¿Qué aprenderá?
- El uso de la herramienta Mono2Micro que propone particiones funcionales de una app legada, a fin de apalancar la construcción de vistas funcionales requeridas para definir el alcance y la arquitectura to-be de un proyecto de modernización
¿Qué hará?
- Se estudiará el ejemplo de DayTrader y las visualizaciones obtenidas en Mono2Micro para construir vistas funcionales y diseñar la arquitectura to-be aplicando patrones de microservicios
¿Cuáles son los prerrequisitos?
- Haber desarrollado el tutorial de Mono2Micro para cartografía
- Conocimientos teóricos sobre monolitos
- Conocimientos teóricos sobre microservicios
Inicio 2
Contexto 2
Rearquitectura de un monolito a microservicios 2
Identificación y definición de los servicios 3
Diseño de la arquitectura 3
Patrones de comunicación 4
Patrones de acceso 4
Patrones de manejo de datos 4
Patrones de despliegue 5
Prácticas transversales 5
Estrategia del tutorial 6
Delimitar el alcance 7
Documentación de arquitectura 7
Listado de requisitos 8
Identificar y definir los servicios 10
Diseñar la arquitectura to-be 13
Cierre 16
Créditos-Versión 1.0 17
Material de consulta complementario 17
Rearquitectura de un monolito a microservicios
En aplicaciones de gran envergadura, la rearquitectura de un monolito a microservicios es un proceso complejo que requiere trabajo y planificación cuidadosa. Cada aplicación monolito es única y puede requerir de un enfoque diferente para realizar su modernización. En general, lo recomendable es hacer la modernización de forma incremental con el fin de garantizar que todos los componentes del sistema funcionen perfectamente y sean compatibles con las funcionalidades esperadas en producción. Esta refactorización incremental es conocida en la industria como "Strangler Pattern".
Antes de realizar una planeación para la modernización, lo más importante es conocer el monolito desde una perspectiva técnica y de negocio. Si comprendemos cuál es el funcionamiento actual de la aplicación e identificamos las diferentes partes del sistema, sus interacciones, dependencias y requerimientos de calidad, nos será más fácil pensar en cuáles son los microservicios en los que deberíamos dividir nuestro monolito, identificar qué partes del código podemos reutilizar, qué partes del código debemos refactorizar y qué servicios o partes de nuestra nueva arquitectura deben ser construidos desde cero.
El proceso de dividir una aplicación en microservicios se conoce en la industria como "Assemblage", se divide en tres pasos generales: el primero, corresponde a la definición de los servicios, el segundo, al diseño de una arquitectura para el sistema, y el tercero, a la implementación incremental de nuestra nueva arquitectura. En las siguientes subsecciones hablaremos de los pasos 1 y 2 de una forma más detallada. El paso 3 se trabajará más adelante.
Identificación y definición de los servicios
Una vez que entendemos la aplicación tanto técnica como funcionalmente, nos será más fácil identificar los servicios en los que se puede separar el sistema. Es necesario tener información sobre los requerimientos funcionales y no funcionales, casos de uso de la aplicación e interfaces gráficas de la misma para lograr realizar una identificación que se ajuste a las necesidades del sistema. La identificación de los servicios, como vimos en el tutorial de cartografía en Mono2Micro, puede ser apoyada por herramientas automatizadas, cuyo análisis nos sugiere particiones a partir de las dependencias funcionales y técnicas encontradas en el código.
Para identificar los servicios en los que podemos dividir un monolito, debemos comenzar por agrupar componentes que se relacionan de alguna manera, ya sea por su funcionalidad o sus requerimientos funcionales, y que, por ende, pueden ser desarrollados y desplegados de forma independiente de los demás. Es de gran ayuda comenzar por generar una lista de las operaciones (o funcionalidades) soportadas dentro del monolito para agruparlas en subdominios. Algunos subdominios serán lo suficientemente grandes o desacoplados de otros para ser un microservicio independiente y otros podrán agruparse para formar un microservicio. Si seguimos estos pasos de identificar operaciones, agrupar operaciones en subdominios y agrupar subdominios para ser candidatos a servicios, lograremos llegar a una definición de microservicios destino de nuestro sistema.
