Last Updated: 2021-05-31
¿Para qué perfilar el rendimiento de una aplicación?
El perfilamiento en Android consiste en la ejecución de una serie de herramientas que generan un reporte acerca del rendimiento de una aplicación móvil. Estos reportes se exploran con el fin de identificar áreas puntuales donde la aplicación está siendo ineficiente con el manejo de recursos.
Al identificar estos puntos dentro de la aplicación, es posible realizar acciones puntuales en lugares específicos del código o del proyecto, en pro de mejorar el uso de recursos del sistema por parte de la aplicación.
¿Qué construirá?
En este tutorial no modificará el contenido de ningún proyecto, ni obtendrá un resultado tangible además de la información que le brinda Android Studio acerca del rendimiento de la aplicación.
¿Qué aprenderá?
Al desarrollar este tutorial aprenderá:
- Cómo ejecutar el perfilamiento de una aplicación Android desde el código fuente, desde Android Studio.
- Cómo interpretar las gráficas generadas por las herramientas de perfilamiento de Android Studio.
- Cómo identificar picos de uso en la ejecución de una aplicación Android.
¿Qué necesita?
- JDK 8 actualizado e instalado en la máquina y variables de entorno de Java configuradas.
- Android Studio instalado y configurado en su más reciente versión.
- Un dispositivo Android virtual o físico con la depuración por Android Debug Bridge (ADB) habilitada.
- El código fuente de la aplicación desarrollada en el tutorial mencionado en el punto anterior. Recuerde que cuenta con el código fuente de guía, desarrollado por los tutores, en el repositorio del siguiente enlace: https://github.com/TheSoftwareDesignLab/MISW4104-Ejemplos.
En este tutorial se tendrán en cuenta los aspectos de rendimiento mencionados en el tutorial "Cómo mejorar el rendimiento de su aplicación Android por medio de micro-optimizaciones", y por ende, se realizará una comparación gráfica del perfilamiento de ambas versiones de la aplicación. Como primer paso, debe abrir una ventana de Android Studio para cada versión del proyecto. Recuerde que la versión con problemas de rendimiento se encuentra disponible en este enlace: https://github.com/TheSoftwareDesignLab/MISW4104-Ejemplos/tree/main/starters/CL17-microoptimizations, mientras que la versión donde se han aplicado las micro-optimizaciones se encuentra disponible en este enlace: https://github.com/TheSoftwareDesignLab/MISW4104-Ejemplos/tree/main/solutions/CL17-microoptimizations. Idealmente, esta última versión debe coincidir exactamente con el resultado de su implementación del tutorial anterior.
En el tutorial "Cómo mejorar el rendimiento de su aplicación Android por medio de micro-optimizaciones", se mencionaba que las mejoras en los resultados de rendimiento no serían notablemente evidentes luego de aplicar las micro-optimizaciones. En este tutorial, podrá validar esta hipótesis haciendo uso de las herramientas de perfilamiento de Android Studio, ya que podrá comparar las métricas obtenidas entre ambas versiones de la aplicación.
Recuerde que las micro-optimizaciones implementadas fueron enfocadas en dos propósitos específicos, los cuales son:
- Evitar trabajo innecesario.
- Evitar asignaciones innecesarias de memoria.
En lugar de ejecutar el perfilamiento de ambas aplicaciones al mismo tiempo, usted generará un reporte sobre el rendimiento para la aplicación con problemas, lo guardará, y luego generará el reporte para la aplicación optimizada. Finalmente usted va a comparar los puntos críticos para el desempeño en ambos casos.
En la ventana de Android Studio en la que haya abierto el proyecto en su versión con errores, ubique el botón para realizar el perfilamiento en la parte superior derecha. Este tiene el nombre "profile ‘app'", y se identifica con el siguiente símbolo:
Imagen 1. Icono del botón para perfilar un proyecto
Al momento de presionar este botón, la aplicación se lanzará en el dispositivo conectado por ADB. Además, en Android Studio se desplegará un panel especial llamado "profiler" en la parte inferior que se ve de la siguiente forma:
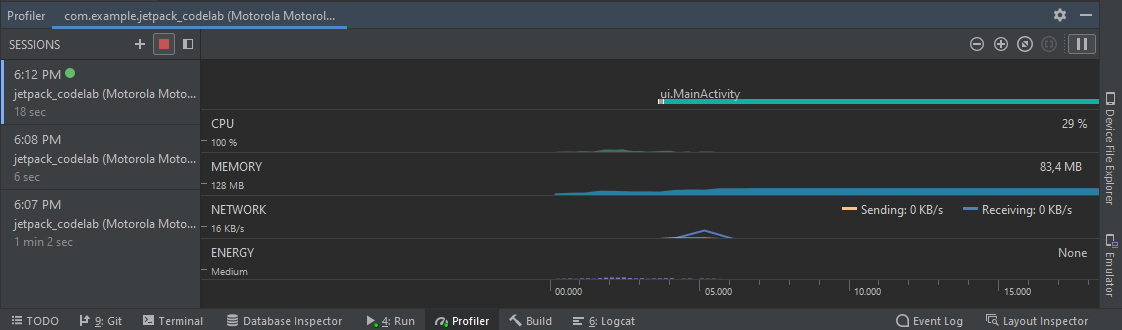
Imagen 2. Panel general del profiler
Este panel contiene una sección lateral con un listado de las sesiones de perfilamiento que se han realizado sobre el proyecto, destacando la sesión activa con un círculo de color verde. Además de este, existe una sección central que muestra cuatro filas de gráficas con tipos de gráfico distintos que muestran información acerca del uso de CPU, de memoria, de red y de energía con respecto al avance del tiempo. Adicionalmente, existe una fila superior a las 4 mencionadas anteriormente, donde se muestra un cronograma con eventos relacionados a la entrada del usuario y el ciclo de vida de las vistas y servicios en ejecución. En este panel también existen varios botones que permiten controlar el zoom de las gráficas, y también detener o restaurar el avance de las gráficas con respecto al avance de la aplicación.
