En este tutorial nos concentraremos en construir un agente de Q-learning basados en el desarrollo de los laboratorios anteriores (en especial SARSA).
La base de los agentes de aprendizaje por refuerzo (i.e., utilizando el algoritmo de Q-learning) es la ecuación de Belman
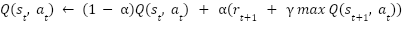
La creación del agente de Q-learning tiene dos partes, la definición del ambiente y la definición del agente. Estos dos interactúan en un ciclo de refuerzo por medio de las recompensas otorgadas por el ambiente (ambiente -> agente) y las acciones ejecutadas por el agente (agente -> ambiente).
Para la construcción del ambiente, nos basaremos en el ambiente de Gridworld al igual que hemos trabajado en laboratorios anteriores. Sin embargo, la funcionalidad del ambiente será lo suficientemente general para permitir que la construcción de nuevos ambientes únicamente requiera hacer pequeñas modificaciones sobre la funcionalidad ya implementada.
Estructura del ambiente
El ambiente está definido por sus estados, los cuales se representan como una lista n-dimensional que captura las características y relaciones entre los estados. El ambiente debe recibir la definición de los estados. Usualmente se utiliza una lista de una dimensión para cada uno de los tipos de estados en el ambiente. Uniendo todos estas listas, se obtiene una matriz deformada de tamaño cantidad_tipos_estados x numero_estados_por_tipo,como se muestra a continuación, donde el superíndice indica el tipo del estado.
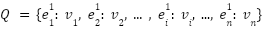

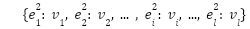
...
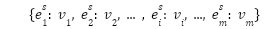
En el caso específico de Gridworld, los estados se definen como un plano delimitado por sus dimensiones (i.e., las filas y columnas de la cuadrícula que determina el tablero). En la implementación a continuación, pasamos al ambiente la definición del tablero que se utiliza para definir los estados con su tipo y valor de recompensa. Como tal, el tablero define a Gridworld directamente, que es la información que debemos guardar dentro de la variable states, en este caso una lista de dos dimensiones.
Adicionalmente, el ambiente debe mantener la información de cuál es el estado inicial del ambiente (si este es fijo a través de los episodios) y cuál es el estado actual en el que se encuentra el agente.
Finalmente, es posible que el ambiente tenga la información de las acciones a ejecutar en los estados. Es común tener esta información dentro del ambiente si los estados uniformemente pueden usar las mismas acciones. De lo contrario, esta información se debe calcular para cada estado. Teniendo en cuenta que en Gridworld todos los estados ejecutan las mismas acciones (excepto los estados finales), mantendremos la variable de acciones por facilidad.
La definición de la estructura del ambiente se muestra a continuación
class Environment:
def __init__(self, board):
self.nrows, self.ncols = len(board),len(board[0])
self.states = [[0 for _ in range(self.ncols)] for _ in range(self.nrows)]
self.initial_state = None
for i in range(len(board)):
for j in range(len(board[0])):
if board[i][j] == 'S':
self.initial_state = (i,j)
elif board[i][j] == "#":
self.states[i][j] = None
elif board[i][j] != ' ':
self.states[i][j] = int(board[i][j])
self.current_state = self.initial_state
self.actions = ['left', 'right', 'up', 'down']
Comportamiento del ambiente
El ambiente tiene tres responsabilidades principales, determinar el estado actual del ambiente (get_current_state), determinar las acciones a ejecutar en un estado particular (get_possible_actions) y ejecutar una acción tomada por el agente (do_action).
Estado del agente en el ambiente
Como se mencionó anteriormente, el ambiente debe llevar el estado actual del agente dentro del ambiente, dado que esta información es necesaria para poder ejecutar una acción y ver su efecto.
La implementación de la función get_current_state es directa, retornando el valor almacenado por el agente.
Acciones de un estado
La función para determinar el conjunto de acciones posibles para un estado estado se define retornando un conjunto de acciones (conocidas para el ambiente) de acuerdo al estado. Este valor debe ser calculado independientemente para cada estado.