Diseño de la arquitectura
La definición de la arquitectura destino para una modernización de monolito a microservicios implica varios aspectos importantes que deben ser considerados cuidadosamente. En primer lugar, es importante definir los límites para cada uno de los microservicios candidatos que se crearán. Como vimos en la sección anterior, los límites pueden ser definidos por el dominio de negocio o por características funcionales, pero también, pueden ser definidos por requerimientos no funcionales como escalabilidad, desempeño, entre otros. Lo importante es definir microservicios independientes y que puedan ser escalados y actualizados sin afectar a otros componentes del sistema.
El primer paso para definir la arquitectura, a partir de la lista de microservicios del paso anterior, es determinar cómo se comunicarán los microservicios entre sí. Para ello, se pueden utilizar diferentes patrones para resolver retos de comunicación, acceso, manejo de datos, despliegue, etc. que enunciaremos a continuación (esto no pretende ser una lista exhaustiva de patrones de microservicios sino un panorama general de algunos existentes):
Patrones de comunicación
RPC (Remote Procedure Call): Un patrón de comunicación que permite que un proceso en un microservicio invoque una función o un método en otro microservicio de forma remota. Las solicitudes se envían en un formato de mensaje específico y se espera una respuesta en un formato similar. Es un patrón que favorece el rendimiento pero desfavorece la escalabilidad y la portabilidad debido a su fuerte integración entre los sistemas en donde es implementado. Una forma de implementar RPC es a través de REST.
Mensajería pub/sub: En este patrón los microservicios se comunican a través de mensajes que se envían de forma asincrónica a una cola. Este patrón permite una mayor tolerancia a fallos, ya que los mensajes se almacenan en una cola hasta que el destinatario está disponible para procesarlos y debido a su naturaleza asincrónica es altamente escalable. Además, es fácil de integrar en diferentes plataformas y lenguajes de programación. La mensajería asincrónica puede ser menos accesible y menos interoperable que otros patrones debido a la complejidad del enrutamiento de mensajes y la necesidad de implementar colas de mensajes.
Patrones de acceso
API Gateway: Un patrón de comunicación que se utiliza para exponer un conjunto de microservicios como una única API. El gateway actúa como un punto de entrada único para los clientes que acceden a la plataforma pero internamente agrega información de diferentes microservicios para poder retornar una respuesta completa a los clientes. El API Gateway es seguro y accesible, lo que lo hace adecuado para plataformas que necesitan una capa de seguridad adicional. Además, es altamente escalable y fácil de integrar con diferentes plataformas y lenguajes de programación. El API Gateway puede ser menos eficiente y menos confiable que otros patrones debido a la necesidad de enrutar solicitudes a través de un gateway central y tener que llamar internamente otros servicios para agregar información y retornar una respuesta.
Circuit Breaker: Es un patrón que se utiliza para evitar una cascada de fallos en caso de que un microservicio falle. Un Circuit Breaker monitorea el estado de un microservicio y, si detecta que ha fallado, evita que se realicen solicitudes adicionales hasta que se haya recuperado. Es un patrón altamente tolerante a fallos y confiable, lo que lo hace adecuado para plataformas de alta disponibilidad, pero puede ser menos eficiente ya que es necesario monitorear el estado de los microservicios.
Patrones de manejo de datos
Otro punto a tener en cuenta es definir la forma en que se gestionarán las bases de datos de los microservicios. Una opción es tener una base de datos compartida para todos los microservicios (shared database), lo que es fácil de implementar y genera menos costos, pero que a su vez puede generar problemas de dependencias y dificultar la escalabilidad ya que la base de datos se convierte en un cuello de botella en el sistema. Otra opción, más recomendada, es tener una base de datos por microservicio (single database), lo que aumenta la independencia y la escalabilidad del sistema, pero puede generar problemas de consistencia, complejidad en la gestión y aumento en los costos de infraestructura.
Patrones de despliegue
Contenedores: Los microservicios pueden ser empacados en contenedores, como Docker, que permiten ejecutar aplicaciones de manera independiente del sistema operativo anfitrión. Los contenedores ofrecen una gran portabilidad, flexibilidad y escalabilidad, ya que se pueden ejecutar en cualquier plataforma que soporte Docker y varios contenedores pueden ejecutarse en un mismo servidor anfitrión.
Orquestación de contenedores: Esta forma de despliegue se basa en la utilización de una herramienta de orquestación de contenedores, como Kubernetes o Docker Swarm, para administrar y automatizar la implementación, el escalamiento y la gestión de los contenedores. La orquestación de contenedores, favorece la escalabilidad, la disponibilidad y la tolerancia a fallos de los microservicios ya que las herramientas como Kubernetes, permiten escalar los microservicios de forma automatizada y garantizan la alta disponibilidad de los mismos, lo que mejora la tolerancia a fallos.
