¿Qué aprenderá?
- En el tutorial se describe qué son los árboles de sintaxis abstracta, cómo se pueden representar en modelos y consultar para entender la estructura del código legado.
¿Qué hará?
- Se extraerá un modelo de sintaxis abstracta del código fuente de la aplicación DayTrader, usando MoDisco que es un plugin de Eclipse IDE. Luego, consultaremos el modelo usando Acceleo Query Language.
¿Cuáles son los prerrequisitos?
- Conocimientos básicos de Git
- Conocimientos de diagramas de objetos y de clases UML
Ejemplo DayTrader
En este tutorial y en otras actividades del curso usaremos como ejemplo la aplicación legado DayTrader. Por lo tanto, es importante que se familiarice con ella. DayTrader es una aplicación creada por IBM en torno al paradigma de un sistema de negociación de acciones en línea. Fue donada a la comunidad Apache Geronimo en 2005. Esta aplicación permite a los usuarios iniciar sesión, ver su cartera, buscar cotizaciones de acciones y comprar o vender acciones. La herramienta incluye controladores de carga basado en web, Mercury LoadRunner, Rational Performance Tester y Apache JMeter, lo que la hace una buena candidata para medir y comparar el rendimiento de plataformas de Java, como servidores de aplicaciones de JEE (Java Enterprise Edition) ofrecidos por diferentes proveedores.
La arquitectura de la aplicación es la siguiente:

Figure 1: Arquitectura JEE de la aplicación Day Trader
Como se muestra en la anterior figura la aplicación está diseñada bajo una arquitectura de tres capas: presentación, negocio y datos. La capa de presentación es una interfaz web hecha con servlets y JSPs (Java Server Pages). La capa de negocio y la capa de persistencia conforman la mayor parte de la aplicación. DayTrader proporciona tres implementaciones diferentes de estos servicios, correspondientes a tres patrones de diseño de aplicaciones JEE comúnmente utilizados: 1) Servlet a JDBC (Java Database Connectivity); 2) Servlet a SessionBean a JDBC; 3) Servlet a SessionBean a EntityBean. Los usuarios pueden cambiar entre estas implementaciones en la página de configuración de DayTrader cambiando el modo de tiempo de ejecución. A continuación, explicamos cada uno de estos patrones.
Patrón: Servlet a JDBC
Modo de tiempo de ejecución: Directo
La clase TradeDirect realiza operaciones CRUD (crear, leer, actualizar y eliminar) directamente en la base de datos utilizando código JDBC personalizado. Las conexiones de base de datos, las confirmaciones y las reversiones se administran manualmente en el código. Se utiliza JTA (Java Transaction API) para realizar commits a la base de datos en 2 fases.
Patrón: Servlet a SessionBean a JDBC
Modo de tiempo de ejecución: sesión directa
El bean de sesión sin estado TradeJDBC sirve como contenedor para TradeDirect. El bean de sesión asume el control de toda la gestión de transacciones, mientras que TradeDirect sigue siendo responsable de gestionar las operaciones y conexiones de JDBC. Esta implementación refleja el patrón de diseño de aplicaciones JEE más utilizado.
Patrón: Servlet a SessionBean a EntityBean
Modo de tiempo de ejecución: EJB
El bean de sesión sin estado TradeBean utiliza entity beans gestionados por un contenedor con el fin de representar los objetos de negocio. El estado de estos objetos está completamente gestionado por el contenedor EJB de los servidores de aplicaciones.
Finalmente, en la anterior figura se puede observar un componente auxiliar de mensajería JMS (Java Message Service). JMS se usa dentro de DayTrader para dos propósitos específicos: procesar órdenes de compra/venta de manera asíncrona y publicar actualizaciones de precios de cotización.
A continuación, listamos las principales funcionalidades de DayTrader:
- Registro de usuarios
- Login
- Ver cuenta / ver y actualizar perfil
- Ver portafolio
- Vender acciones (una acción es un término general utilizado para describir los certificados de propiedad de cualquier empresa)
- Ver cotizaciones y comprar acciones (una cotización es el último precio al que se negoció un activo; es el precio más reciente que acordaron un comprador y un vendedor y al cual se transó cierta cantidad del activo)
Árbol de Sintaxis Abstracta y su relación con KDM
Se conoce como ingeniería de software inversa (RE) al proceso de obtener información útil para entender la estructura y funcionamiento de los artefactos de software, por ej., código legado. Una de las representaciones más usadas para entender código fuente legado es el árbol de sintaxis abstracta o AST por sus siglas en inglés. El AST es una representación en árbol de la estructura sintáctica abstracta del código fuente escrito en un lenguaje de programación, este modelo es comparable con el modelo de árbol DOM de un archivo XML. En Java, por ejemplo, podemos hacer modificaciones sobre el AST y verlas reflejadas en el código fuente.
Los árboles de sintaxis abstracta son de gran importancia para los compiladores, ya que suelen ser el resultado de una fase de análisis de sintaxis y son una estructura más fácil de navegar que el texto del programa. En general, sirven como una representación intermedia del programa luego de varias etapas de procesamiento de un compilador y tienen un fuerte impacto en el resultado final del compilador.
En el código fuente vemos palabras reservadas, delimitadores (por ej., punto y coma al final de cada línea de código, llaves para abrir y cerrar métodos o paréntesis para especificar parámetros de funciones), identificadores, expresiones, etc. El parser procesa ese texto y escoge qué elementos se descartan (por ej., delimitadores) y qué elementos se suben al AST. El descarte se hace porque esos elementos no son necesarios para el compilador ya que hacen parte de la sintaxis y no de los elementos abstractos que son los que se traducen al lenguaje de máquina y luego se ejecutan. Por ese motivo el AST, que especifica la estructura del lenguaje, pero deja a un lado detalles de cómo se escribe el código, se convierte en una estructura de árbol adecuada para que compiladores puedan entender el código.
La información del código se puede organizar de diferentes maneras en el AST. Por ej., si utilizamos herramientas de Ingeniería Inversa Dirigida por Modelos (MDRE por sus siglas en inglés) la información del AST se encapsula en un modelo (al estilo de los diagramas de objetos de UML). MoDisco (la herramienta que usamos en este tutorial) sigue los principios de MDRE, es decir, que el resultado de hacer ingeniería inversa sobre el código son modelos. Estos modelos son conformes al Knowledge Discovery Metamodel (KDM) y al Abstract Syntax Tree Metamodel, ambos modelos estándares del Object Management Group (OMG). Por un lado, KDM representa la parte estructural del código, esto es, los artefactos de software y sus relaciones y cómo estos se organizan en agrupadores, por ej., paquetes, módulos, capas, entre otros. Por su parte, ASTM representa elementos de bajo nivel de abstracción que se mapean 1-a-1 directamente a todas las sentencia de código. Vale la pena resaltar que ASTM es una fuente de información para KDM, lo complementa. La siguiente imagen muestra un fragmento del diagrama de clases de KDM.

Figure 2: Fragmento del diagrama de clases de KDM
En el anterior modelo podemos ver que nuestro punto de entrada es la clase "Segment" que se compone de 1 o más "Model", los "Model" pueden ser de dos tipos concretos, "CodeModel" o "InventoryModel". Cada "Model" se compone de una lista de "CodeElement" que pueden ser de diferentes tipos concretos, por ejemplo "Package", "ClassUnit", "MethodUnit", "StorableUnit" o "CodeRelation". Un "CodeElement" puede contener una lista de uno o más "CodeElement". El "CodeElement" concreto "CodeRelation" define la relación entre dos "CodeElement" con dos variables, "to" y "from". Este último, es usado por ejemplo para definir imports en un programa.
En la siguiente gráfica vemos cómo sería una representación de un modelo KDM para el código del ejemplo en Java.