Como se mencionó anteriormente, en el caso de Gridworld (y para otros ambientes que utilicen un conjunto uniforme de acciones) es posible mantener el valor de dichas acciones como un atributo del ambiente. En el caso de Gridworld, queremos retornar el conjunto de acciones almacenado para todos los estados que no son finales. Los estados finales únicamente tendrán una acción especial, end, utilizada para determinar el fin del episodio.
def get_possible_actions(self, state):
if self.is_terminal(state):
return ['end']
return self.actions Aplicación de las acciones
Cuando el agente se encuentra en un estado, debe ejecutar una acción para dicho estado. Más adelante discutiremos el proceso de escogencia de las acciones. En este momento nos preocuparemos del efecto que tiene efectuar una acción en el ambiente. El movimiento de las acciones dentro del ambiente está determinado por la acción dada y el factor de ruido en el ambiente. La ejecución de la acción nos llevará a un nuevo estado, con una recompensa, teniendo en cuenta la función de probabilidad del ruido.
Por simplicidad, en la implementación del ambiente de Gridworld no utilizaremos la función de ruido (i.e., todas las acciones son determinísticas). Como se muestra a continuación, la ejecución de las acciones utiliza una función auxiliar (get_next_state) que realiza el cálculo del nuevo estado a partir de un estado dado y una acción. El comportamiento de esta función es específico de cada ambiente, teniendo en cuenta los estados y acciones definidas. Para el caso de Gridworld se debe tener en cuenta el movimiento del agente contra las paredes u obstáculos, que deja al agente en el mismo estado en el que inició.
def do_action(self, action):
return self.get_next_state(self.current_state, action)
def get_next_state(self, state, action):
i, j = state
reward = 0
done = False
if self.is_terminal(state):
reward = self.states[i][j]
done = True
elif action == 'left' and j > 0 and self.states[i][j-1] != None:
j -= 1 # (i,j) = noise(state, action)
elif action == 'right' and j < self.ncols - 1 and self.states[i][j+1] != None:
j += 1
elif action == 'down' and i < self.nrows -1 and self.states[i+1][j] != None:
i += 1
elif action == 'up' and i > 0 and self.states[i-1][j] != None:
i -= 1
self.current_state = (i, j)
return reward, self.current_state, done Funciones auxiliares
El ambiente tiene distintas funciones auxiliares para simplificar el comportamiento del agente, esta son:
reset, que lleva al agente al estado inicial. Esta función se utiliza cuando se finaliza un episodio, para volver a ejecutar el agente.is_terminal, que determina si un estado es final o no. Esta función es específica del ambiente y su comportamiento se debe implementar para cada ambienteplotyplot_actionson funciones para visualizar los estados del ambiente, con sus valores y acciones respectivamente.
La implementación del agente tiene un comportamiento básico, ejecutar el ciclo de refuerzo con el ambiente durante un número dado de episodios.
Cada iteración del ciclo de refuerzo incluye (1) el agente toma una acción, (2) la ejecuta en el ambiente, (3) recibe la recompensa y actualiza sus valores. A continuación presentamos la estructura y el comportamiento del agente.
Estructura del Agente
Los agentes de Q-learning, de forma similar al método de SARSA generan un mapa asociando los valores obtenidos de ejecutar cada una de las acciones posibles en cada estado, la tabla de Q-valores (qtable). El proceso de la actualización de valores requiere de los tres parámetros de aprendizaje: el factor de descuento γ, la tasa de aprendizaje α y el factor de exploración ε
class Agent:
def __init__(self, env, gamma=0.9, alpha=0.1, epsilon=0.9, episodes=1):
#hyper parameters
self.alpha = alpha
self.gamma = gamma
self.epsilon = epsilon
self.environment = env
self.qtable = self.__initdic__() #rewards table
self.episodes = episodes
def __initdic__(self):
table = dict()
# Initialize Q table with 0 for each state-action pair
for state in self.environment.get_states():
table[state] = np.zeros(len(self.environment.get_possible_actions(state)))
return tableLa tabla de q-valores se inicializa con todos los valores en cero, dado que no tenemos ningún tipo de información sobre el agente. La tabla tiene dimensiones número de estados x número de acciones por cada estado.
Comportamiento del agente
El comportamiento principal del agente está dado por la función run, que ejecuta la interacción con el ambiente por la cantidad de episodios definidos.