Puede obtener más información acerca del perfilamiento si hace clic en cada fila de gráfico y selecciona la primera opción del menú, como se muestra a continuación:
Imagen 3. Menú desplegable de cada gráfica
Conocer el panel de detalles del uso de CPU
Al hacer clic en la opción Open CPU del menú mencionada anteriormente, se despliega el panel que se muestra en la siguiente imagen:
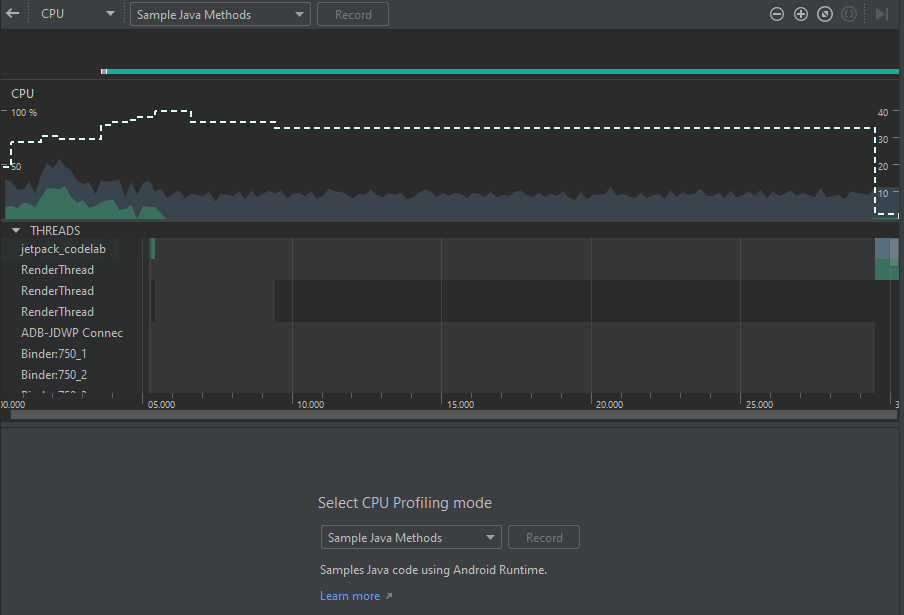
Imagen 4. Panel de información detallada del uso de CPU
Se puede ver que, en la parte superior, existe una flecha de retroceso para cerrar la vista detallada y volver al panel mencionado en la sección anterior. Junto a esta, se puede ver un desplegable con las 4 opciones de gráficas a mostrar (CPU, Memory, Network, Energy). En cuanto a la gráfica, se muestra la misma información que en la vista general, lo cual incluye el uso porcentual de CPU. La gráfica distingue el porcentaje que corresponde a la aplicación del porcentaje que corresponde a otros hilos, y adicionalmente, muestra una línea con la cantidad de hilos vivos en el momento. El eje y del lado izquierdo corresponde al porcentaje de CPU, mientras que el eje y del lado derecho corresponde a la cantidad de hilos.
Justo debajo de la gráfica, hay un panel que detalla el uso de CPU de cada uno de los hilos existentes. Debajo de este panel, se puede ver otro que permite seleccionar uno de varios modos de perfilamiento de la CPU. Las opciones de este panel son
- Sample Java Methods, el cual captura la pila de llamadas en intervalos frecuentes durante la ejecución de código basado en Java.
- Trace Java Methods, el cual instrumenta la aplicación durante el tiempo de ejecución para registrar marcas de tiempo que indican el inicio y final de cada llamado a métodos.
- Sample C/C++ Methods, el cual captura seguimientos muestreados de los subprocesos nativos de la aplicación.
- Trace System Calls, el cual captura detalles específicos que permiten ver cómo la aplicación interactúa con los recursos del sistema.
Conocer el panel de detalles del uso de Memoria
Cuando se selecciona la gráfica de memoria, se muestran los siguientes paneles con el detalle del perfilamiento:
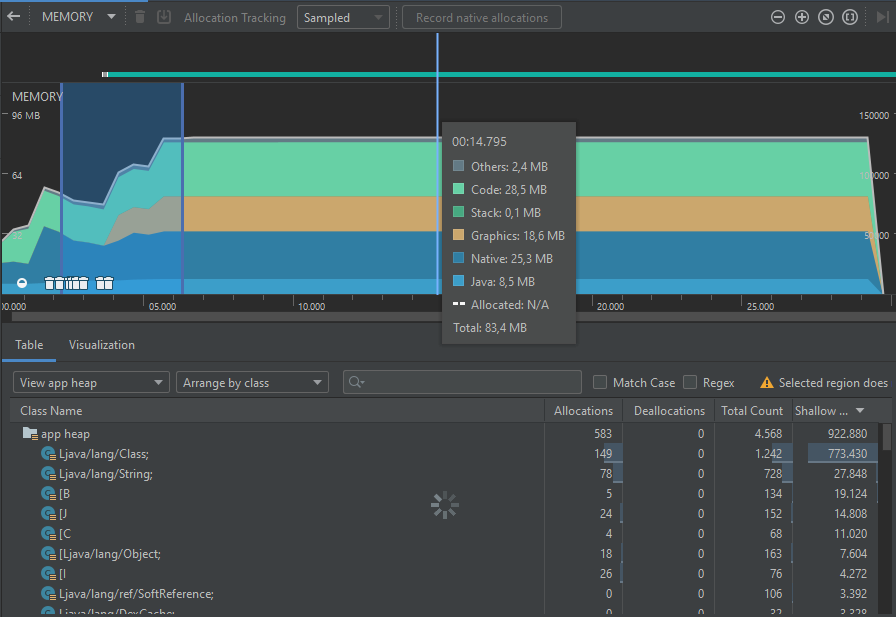
Imagen 5. Panel de información detallada del uso de memoria
Se puede ver que la gráfica en este caso también es un acumulado de varias series, que incluyen la memoria usada por código (de color verde claro), por el stack (de color verde oscuro), memoria nativa (de color azul oscuro), de Java (de colorazul claro), de gráficos (de color amarillo quemado), y otras fuentes (de color gris). La gráfica tiene medidas del tamaño de memoria en el eje Y.