Figure 3: Representación en KDM del código de la clase Example
En este ejemplo vemos que el punto de entrada es un elemento de tipo "Segment", cuyo nombre es "example", dentro de su lista de "model", tiene un solo "Model" con nombre "com.example", el modelo tiene una lista de "codeElement", en este caso con un único "CodeElement" de tipo Package y nombre "com". El package "com" tiene a su vez una lista de codeElement" con un único "Package" con nombre "example", éste a su vez contiene un "ClassUnit" con nombre "Example" que dentro de su lista de "codeElement" tiene un elemento de tipo "MethodUnit".
El modelo KDM como medio de representación de la información presente en el código sirve como una manera de entender el estado AS-IS de una aplicación como veremos durante el transcurso de este tutorial.
El tutorial inicia clonando un repositorio de código e importando ese código a un Eclipse IDE. Luego a través del plugin de MoDisco, el estudiante generará un modelo KDM (que encapsula la información del AST). Finalmente, se harán consultas sobre el modelo usando Acceleo Query Language (AQL) que es una implementación del estándar Object Constraint Language (OCL) propuesto OMG. OCL es un lenguaje declarativo (como LISP o SQL) que le permite al desarrollador decir lo que quiere recuperar de un modelo, sin necesidad de indicar un algoritmo de recorrido imperativo.
Para la ejecución de este tutorial sugerimos el uso de un Eclipse IDE versión 2023-03R, el cual es compatible con los plugins de MoDisco y Acceleo. El Eclipse IDE se puede ejecutar desde dos entornos de trabajo diferentes que describimos a continuación:
- Opción 1 - Máquina virtual: la cual cuenta con todas los pre-requisitos para que el Eclipse IDE se ejecute. El reto de esta primera opción es la configuración del virtualizador y la imagen de tal forma que ésta pueda acceder a los recursos necesarios para tener una experiencia de usuario agradable. El tutorial incluye unos lineamientos generales de configuración, sin embargo, configuraciones adicionales se pueden requerir dependiendo del sistema operativo del estudiante y los recursos disponibles de su máquina local. Estas configuraciones adicionales están fuera del alcance del laboratorio y recaen sobre el estudiante.
- Opción 2 - Máquina local: la puesta en marcha del Eclipse IDE puede tomar más tiempo comparado con el de la opción 1 ya que se debe instalar y configurar la plataforma Eclipse, luego Modisco, Acceleo y Maven sobre la máquina local. La ventaja de esta opción es que evita riesgos potenciales de incompatibilidad entre la máquina virtual y los recursos de la máquina local del estudiante. Esta opción es útil para usuarios cuyo sistema operativo es Mac y procesador es Apple.
Para este tutorial usaremos una máquina virtual Ubuntu que ya tiene instaladas las herramientas necesarias. La máquina está en un archivo con extensión ".vbox" que puede descargar desde la siguiente carpeta de OneDrive.
Para poder abrir nuestra máquina virtual, podemos usar cualquier virtualizador que soporte discos en formato vdi. Recomendamos usar Virtual Box, un virtualizador de Oracle que puede descargarse en el siguiente enlace:
https://www.virtualbox.org/wiki/Downloads
Luego de descargar procedemos a instalar Virtual Box. Cuando abra por primera vez, verá:

Aquí debe hacer clic en "Add" y abrir el archivo con extensión ".vbox" que descargó como se muestra a continuación.

Luego de haber abierto su máquina virtual, verá la información desplegada como se muestra en la siguiente captura

Es recomendable que aumente la cantidad de recursos asignados a la máquina para garantizar un flujo más rápido de este y próximos tutoriales. Para esto, debe dirigirse a "Settings" -> "System". Las dos primeras pestañas de este menú son "Motherboard" y "Processor" en donde respectivamente podrá asignar una cantidad específica de memoria RAM y de núcleos de CPU de su máquina personal a la máquina virtual.
Proceda ahora a correr la máquina virtual dando clic en "Start" en la vista que despliega la información de la máquina.
La máquina le puede pedir un inicio de sesión para el cual debe usar las siguientes credenciales:
En el escritorio de la máquina se encuentra una carpeta llamada eclipse-modeling-2022-09 (ver la siguiente captura).

Dentro de la carpeta en cuestión encontrará el ejecutable de Eclipse al que le debe dar clic para iniciar el ambiente de desarrollo.