Funciones sin servidor (Serverless Functions): En este enfoque, los microservicios se ejecutan en una plataforma de computación sin servidor, como AWS Lambda, Google Cloud Functions o Microsoft Azure Functions. Este tipo de funciones permiten la ejecución de código en respuesta a eventos específicos, como solicitudes de API, y no requieren la gestión de servidores o infraestructura. Las funciones sin servidor favorecen la escalabilidad, la flexibilidad y la reducción de costos ya que se paga por las ejecuciones y no por servidor, pero puede desfavorecer la portabilidad ya que algunas de ellas están atadas a los servicios de los proveedores de nube.
Prácticas transversales
A continuación, describimos algunas prácticas transversales que pueden facilitar la gestión de los microservicios en producción:
Monitorear el rendimiento: Es importante monitorear el rendimiento de los microservicios para asegurar que todos están funcionando correctamente. Se deben establecer formas de monitorear los logs de las aplicaciones, así como también definir métricas y alertas para detectar problemas de rendimiento o errores.
Automatizar los despliegues: Contar con un proceso automatizado para el despliegue y configuración de servicios es importante. Como vimos en los patrones de despliegue, estos procesos pueden ser apoyados con ayuda de herramientas de orquestación de contenedores, como Kubernetes, Docker Swarm o Amazon ECS.
Escalado automático: Cuando la aplicación lo requiere, escalar automáticamente según diferentes factores puede ser importante para soportar la carga en momentos esperados o inesperados. En aplicaciones de transporte por ejemplo, los horarios pico de la mañana y la tarde son puntos de mayor carga para los sistemas inteligentes de transporte, por lo que sería importante tener un mecanismo que escale automáticamente para atender la carga, mientras que otros sistemas como los de venta de boletos para eventos, pueden requerir escalado sólo en momentos específicos en los que se abre la venta para un evento muy demandado por lo que se puede configurar un escalado automático para los microservicios en función de la demanda de los usuarios. Las herramientas de orquestación de contenedores mencionadas anteriormente también permiten la configuración de un escalado automático.
Estrategias de recuperación: Para aplicaciones críticas, en donde la disponibilidad es un factor importante, es crucial tener estrategias de recuperación en caso de que los microservicios fallen en producción. Esto puede incluir la configuración de planes de contingencia y redundancia en caso de que uno o varios microservicios presenten errores y dejen de funcionar.
Seguridad: Si se está trabajando con información sensible, se debe garantizar que los microservicios estén protegidos de posibles ataques. La implementación de políticas de seguridad, como autenticación y autorización, o la configuración de "firewalls" a la hora de intentar acceder a los microservicios, son algunos de los mecanismos que podemos usar para hacer de nuestro ambiente de despliegue un lugar seguro.
Servicios en la nube: Los proveedores de servicios en la nube, como Amazon Web Services (AWS) y Microsoft Azure, ofrecen una variedad de servicios que permiten el despliegue y la gestión de microservicios. AWS tiene por ejemplo el Elastic Beanstalk que simplifica el despliegue de aplicaciones web, mientras que Azure Service Fabric es un marco que permite el despliegue y la gestión de aplicaciones escalables y de alta disponibilidad. En general, muchos de los servicios en la nube tienen soporte para apoyar la escalabilidad, la disponibilidad y la seguridad de los microservicios.
La arquitectura destino de una modernización de monolito a microservicios debe ser definida cuidadosamente teniendo en cuenta las necesidades del proyecto, es importante conocer cuáles son los atributos de calidad esperados para escoger los patrones y prácticas conducentes a un mejor diseño de la arquitectura to-be. En el diseño se pueden usar uno o más de los patrones y prácticas mencionadas.
En este tutorial analizaremos el proceso y las decisiones tomadas para definir una arquitectura to-be para DayTrader. Comenzaremos hablando de la arquitectura actual de la aplicación, sus operaciones y dominios, para luego pasar a la identificación y definición de servicios, apoyados en los resultados obtenidos durante el tutorial de cartografía en Mono2Micro. Finalmente, definiremos una arquitectura to-be en donde se emplean varios de los patrones mencionados en el contexto.