Así mismo, la gráfica muestra varios puntos identificados por un ícono de una caneca de basura, los cuales representan eventos de Garbage collection (gc), que corresponden a señales que se realizan para que la JVM realice una limpieza de objetos sin referencia del heap, con el fin de liberar recursos de memoria volátil. Estos son relevantes para la gráfica de desempeño de la memoria, ya que, además de liberar espacio, implican un trabajo significativo para otros recursos de procesamiento como la CPU.
Debajo de la gráfica, se puede ver un panel con dos pestañas. La primera, table, permite explorar la información de los tipos de datos utilizados para representar los objetos que se han creado en la memoria y las métricas de espacio ocupado por cada una.
La segunda pestaña, visualization, muestra información menos detallada de los objetos de memoria creados en el intervalo seleccionado, como se muestra a continuación.
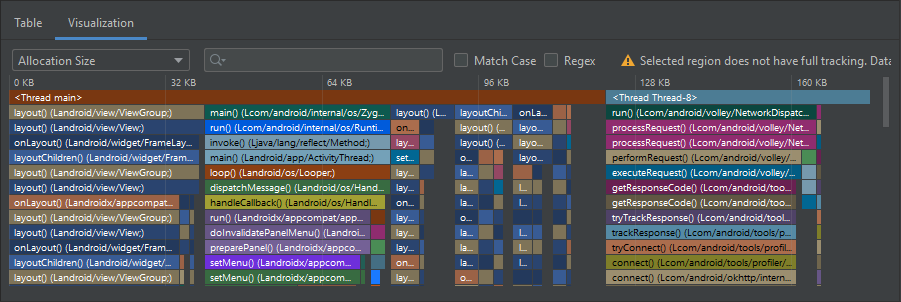
Imagen 6. Panel de información detallada de la invocación de métodos relacionados a la memoria
Conocer el panel de detalles del uso de red
Cuando se selecciona la gráfica de red, se muestran los siguientes paneles:
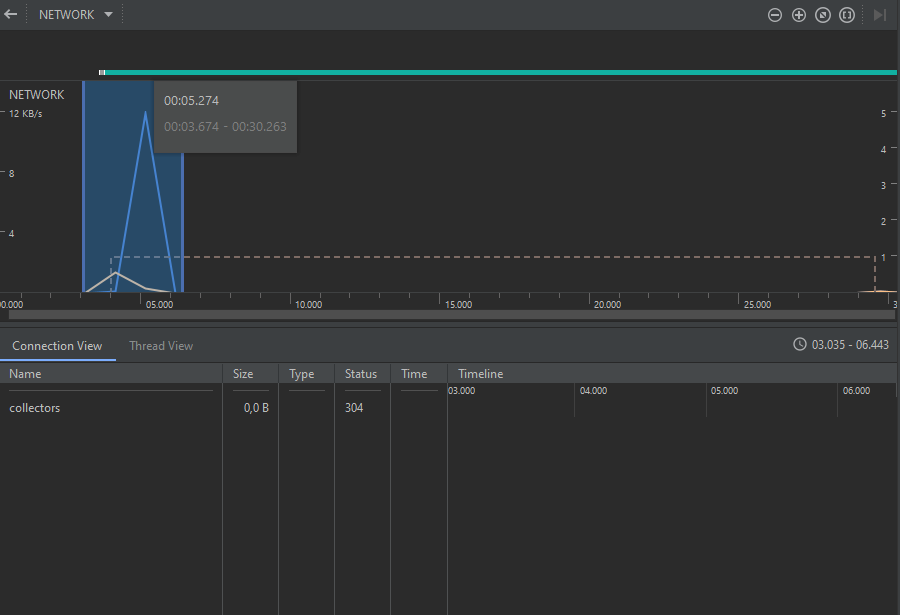
Imagen 7. Panel de información detallada del uso de red
En este caso, la gráfica muestra líneas de tendencia indicando la tasa de transmisión de datos utilizada por la red desde y hacia la aplicación. El eje Y muestra la velocidad de la red en KB/s.
Debajo de esta gráfica se puede ver un panel con dos pestañas. La primera, Connection View, permite ver los detalles sobre las conexiones establecidas a lo largo del tiempo, lo que incluye el nombre, el tamaño, el tipo y el código de respuesta de la petición. La segunda, Thread View, permite ver los eventos de red de entrada y salida de datos de la aplicación, distinguiendo por el hilo que inicializa la petición.