La función run ejecutará la cantidad de episodios definidos para el agente (durante el entrenamiento), ejecutando cada episodio hasta alcanzar el estado final. Dentro de cada operación, el agente debe escoger una acción a ejecutar. Este proceso sigue la técnica de epsilon decay, tomando una acción aleatoria con probabilidad 1-ε y ejecutando la mejor acción conocida hasta el momento con probabilidad ε. De esta forma manejamos la exploración del ambiente asegurándonos que inicialmente el agente pueda obtener valores para las distintas acciones de un estado.
def run(self):
for counter in range(self.episodes):
done = False
while not done:
current_state = copy.deepcopy(self.environment.get_current_state())
if random.uniform(0,1) < self.epsilon:
action = self.random_action(current_state)
else:
action = self.max_action(current_state)
action_index = self.action_index(action)
next_state, reward, done, info = self.step(action)
if not done:
old_value = self.qtable[current_state][action_index]
next_max = np.max(self.qtable[next_state])
new_value = (1 - self.alpha)*old_value + self.alpha*(reward + self.gamma*next_max)
self.qtable[current_state][action_index] = new_value
else:
self.qtable[current_state][action_index] = reward
if counter % 30 == 0:
self.epsilon -= self.epsilon/10
self.environment.reset()
return self.qtable
En el proceso de epsilon decay, la disminución del factor de exploración se realiza de acuerdo a la cantidad de episodios a ejecutar, teniendo en cuenta el tamaño del ambiente. En este caso disminuimos cada 30 episodios (si se ejecutan 1000 episodios). La disminución del factor de exploración es de 10%
El segundo paso en la ejecución del ciclo de refuerzo es la ejecución de la acción en el ambiente. La función step es la encargada de llevar este proceso. Esta función debe ejecutar la acción escogida en el ambiente y obtener el nuevo estado. El ambiente también debe encargarse de retornar la recompensa encontrada de ejecutar esta acción.
def step(self, action):
old_state = copy.deepcopy(self.environment.get_current_state())
reward, new_state, done = self.environment.do_action(action)
next_state = copy.deepcopy(new_state)
info = f'Executed action: {action} at state {old_state} getting reward {reward}'
return next_state, reward, done, infoFinalmente se realiza la actualización de los valores de la Q-tabla siguiendo la fórmula de la ecuación de Bellman
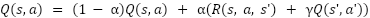
Funciones auxiliares
La funcionalidad básica del agente utiliza diferentes funciones auxiliares para simplificar la implementación. Estas son:
max_action, que retorna la acción con mayor valor registrado para el estado actualaction_name, que retorna el nombre de una acciónaction_index, que dado el nombre de una acción retorna su índice dentro del mapa de acciones posiblesrandom_action, que dado un estado, selecciona aleatoriamente la acción a ejecutar dentro de las acciones disponibles para el estado dado
El proceso de Q-learning que seguimos se utiliza como una tipo de entrenamiento del agente, es decir, los episodios que toma converger a una política óptima por medio de la exploración del agente. Una vez se alcanza dicha política, el conocimiento del agente puede ser utilizado dentro de cualquier agente (que utilice el mismo ambiente).
Para ello, es posible implementar dos funciones, save_qtable y load_qtable, que respectivamente se encargan de persistir la Q-tabla del agente y luego cargar la información de los estados y acciones del agente
def save_qtable(self):
f = open("qtable.txt", "w")
print(self.qtable)
for elem in self.qtable:
print(elem)
f.write(f"{elem}:")
for v in self.qtable[elem]:
f.write(str(v) + ",")
f.write('\n')
f.close()Al cargar el nuevo agente, este se debe ejecutar con un factor de exploración muy pequeño, para que el agente explote la política encontrada lo más posible.
def load_qtable(self):
f = open("qtable.txt", "r")
#print(f.read())
for line in f:
state, actions = line.split(":")
parts = state[1:-1].split(",")
tuple = (int(parts[0]), int(parts[1]))
actions = actions[0:-2].split(",")
l = []
for v in actions:
l.append(float(v))
self.qtable[tuple] = np.asarray(l)
f.close()© - Derechos Reservados: La presente obra, y en general todos sus contenidos, se encuentran protegidos por las normas internacionales y nacionales vigentes sobre propiedad Intelectual, por lo tanto su utilización parcial o total, reproducción, comunicación pública, transformación, distribución, alquiler, préstamo público e importación, total o parcial, en todo o en parte, en formato impreso o digital y en cualquier formato conocido o por conocer, se encuentran prohibidos, y solo serán lícitos en la medida en que se cuente con la autorización previa y expresa por escrito de la Universidad de los Andes.
De igual manera, la utilización de la imagen de las personas, docentes o estudiantes, sin su previa autorización está expresamente prohibida. En caso de incumplirse con lo mencionado, se procederá de conformidad con los reglamentos y políticas de la universidad, sin perjuicio de las demás acciones legales aplicables.
Recursos Digitales
Nicolás Cardozo, Profesor Asociado
Facultad de Ingeniería
Departamento de Ingeniería de Sistemas y Computación
Universidad de los Andes
Bogotá, Colombia
Enero, 2023