Como lo vimos en el video conceptual de la semana para delimitar el alcance se usa no sólo la cartografía, sino también la documentación de arquitectura (si la hay) y el listado de requisitos del legado. En esta sección revisaremos estos aspectos de DayTrader.
Documentación de arquitectura
Como ya hemos visto anteriormente, DayTrader está desarrollado en una arquitectura de tres capas que se ilustra en la figura que sigue. De forma general las capas de la aplicación son:
- La capa web, que se compone de Servlets y JSPs.
- La capa de lógica empresarial, que se compone de beans de sesión en Java que proporcionan la lógica de negocios de DayTrader.
- La capa de acceso a datos, que se compone de beans de entidad en Java que proporcionan el acceso a la base de datos DayTrader.

Figure 1: Arquitectura de DayTrader[1]
Listado de requisitos
Como explicamos dentro del contexto, una de las formas de identificar subdominios, dominios y servicios candidatos, es a través de una lista de requisitos (u operaciones) ofrecidas por el sistema. En general, dentro de DayTrader podemos realizar operaciones de compra y venta de activos financieros. Los conceptos centrales dentro de la aplicación son Orden, Cotización y Posición. Estos conceptos pueden ser resumidos de la siguiente manera:
- Una orden ("Order" en inglés) es una operación para comprar o vender un activo financiero, como por ejemplo acciones.
- Una cotización ("Quote" en inglés) es el precio actual de compra o venta de un activo financiero en un mercado específico. Los traders pueden usar cotizaciones para determinar el precio al que desean realizar una orden.
- Una posición ("Holding" en inglés) es el número de acciones o contratos que un trader posee actualmente en un activo financiero determinado. Los traders pueden mantener posiciones largas (comprando un activo) o cortas (vendiendo un activo pronto) en función de sus expectativas sobre la dirección futura del precio del activo.
Además de las operaciones de trading, DayTrader cuenta con la posibilidad de autenticación de usuarios, perfiles de usuario y la posibilidad de ver algunas estadísticas del mercado. En la siguiente tabla se encuentra una lista de las operaciones de DayTrader:
Operación | Subdominio | Dominio |
login | Account | Account |
logout | Account | Account |
buy | Order | Order |
sell | Order | Order |
getMarketSummary | MarketSummary | Portfolio |
queueOrder | Order | Order |
completeOrder | Order | Order |
cancelOrder | Order | Order |
orderCompleted | Order | Order |
getOrders | Order | Order |
getClosedOrders | Order | Order |
createQuote | Quote | Quote |
getQuote | Quote | Quote |
getAllQuotes | Quote | Quote |
updateQuotePriceVolume | Quote | Quote |
getHoldings | Holding | Portfolio |
getHolding | Holding | Portfolio |
getAccountData | Account | Account |
getAccountProfileData | AccountProfile | Account |
updateAccountProfile | AccountProfile | Account |
register | Account | Account |
Table 1: Clasificación de subdominio y dominio para las operaciones de DayTrader
En el tutorial de Mono2Micro, vimos cómo herramientas automatizadas pueden ayudarnos a identificar particiones. Mono2Micro nos dió dos perspectivas como sugerencia. La perspectiva de negocio toma como base los casos de uso de la aplicación y las partes del código fuente usadas en la ejecución de cada caso de uso. En esta perspectiva Mono2Micro identificó 5 particiones para DayTrader como se puede observar en la siguiente captura.

En cambio, la perspectiva por similitudes naturales muestra cómo se relacionan los componentes del sistema y cuál sería una división adecuada usando las dependencias directas e indirectas del código fuente tal cual como está escrito (ver siguiente captura).