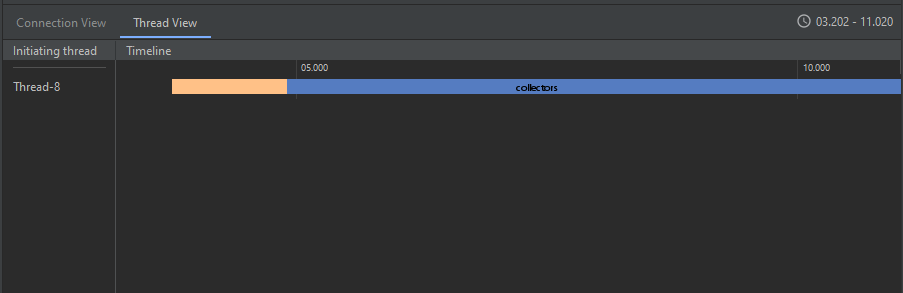
Imagen 8. Panel de información detallada de las consultas de red de cada thread
Conocer el panel de detalles del uso de energía
Finalmente, cuando se selecciona la gráfica de energía, se muestran los siguientes paneles:
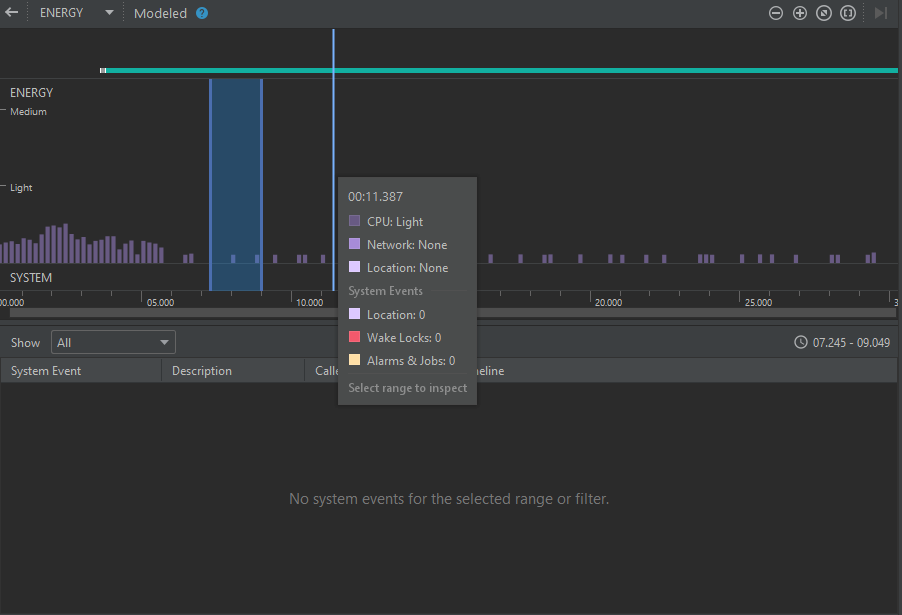
Imagen 9. Panel de información detallada del uso de energía
En este caso, la gráfica muestra los datos en barras, indicando los eventos que implican un consumo de energía. Esta gráfica es cualitativa, ya que su eje Y indica el nivel de consumo (bajo, medio, alto). Además, la gráfica permite distinguir los eventos que provienen de CPU, de red, de los servicios de ubicación, y del sistema en general.
Debajo de la gráfica hay un panel que muestra los detalles de los eventos del sistema, si los hay.
Como se mencionó anteriormente, es posible que las micro optimizaciones implementadas no generen un impacto significativo en el rendimiento a pequeña escala. Lo anterior no quiere decir que no valga la pena hacer micro optimizaciones, sino que, su impacto se empieza a notar al sumarse con otras optimizaciones en diversos puntos de la aplicación.
Una muy buena forma de probar esta hipótesis es comparar el rendimiento de ambas versiones del código con el apoyo del profiler de Android Studio. Para poder establecer esta comparación, las instrucciones a seguir con ambos proyectos son las siguientes:
- Ejecutar el perfilamiento con el botón "profile ‘app'". En caso de que la información de los coleccionistas no cargue al inicio, volver a presionar este botón.
- Seleccionar cualquier coleccionista. Esperar un tiempo a que el profiler registre el evento del clic y la creación del fragmento nuevo.
- Seleccionar el primer álbum. Esperar un tiempo a que se registre el evento y la interfaz muestre el comentario.
- Presionar el botón "LOG RATING". Esperar un tiempo a que se registre el evento y revisar el resultado en el panel "Run" de Android Studio.
- Presionar el botón "LOG CAPITALIZED". Esperar un tiempo a que se registre el evento y revisar el resultado en el panel "Run" de Android Studio.
Lleve un registro del tiempo en que ejecutó cada evento. En la parte superior podrá ver los eventos que activó el usuario, pero es mejor que esté completamente seguro de qué operación sucede en cada momento.
Además de la comparación, el perfilamiento le permite detectar puntos de interacción que implican cargas de trabajo altas para su aplicación. Para este fin, inicialmente usted va a interpretar los puntos que ambas versiones de la aplicación tienen en común durante la interacción.