Escoja un workspace y de clic en "Launch" (ver siguiente captura).
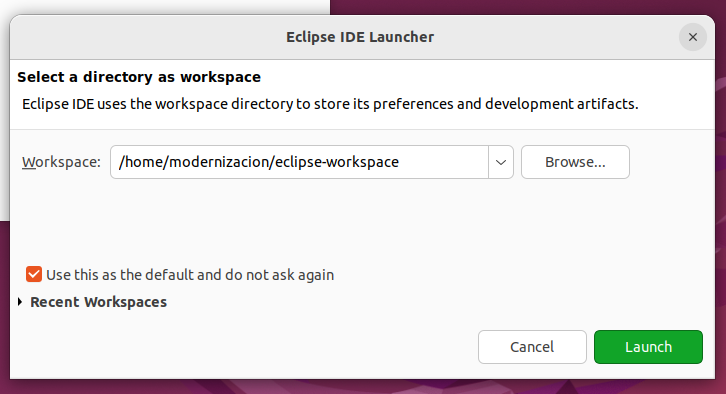
Como primer paso de esta opción requerimos instalar el Eclipse IDE Modeling Tools, teniendo en cuenta que realizaremos ingeniería inversa basada en modelos del legado. Así la versión que usaremos es la que se muestra en la captura que sigue y que está disponible en Eclipse org. Escoja la instalación correspondiente a su sistema operativo.