Como se puede observar en las dos capturas presentadas anteriormente las perspectivas de Mono2Micro sugieren particiones diferentes; sin embargo, algo que ambas vistas comparten es que no lograron asignar 70 de las clases dentro de una participación específica (aparecen en las capturas como "unobserved"), ya sea porque el código no fue llamado en nuestra ejecución de casos de uso o porque corresponde a código muerto. Por otro lado, las particiones sugeridas se centran en colocar las operaciones principales de DayTrader (ver cotizaciones, comprar, vender, ver posiciones, etc.) dentro de una única partición. Debemos entender que Mono2Micro es una herramienta que nos ayuda a dividir el monolito en particiones usando el código fuente tal como está escrito, sugiriendo módulos funcionales que pueden ser creados a partir del código legado, por lo cual, en aplicaciones con alto acoplamiento, puede dar sugerencias en donde la mayor parte de los módulos van a una misma partición. Si tomamos como punto de partida las sugerencias de Mono2Micro, podríamos pensar en definir la vistas funcionales como se muestra en la siguiente gráfica:

Es decir, una partición con la capa web de la aplicación (referida en la captura anterior como "web"), otra partición con todas las operaciones de trading usando EJBs (partition-1), otra con clases con conexión directa a JDBC ("partition-2"), y una última con componentes relacionados a mensajería ("partition-3"). Esta primera iteración de (re)diseño nos da un punto de partida, pero en nuestro caso vamos a ir un poco más allá: vamos a utilizar el patrón de microservicios "descomposición por subdominios" para rearquitecturar la aplicación. Este patrón sigue dos principios:
- Responsabilidad única, que al aplicarlo a la arquitectura diría que se ponen en un mismo módulo un conjunto pequeño de funciones fuertemente relacionadas.
- Clausura común (o Common Closure en inglés), que al aplicarlo a las particiones diría que dos o más clases que cambian por la misma razón deben estar en el mismo módulo. Por ejemplo, clases que implementen diferentes aspectos de la misma regla de negocio. El objetivo es tratar de que cada cambio sólo impacte a un servicio
Si aplicamos estos dos principios al listado de las operaciones del legado tendríamos las siguientes decisiones en cuanto a servicios (ver figura que sigue):
- DayTrader permite que los usuarios puedan registrarse, hacer login y logout con la cuenta del sistema, además de contar con un perfil de usuario, por lo cual, hace sentido crear un servicio que se encargue de manejar las cuentas de usuario al que denominaremos "Account Service".
- En la aplicación, los usuarios pueden comprar y vender activos financieros, mediante operaciones de compra y venta que envuelven dos entidades, cotizaciones ("Quotes") y número de acciones/contratos ("Holdings") que un usuario posee de un activo financiero. Los "Quotes" corresponden al precio actual de un activo financiero en el mercado y son usados como referencia para órdenes de compra, por lo que en nuestro diseño, crearemos un servicio encargado de manejar esta entidad del dominio y lo llamaremos "Quote Service". Lo mismo haremos con Holdings, crearemos un módulo cuyo objetivo sea manejar las posiciones o "Holdings" de nuestros usuarios, se denominará "Portfolio Service".
- Finalmente, dado que las Órdenes de compra y venta son las operaciones críticas del negocio, crearemos un servicio independiente que se encargará de encapsular estas funcionalidades de compra y venta llamado "Order Service". La siguiente figura muestra un diseño inicial de los servicios de la aplicación:

Figure 2: Módulos funcionales sugeridos
Cuando se diseña la arquitectura de una aplicación para hacer trading, el software debe ser implementado de forma que permita garantizar un rendimiento óptimo de las operaciones del sistema, además, debe ser una aplicación segura que proteja los datos de los usuarios, con alta disponibilidad y escalable. Como parte del ejemplo, nos enfocaremos especialmente en los atributos de escalabilidad y disponibilidad, asegurando que la aplicación sea capaz de crecer y adaptarse a medida que aumenta el número de usuarios y transacciones, pudiendo manejar un mayor volumen de operaciones sin comprometer el rendimiento. Además, el software deberá tener la capacidad de estar disponible y accesible para los usuarios en todo momento, para lo cual, debemos pensar en minimizar el tiempo de inactividad y contar con planes de contingencia para hacer frente a posibles interrupciones del servicio.
Para direccionar los atributos de escalabilidad y disponibilidad, diseñaremos una arquitectura to-be cuyo estilo sea microservicios, adicionalmente, incluiremos en el diseño los patrones API Gateway, Single Database y mensajería Pub/Sub. En el próximo párrafo justificamos esta selección de patrones.