Observar el comportamiento de inicio de la aplicación
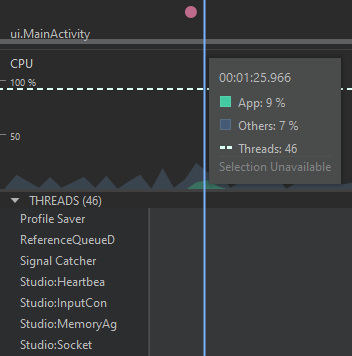
En primer lugar, resalta el inicio de la aplicación, donde se crea la MainActivity, se asocia el CollectorsFragment, y se realiza la consulta por medio de la red a través del CollectorsRepository para mostrar la información en la vista. Las gráficas deben verse de una forma similar a la siguiente:
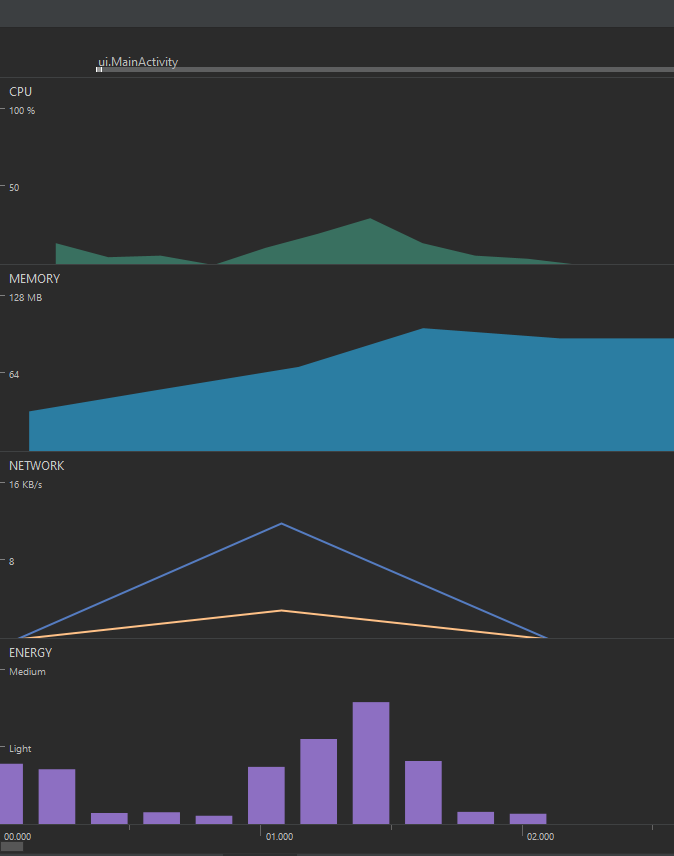
A primera vista, es evidente que existe un evento de la red en el primer segundo, que corresponde a la consulta de los coleccionistas al API. Luego de completar esta consulta de red, se puede ver un aumento en las gráficas de CPU y de memoria, lo cual se justifica dado que la información obtenida desde la red es almacenada en el ViewModel y luego se muestra en la interfaz gráfica, construyendo los elementos del RecyclerView uno a uno.
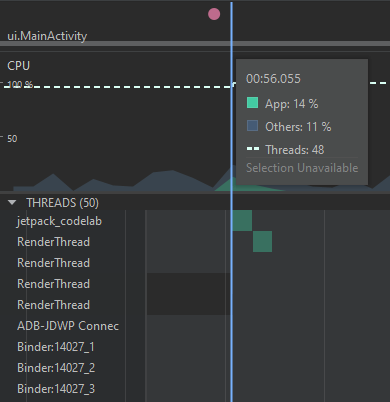
Abra la vista de CPU en este punto para ver la distribución de eventos entre los hilos. Podrá notar una distribución parecida a la siguiente:
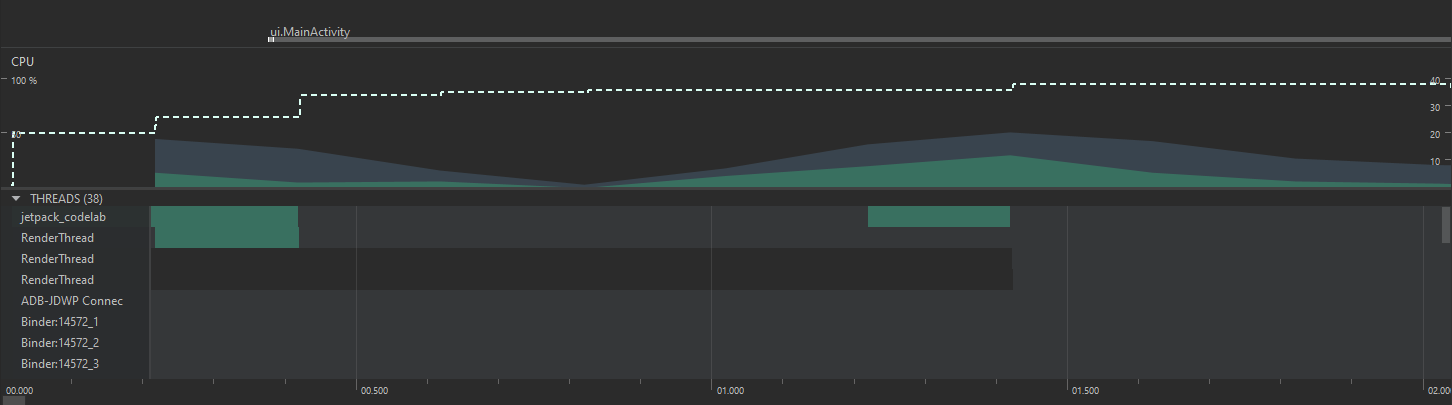
El hilo principal tendrá el nombre del paquete de la aplicación. Este tendrá gran parte del uso de CPU, como muestra el gráfico de uso acumulado. También puede ver qué otros hilos se encuentran involucrados a una operación. Al inicio de la aplicación puede ver que se ocupan hilos de tipo RenderThread para construir la interfaz gráfica general. Así mismo, puede ver, si se desplaza a la parte inferior, que hay un hilo genérico que tiene parte importante del uso de CPU al momento de cargar la información. Es posible asumir que esta carga corresponde a un hilo interno de Volley que es usado para enviar la petición de red y obtener la respuesta.
