto este estado será la posición (0,0) (definido como una tupla).
gridworld_env.py
class Environment:
def __init__(self, n):
#self.dimensions
#self.current_state
#self.board = [[True for x in range(0, n)] for y in range(0,n)]
#self.rewards = [[0]*n]*n
Definición del comportamiento
Para el ambiente definiremos un conjunto de funciones que determinan su comportamiento. Las responsabilidades del ambiente incluyen: establecer el estado actual, definir las acciones posibles para cada estado, ejecutar las acciones y reiniciar el episodio.
Paso 2.
Implemente las funciones de comportamiento del agente
1. get_current_state que retorna el estado actual del agente
2. get_posible_actions que retorna las acciones disponibles para cada estado, dado por parámetro como una tupla (i,j). Las acciones estarán dadas por su nombre ('up', 'down', 'left', 'right'). Para cada uno de los estados revisamos el conjunto de acciones posibles de acuerdo a su posición en el tablero y construimos la tuple de las acciones por ejemplo así: if state[0] > 0: actions += ('up', )
3. do_action que recibe como parámetro la acción a ejecutar y retorna el valor de la recompensa y el nuevo estado del agente, como un pareja (reward, new_state)
4. reset que restablece el ambiente a su estado inicial (en nuestro caso moviendo al agente a la posición (0, 0))
5. is_terminal que termina si está en el estado final o no. en nuestro caso el estado final estará determinado por la casilla con recompensa igual a 1.
gridworld_env.py
class Environment:
def __init__(self, n):
#as before
def get_current_state(self):
"""
Returns the current state of environment
"""
abstract
def get_possible_actions(self, state):
"""
Returns possible actions the agent
can take in the given state. Can
return the empty list if we are in
a terminal state.
"""
abstract
def do_action(self, action):
"""
Performs the given action in the current
environment state and updates the environment.
Returns a (reward, nextState) pair
"""
abstract
def reset(self):
"""
Resets the current state to the start state
"""
abstract
def is_terminal(self):
"""
Has the environment entered a terminal
state? This means there are no successors
"""
abstract
© - Derechos Reservados: La presente obra, y en general todos sus contenidos, se encuentran protegidos por las normas internacionales y nacionales vigentes sobre propiedad Intelectual, por lo tanto su utilización parcial o total, reproducción, comunicación pública, transformación, distribución, alquiler, préstamo público e importación, total o parcial, en todo o en parte, en formato impreso o digital y en cualquier formato conocido o por conocer, se encuentran prohibidos, y sólo serán lícitos en la medida en que se cuente con la autorización previa y expresa por escrito de la Universidad de los Andes.
De igual manera, la utilización de la imagen de las personas, docentes o estudiantes, sin su previa autorización está expresamente prohibida. En caso de incumplirse con lo mencionado, se procederá de conformidad con los reglamentos y políticas de la universidad, sin perjuicio de las demás acciones legales aplicables.
Recursos Digitales
Nicolás Cardozo, Profesor Asociado
Camilo Cabrera, Tutor
Facultad de Ingeniería
Departamento de Ingeniería de Sistemas y Computación
Universidad de los Andes
Bogotá, Colombia
Enero, 2023