La implementación de un API Gateway permite que se pueda implementar autenticación, autorización y políticas de seguridad de forma centralizada, lo que facilita el cumplimiento de normativas de seguridad al tener un único punto de acceso desde el exterior a nuestros microservicios. Por otro lado, la información del sistema se distribuye en los cuatro servicios definidos, pero la página web requiere información agregada para mostrar datos completos en la interfaz del usuario, al tener información alojada en diferentes servicios, el API Gateway también actuará como punto para agregar información desde diferentes servicios, pero retornando respuestas agregadas a la capa web, en este caso nuestro API Gateway también implementará funciones de API Composition (en la sección de material complementario encontrará sugerido un recurso sobre este patrón). Al tener una base de datos independiente para cada microservicio se simplifica la gestión de datos, además de permitir que los servicios puedan escalar de forma independiente según las necesidades específicas de carga y rendimiento. La mensajería Pub/Sub facilita la comunicación asíncrona entre los servicios, lo que proporciona flexibilidad, tolerancia a fallos y permite manejar situaciones de carga alta ya que es más fácil distribuir el trabajo de manera más equitativa entre los servicios.
Los usuarios de DayTrader cuentan con una interfaz web para utilizar las funcionalidades del sistema, así como Mono2Micro recomendó, vamos a crear un módulo web que contenga la interfaz gráfica de DayTrader y que acceda a los servicios ofrecidos por nuestros microservicios.
En la sección anterior definimos cuatro módulos que se encargarán de manejar los diferentes dominios del sistema. En nuestro caso los dominios no son completamente independientes, ya que las funcionalidades de nuestro sistema pueden envolver varios servicios a la vez, por ejemplo, el dominio de ordenes debe interactuar con "Quotes" para conocer el precio del mercado de un activo financiero y con "Holdings" para comprar y vender activos financieros, o también el dominio de "Account" debe estar relacionado con Holdings para conocer qué activos financieros son propiedad de un usuario. Estas interacciones entre servicios pueden dificultar el acceso a información desde la capa web, por lo que definiremos un mecanismo para acceder a la información de forma que la información retornada sea información agregada desde distintos microservicios usando un patrón de API Gateway, en donde, por un lado, nuestros servicios se esconden detrás del gateway y esté a su vez se vuelve el único punto de contacto entre la capa web y el backend; y por otro lado, el gateway a su vez se encargará de consultar y agregar información de distintos microservicios, para retornar una respuesta pertinente a la capa web.
El resultado del diseño de la arquitectura to-be se puede observar en la figura que sigue.

Figure 3: Arquitectura to-be
La figura anterior muestra la arquitectura en términos de los servicios y sus respectivas bases de datos. Vemos que la capa web se comunica directamente con el "DayTraderGatewayService" que actúa como agregador de información implementando el patrón de API Composer, siendo entonces el encargado de comunicarse con cada servicio y agregar la información para luego enviar una respuesta completa a la capa web. Cada uno de los servicios tendrá su propia base de datos. En operaciones como comprar o vender activos financieros, queremos que los procesos sean asíncronos, por lo que los servicios internamente se comunicaran a través de mensajería. Cada servicio tendrá su propia cola de mensajes SQS en donde llegarán los mensajes pertinentes para el alcance del servicio. Los servicios deben ser capaces de comunicarse cuando una orden llega al sistema, por lo que, tendremos una cola de SNS en donde se publicarán los mensajes y las colas de SQS se suscribirán al SNS para escuchar por los mensajes de su incumbencia. En la siguiente gráfica se muestra cómo los servicios consumen mensajes de las colas.

Figure 4: Arquitectura to-be Queues Consumers
En la siguiente figura se muestra cómo los servicios producen mensajes que pueden ser escuchados por otros servicios.