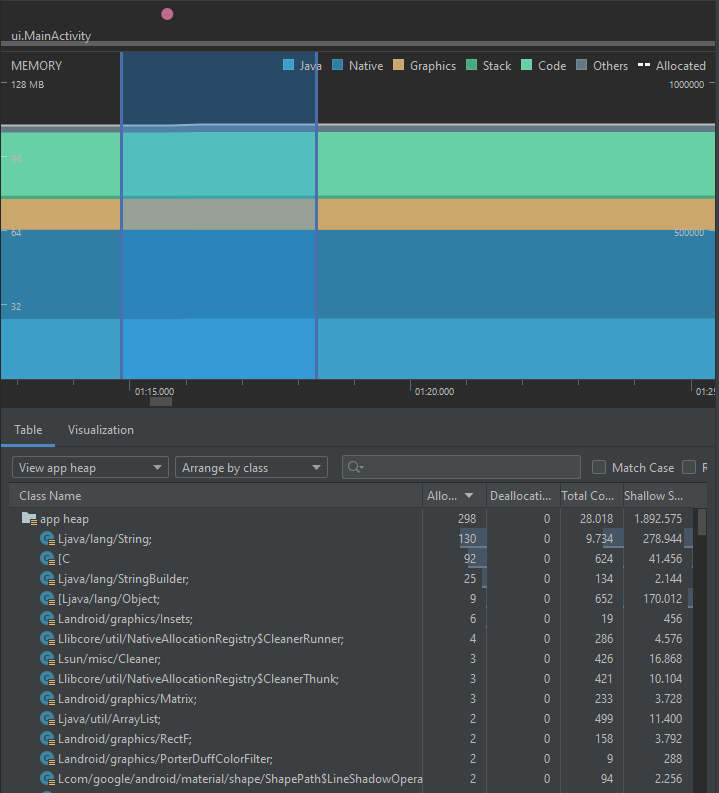
Abra la vista de memoria en este punto para ver la ocupación de memoria. En el panel de la tabla de objetos filtre por el nombre "Collector". Podrá notar una distribución parecida a la siguiente:
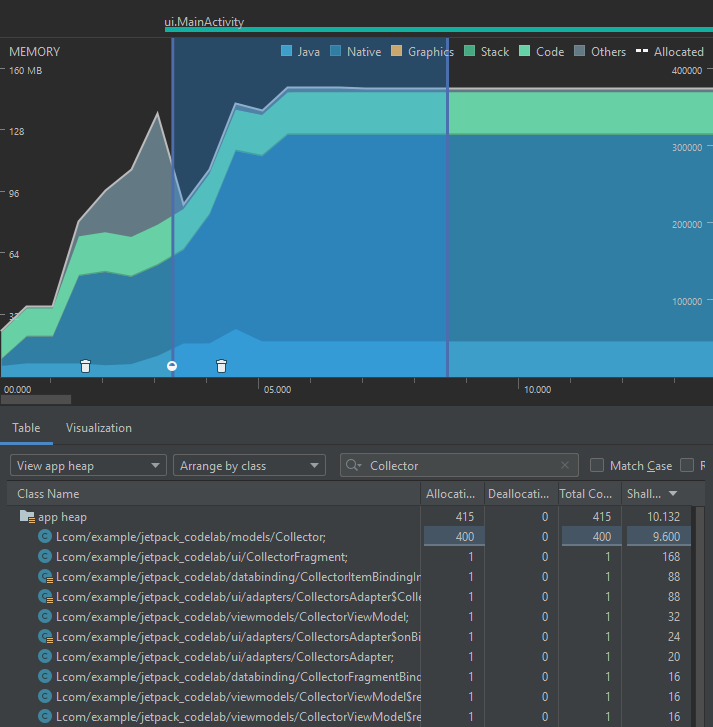
Note, en primer lugar, que esta vista le indica el número de objetos de cada tipo que se crearon en un período, y el tamaño aproximado que ocupan en memoria. Se puede ver, entre otras cosas, que se crean los coleccionistas a partir de la información obtenida del API REST. Note también que en la parte inferior pueden existir unos símbolos indicando eventos de garbage collection. Al inicio de la aplicación, esto suele ser común sin importar el contexto, dado que se crean muchos objetos pertenecientes a clases internas del framework de Android.
Abra la vista de red para ver los detalles de las consultas que se han realizado. Seleccione el rango, y podrá ver un panel como el siguiente:
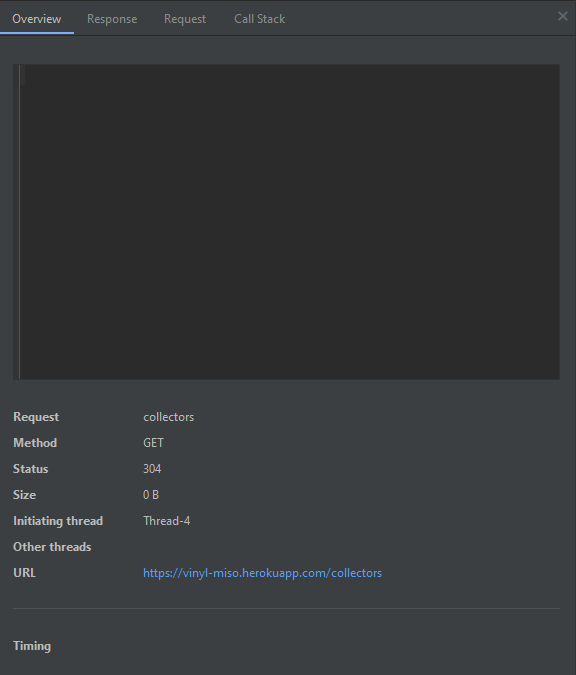
En las demás pestañas puede ver los detalles de la respuesta y la petición HTTP que fueron realizadas, además de la pila de llamados a métodos internos de la librería de red.
Los detalles acerca de la energía no traen mucha información significativa que pueda aportar a su análisis, por lo cual se omitirán.