Una vez descargado el archivo (eclipse-modeling-xxx-xx-R-so-xx), es necesario descomprimirlo en su máquina local e ingresar a la carpeta eclipse y buscar el archivo ejecutable llamado eclipse el cual tendrá un tipo de extensión diferente para cada sistema operativo. Por ej., en Windows es eclipse.exe.
Una vez iniciado el IDE, procederemos a instalar los plugins necesarios, para lo cual nos dirigiremos al menú "Help" (Ayuda) y después debe escoger "Install new Software" (Instalar nuevo Software). Como resultado se desplegará una ventana como esta:
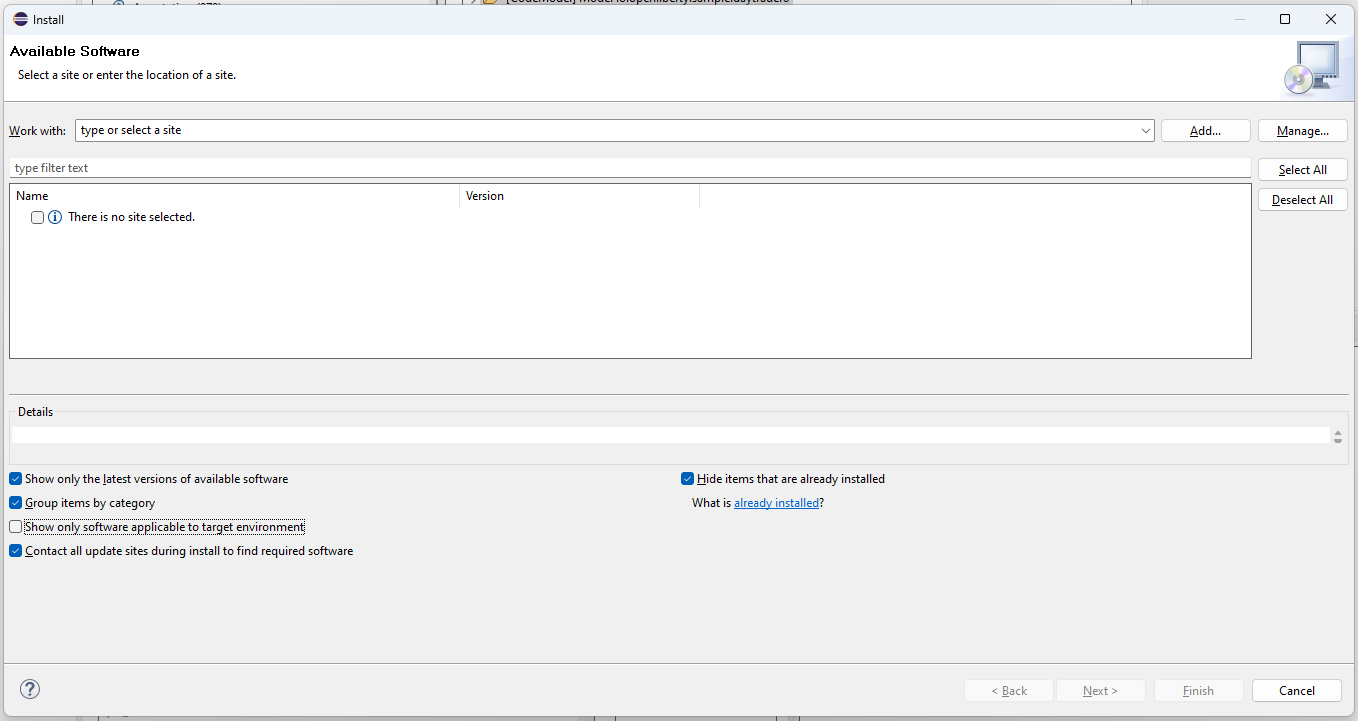
El primer paso y muy importante en este gestor de instalación es deshabilitar la opción "Show only the latest versions of available software" (Mostrar solo las últimas versiones del software disponible) que viene por defecto seleccionada, ya que el Framework MoDisco y el interpretador Acceleo tienen etiquetas de 2022. Luego en la lista desplegable "work with" escoja la opción "--All Available Sites--" (todos los Sitios Disponibles) esto refrescará los plugins disponibles. Esta operación puede tardar algunos segundos en finalizar. El resultado puede lucir como esto:
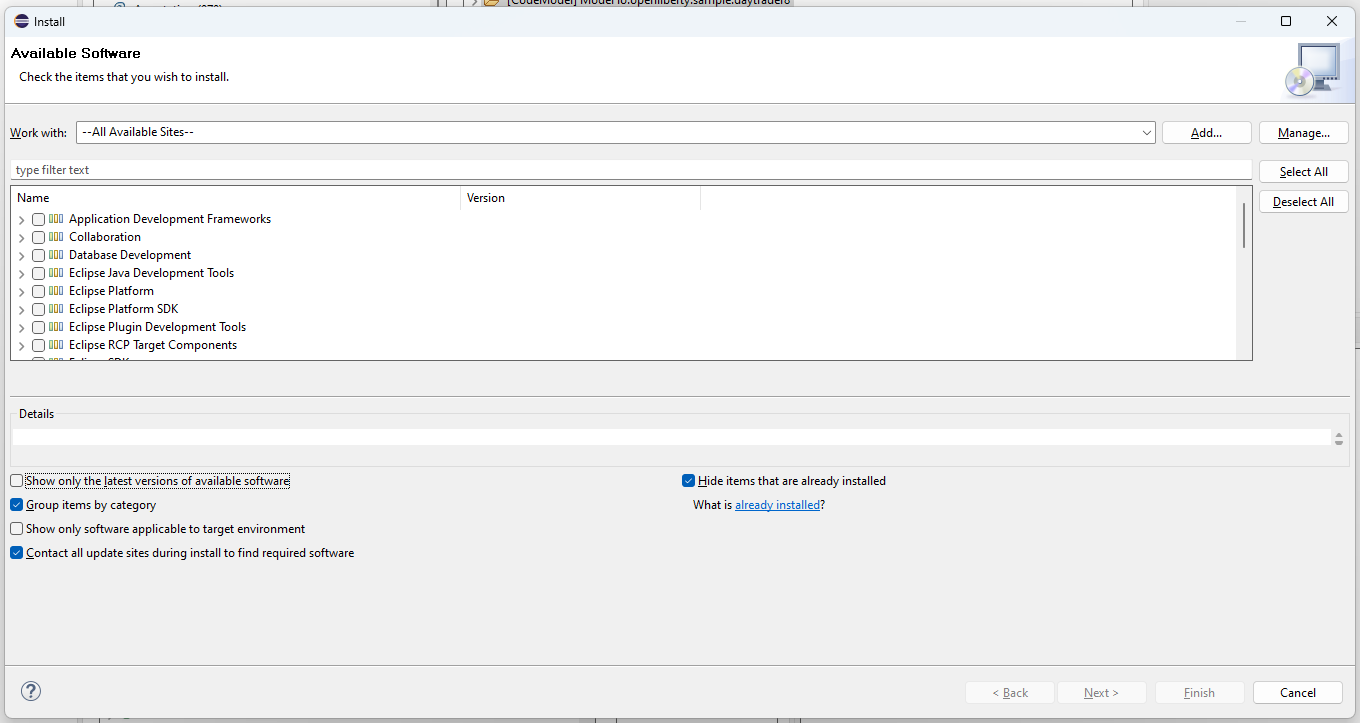
Una vez la lista esté cargada procederemos a buscar la agrupación "General Purpose Tools" (Herramientas de uso general) y dentro de esta busque la dependencia "M2E - Maven Integration for Eclipse" la cual nos permitirá trabajar con proyectos basados en Maven. Encontrada la dependencia, selecciónela. Posteriormente, buscaremos la agrupación "Modeling" (Modelado) y allí seleccionaremos el plugin "Acceleo" y más abajo "MoDisco SDK y MoDisco SDK Developer Resources".
Una vez seleccionados los recursos anteriormente descritos damos clic en "Next". Esto lanza un cálculo de árbol de dependencias, lo cual toma algunos segundos. Finalmente, revise la lista de los recursos a instalar y de clic en el botón "Finish" (Finalizar).
Lo próximo es clonar el proyecto Day Trader en su máquina desde el siguiente repositorio de Github:
https://github.com/SELF-Software-Evolution-Lab/com.uniandes.miso.daytrader.ast
Por ej., nosotros lo clonamos en el camino que sigue, pero usted puede escoger otro:
"/home/modernizacion/Downloads/com.uniandes.miso.daytrader.ast-main"
Abra Eclipse desde la máquina virtual y de clic en "File"->"Import..." como se muestra en la siguiente captura:

Seleccione "Existing Maven Project" como se muestra en la captura adjunta a continuación:

De clic en "Browse" y seleccione la carpeta del proyecto clonado (ver la siguiente captura).

Generar el modelo de KDM
De clic derecho sobre el proyecto importado y seleccione "Discovery"->"Discoverers"->"Discover KDM Code Model From Java Project" como se muestra en la siguiente captura.

Se abrirá una nueva ventana la cual tiene como función configurar el modelo a generar. Es importante seleccionar el valor "true" en la opción "SERIALIZE_TARGET" para que el modelo correspondiente quede guardado en la carpeta del proyecto (ver siguiente captura).

Navegar el KDM
Para navegar el modelo generado por MoDisco usaremos un lenguaje de navegación de modelos llamado Acceleo Query Language. Esas consultas se realizan navegando el modelo generado por MoDisco, por lo cual, es importante conocer la estructura del modelo antes de comenzar. Para ver el modelo generado podemos abrir MoDisco Model Browser, para esto damos clic derecho en el modelo "xmi" generado (ver captura siguiente).

Escogemos "Open With"->"MoDisco Model Browser".
Si detallamos el MoDisco Model Browser podemos ver como la estructura del modelo KDM se ve reflejada en el modelo obtenido a partir del código de DayTrader. Al pararnos sobre "Segment" veremos que tiene tres "Model", "model" (3), si desplegamos el árbol de "model" veremos por ejemplo que uno de esos "Model" es "io.openliberty.sample.daytrader8" y que éste a su vez tiene una lista de "CodeElement", "codeElement" (2), donde uno de ellos es un elemento de tipo "PackageUnit" llamado "com".

Ahora que entendemos que el modelo, obtenido a partir del código, contiene elementos (objetos) conformes a los tipos definidos en el modelo
, procederemos a abrir el intérprete de Acceleo para hacer algunas consultas. Para esto basta con abrir la Perspectiva de Acceleo en Eclipse, para esto, damos clic en "Window"->"Perspective"->"Open Perspective"->"Acceleo"

Esta acción habilita una vista de Acceleo Interpreter en la parte inferior de Eclipse como se ve en la captura que sigue.