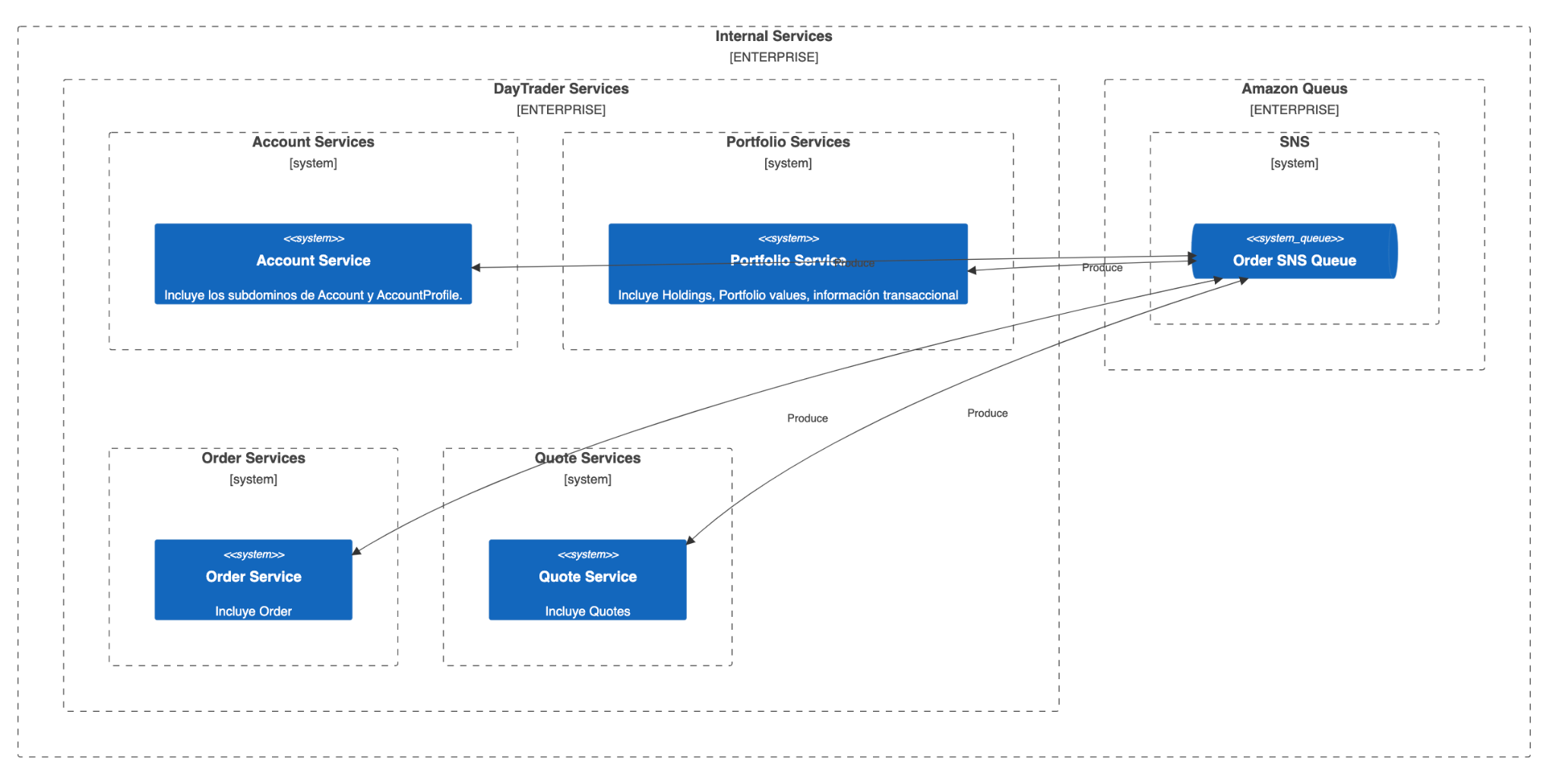
Figure 5: Arquitectura to-be Queues Producers
Este tutorial le permitió usar las visualizaciones propuestas por Mono2Micro y el listado de requisitos del sistema legado como insumo para construir las vistas funcionales como herramienta para analizar el código legado de un monolito en Java y obtener como resultado visualizaciones de los módulos candidatos en los que se puede desagregar el legado.
Kevin Sánchez, Kelly Garcés | Autores |
Miguel Angel Peña, David Valderrama | Revisores |
- Sitio web que detalla en el Strangler Fig Pattern y las mejores prácticas en su uso https://docs.aws.amazon.com/prescriptive-guidance/latest/modernization-aspnet-web-services/fig-pattern.html
- Ejemplo paso a paso de una solución apalancada en el uso del Strangler Fig Pattern https://shopify.engineering/refactoring-legacy-code-strangler-fig-pattern
- Guía de referencia de Google Cloud sobre transformación de monolitos a microservicios usando Domain Driven Design https://cloud.google.com/architecture/microservices-architecture-refactoring-monoliths
- Guía de referencia de Microsoft Azure sobre transformación de monolitos a microservicios usando Domain Driven Design https://learn.microsoft.com/en-us/azure/architecture/microservices/migrate-monolith
- Recurso sobre el patrón API Composition
https://microservices.io/patterns/data/api-composition.html
[1] http://svn.apache.org/repos/asf/geronimo/daytrader/tags/daytrader-2.2.1/assemblies/javaee/daytrader-war/src/main/webapp/contentHome.html