Cambio a AlbumsFragment
Luego de esto, regrese a la vista de la gráfica general y explore el evento que ocurre cuando selecciona un coleccionista. Esto lanzará el fragmento AlbumsFragment y pausará el CollectorsFragment. Las gráficas deben ser similares a la siguiente forma:
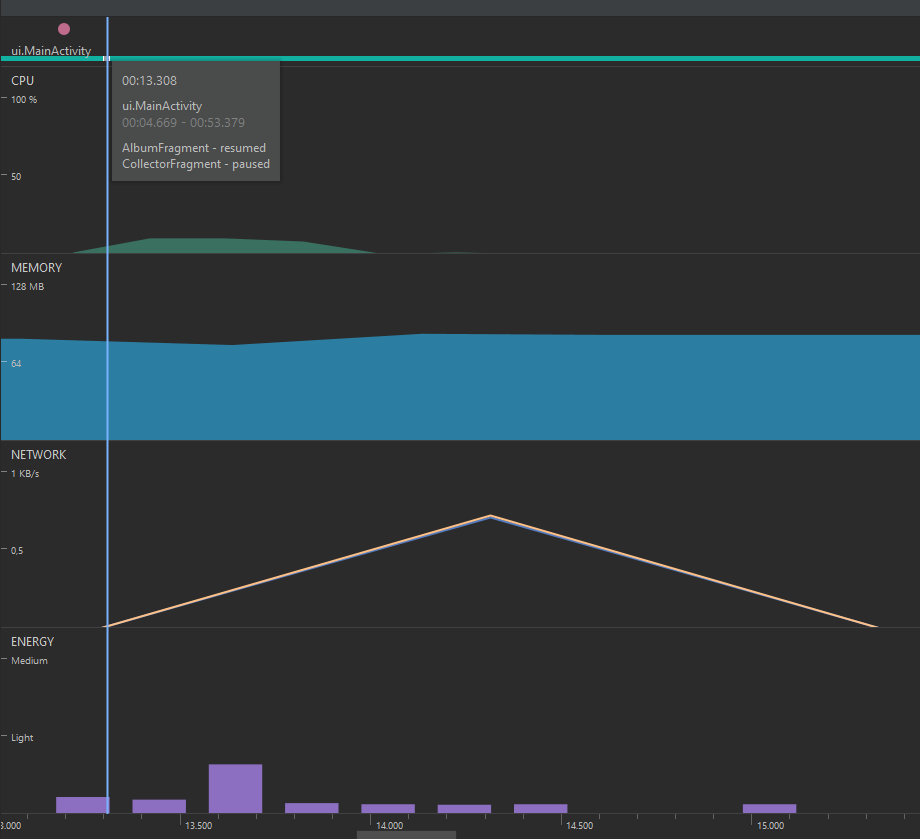
En esta ocasión no se ve un aumento en la memoria a causa de la petición de red, pero sí se ve un flujo a causa de la construcción de los objetos relacionados a la interfaz gráfica. Lo mismo sucede en cuanto al uso de CPU, puesto que el porcentaje de uso cuando se recibe la información es tan pequeño (1%) que casi ni se nota en la gráfica.
Nuevamente, si busca la vista de Memoria, podrá ver los objetos de tipo Album que se han creado para este momento, como se muestra a continuación:
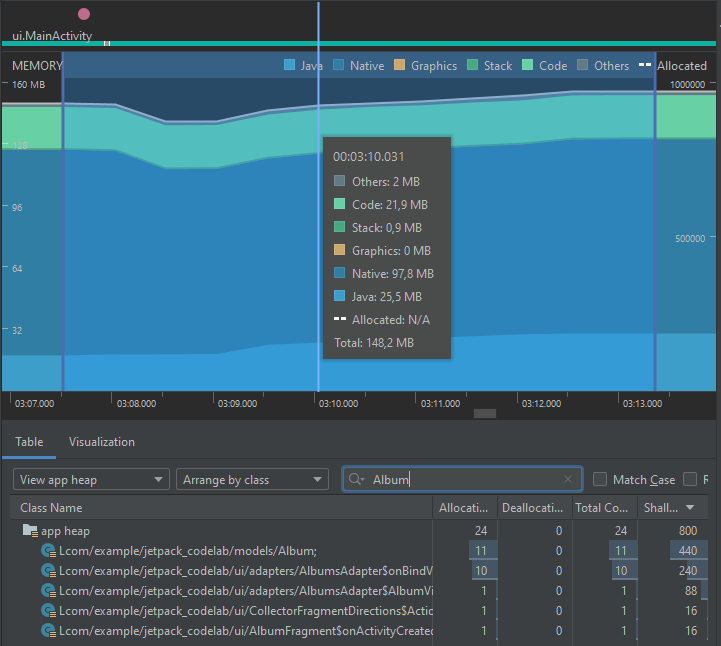
Ahora que conoce los puntos en común de ambas aplicaciones, explore las gráficas de rendimiento para comparar los puntos en donde la implementación fue modificada.
El primero de estos puntos corresponde al evento de transición del AlbumsFragment al CommentsFragment, donde se carga el valor del atributo comments en el ViewModel. En este caso, la optimización realizada en el tutorial anterior consiste únicamente en la extracción de una variable, de forma que se utilice un solo espacio en memoria para todas las iteraciones, en lugar de realizar una alocación en cada iteración.