Acceleo interpreter es la herramienta dentro de Eclipse que nos permitirá la especificación y ejecución de una consulta AQL. Cada expresión escrita en AQL está basada en los tipos que están definidos en un modelo dado (en este caso particular es KDM). Usaremos AQL en este tutorial para especificar consultas sobre el modelo del código fuente DayTrader, dichas consultas pueden retornar nada o algo. El resultado de la consulta se puede apreciar en la vista de Acceleo interpreter, ventana "Evaluation Result".
Para construir la expresión AQL es necesario tener claro cuál es el elemento del modelo desde donde queremos lanzar la consulta. Este punto de partida debe escogerse en la vista de MoDisco Model Browser, en el apartado de "Instances".

En la expresión nos referiremos a él como "self". En el ejemplo de la anterior figura, el punto de partida es el elemento "Segment" que básicamente representa el proyecto completo de DayTrader.
Para acceder a los atributos y relaciones de "self" escribimos un punto y luego el nombre de la característica que queremos recuperar.
Por ej., estando en el "Segment" podemos acceder al atributo "name" y a la relación "model" como se muestra a continuación:

[self.name/]
El resultado de la consulta (que aparece en la ventana "Evaluation Result") está vacío porque este "Segment" particular no tiene nombre:
En contraparte, cuando digitamos la instrucción:
[self.model/]
El resultado es el que se muestra a continuación:
![La imagen muestra el resultado de ejecutar la instrucción "[self.model/]"](img/4995687b49c8c53c.png "Resultado de ejecutar instrucción")
Parados en el mismo "Segment", podemos usar la siguiente expresión para obtener el "model" "io.openliberty.sample.daytrader8":
[self.model->select(s|s.name.equalsIgnoreCase('io.openliberty.sample.daytrader8'))/]
![La imagen muestra el resultado de ejecutar la instrucción "[self.model->select(s|s.name.equalsIgnoreCase('io.openliberty.sample.daytrader8'))/]"](img/c0b43e60a6154476.png "Resultado de ejecutar instrucción")
Además de recuperar las características de un elemento, podemos invocar después del punto (.) ciertas operaciones especiales que nos hacen la vida más fácil. Empecemos mencionando "eAllContents" la cual recorre recursivamente los subelementos contenidos por un elemento dado del modelo para encontrar todos aquellos que satisfacen una condición.
Esta operación nos puede servir para consultar cuáles son las clases que componen el "CodeModel" de "io.openliberty.sample.sample.daytrader8", es decir, retornar todos los elementos que sean de tipo "ClassUnit" dentro del paquete de "daytrader8". Si nos paramos en el "CodeModel" de io.openliberty.sample.sample.daytrader8, la expresión queda como sigue y al ejecutarla se verá:
.
[self.eAllContents(ClassUnit)/]
![La imagen muestra el resultado de ejecutar la instrucción "[self.eAllContents(ClassUnit)/]"](img/80d51307285bdde0.png "Resultado de ejecutar instrucción")
Nuestro proyecto tiene 137 clases las cuales se aprecian en "Evaluation Result".
La tabla que sigue resume algunos de los operadores más importantes de AQL (la documentación completa del lenguaje la puede encontrar en la página oficial de Eclipse Acceleo):
Operador | Descripción | Ejemplo | Resultado |
collect | Devuelve una lista con los elementos resultado de aplicar una operación en la lista. | Sequence{'a', 'b', 'c'}->collect(str | str.toUpper()) "Sequence" crea una lista conteniendo los elementos a, b y, c. Sobre los elementos de esa lista se aplica la operación toUpper (que cambia cada str a mayúscula) y el resultado se coloca en una nueva lista. El collect puede ser un análogo de una operación map, en donde a los elementos de la lista se les aplica una función que transforma todos los elementos de la lista y retorna el resultado de esa transformación en una nueva lista. En lenguajes como Typescript, podríamos escribir algo como: const list=["a","b","c"]; list.map((str)=>{return str.toUpperCase();}); | Sequence{'A', 'B', 'C'} |
count | Devuelve un entero con el número de elementos encontrados. | Sequence{'a', 'b', 'c'}->count('a') Sobre una lista creada se aplica el "count" | 1 |
excludes | Retorna un boolean indicando si el elemento no se encuentra en una lista. | Sequence{'a', 'b', 'c'}->excludes('a') | false |
exists | Retorna si existe un elemento en la lista que cumpla con la condición dada. | Sequence{'a', 'b', 'c'}->exists(str | str.size() > 5) La expresión evalúa si dentro de la lista existe un string (referidos con el nombre de variable str) cuyo tamaño sea mayor a 5. Si ese es el caso devuelve "true" sino "false" | false |
select | Retorna un Set con los elementos que cumplen con la condición. | Sequence{'a', 'b', 'c'}->select(str | str.equals('a')) La expresión escoge dentro de la lista los strings (referidos con el nombre de variable str) que sean iguales a "a". El resultado es una nueva lista que puede tener cero, uno o más elementos | Sequence{'a'} |
| Retorna true si la condición se cumple para todos los elementos o false si no. | Sequence{'a', 'b', 'c'}->forAll(str | str.equals('a')) La expresión evalúa si todos los strings de la lista son iguales a "a" | false |
selectByType | Retorna una lista de elementos del tipo dado como parámetro. | Sequence{1,2,3,'a', 'b', 'c'}->selectByType(String) La expresión devuelve los elementos de la lista que son conformes al tipo String | Sequence{'a','b','c'} |
Table 1: Operaciones populares de OCL
OCL también ofrece operaciones para comparar strings, como por ejemplo:
- equalsIgnoreCase: Retorna true si un string es igual a otro que viene como parámetro.
- contains: Retorna true si un string contiene el substring que viene como parámetro.
- startWith: Retorna true si un string comienza con el substring que viene como parámetro.
- endsWith: Retorna true si un string termina con el substring que viene como parámetro.
Ahora realizaremos una consulta un poco más compleja, pero interesante para nuestro ejemplo DayTrader. Ya sabemos que en este proyecto la capa web está conformada por artefactos que tienen en su convención de nombramiento las palabras "Servlet" y "JSF". Entonces, si quisiéramos saber cuáles son las clases concretas de la capa web tendríamos que hacer la consulta que sigue:
[self.eAllContents(ClassUnit)->select(e|e.name.contains('JSF') or e.name.contains('Servlet') )/]
![La imagen muestra el resultado de ejecutar la instrucción "[self.eAllContents(ClassUnit)->select(e|e.name.contains('JSF') or e.name.contains('Servlet') )/] "](img/635a3867627a1510.png "Resultado de ejecutar instrucción")
Vemos que tenemos 52 clases que cumplen esta condición.
Note que esta consulta tiene nuevamente como punto de partida "CodeModel" "io.openliberty.sample.daytrader8", de allí se seleccionan los elementos que son del tipo "ClassUnit" y luego se seleccionan aquellos que en su nombre contienen la cadena "JSF" o "Servlet".
Ahora, vamos a buscar los paquetes hojas dentro del modelo de "io.openliberty.sample.daytrader8". Para eso podemos ejecutar:
[self.eAllContents(Package)->select(p | p.codeElement->forAll(c | not c.oclIsTypeOf(Package)))/]
Vemos que podemos filtrar la búsqueda para el "Model" cuyo nombre es "io.openliberty.sample.daytrader8", buscando todos los paquetes donde su lista de "codeElement" no tiene ningún elemento de tipo "Package". Obtendremos la siguiente lista:
![La imagen muestra el resultado de ejecutar la instrucción "[self.eAllContents(Package)->select(p | p.codeElement->forAll(c | not c.oclIsTypeOf(Package)))/] "](img/7c0507d3632ebdf9.png "Resultado de ejecutar instrucción")
Este tutorial le permitió experimentar la ingeniería inversa de código fuente para obtener una representación (modelo) que se puede consultar para apalancar el entendimiento de las aplicaciones de software.
Kevin Sánchez, Kelly Garcés | Autores |
Miguel Angel Peña, David Valderrama | Revisores |
Carlos Castiblanco | Autores |
Kelly Garcés | Revisores |
- Explicación del uso de AST en Eclipse IDE - https://www.eclipse.org/articles/Article-JavaCodeManipulation_AST/index.html
- MoDisco Model Driven Reverse Engineering - https://www.sciencedirect.com/science/article/abs/pii/S0950584914000883
- KDM OMG specification - https://www.omg.org/spec/KDM/1.4/About-KDM