A continuación se muestra el perfilamiento en memoria de la primera implementación:
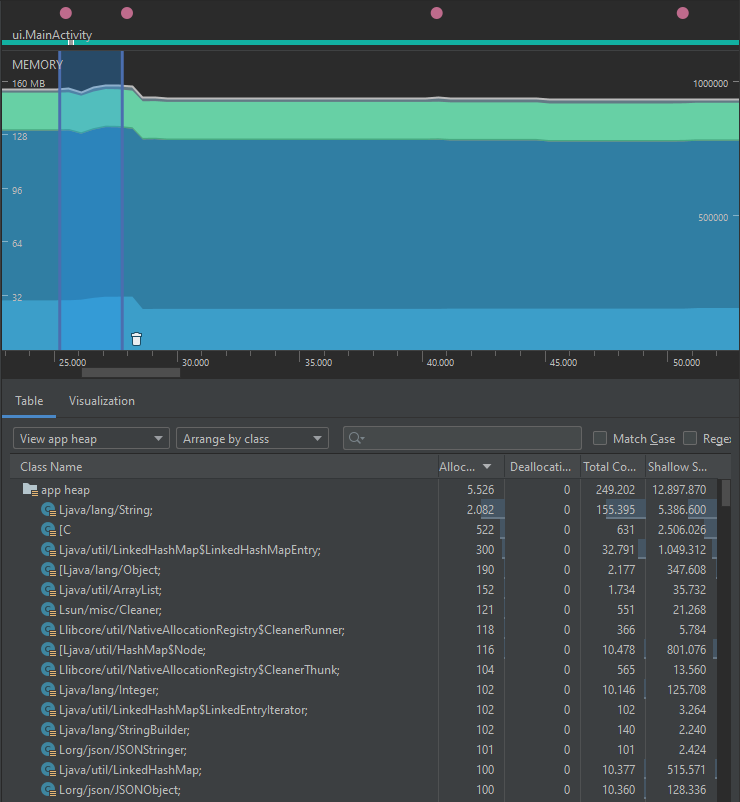
En contraste, el perfilamiento después de la primera optimización se ve de la siguiente forma:
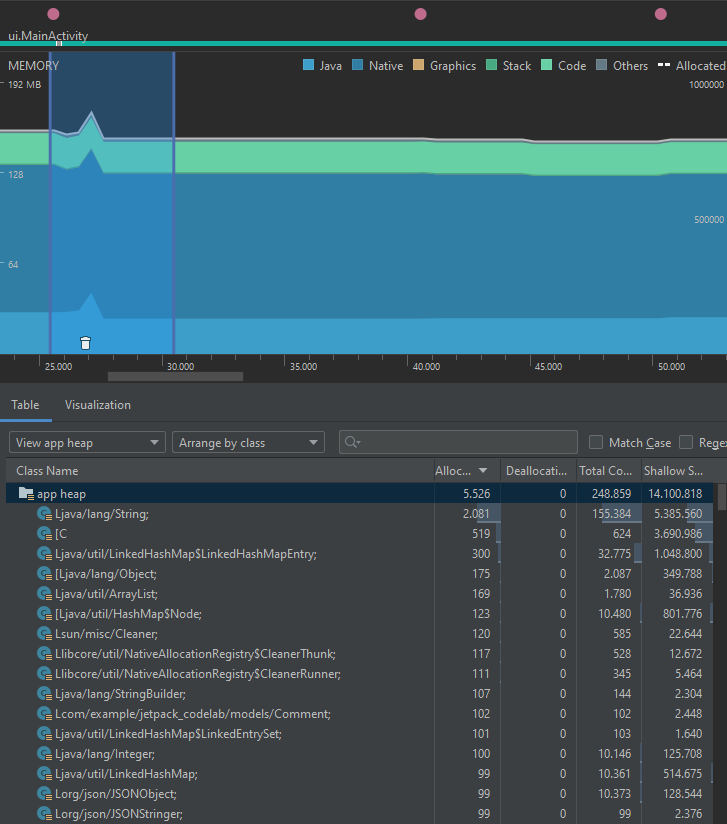
Podrá notar que, si bien no existe una diferencia significativa en unidades de centenas entre las alocaciones de objetos, sí existen reducciones en la cantidad de objetos alocados de clases Object, JSONObject, JSONStringer, las cuales se relacionan directamente con la eliminación de las variables intermedias. Además de esto, se puede ver que el conteo total de objetos de todas las clases en el heap se reduce en casi 600.
El segundo de estos puntos corresponde a la activación del método printByRating a partir del botón LOG RATING. Allí se puede ver una diferencia importante en la implementación, como se muestra a continuación:
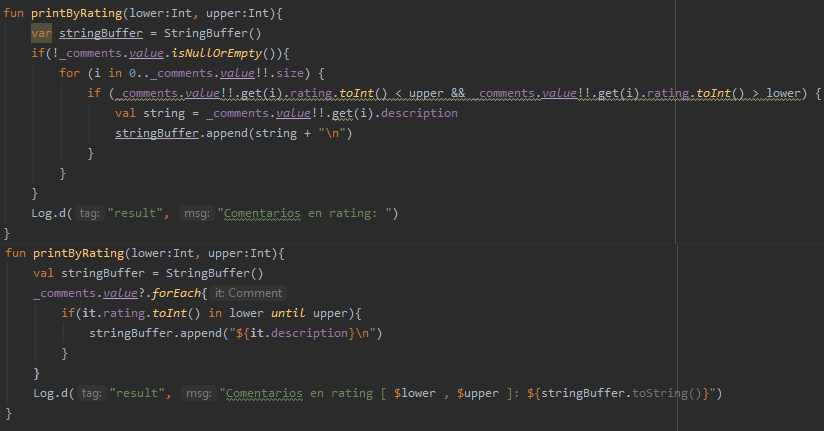
Al ejecutar el perfilamiento de la primera implementación, se obtienen los siguientes resultados:
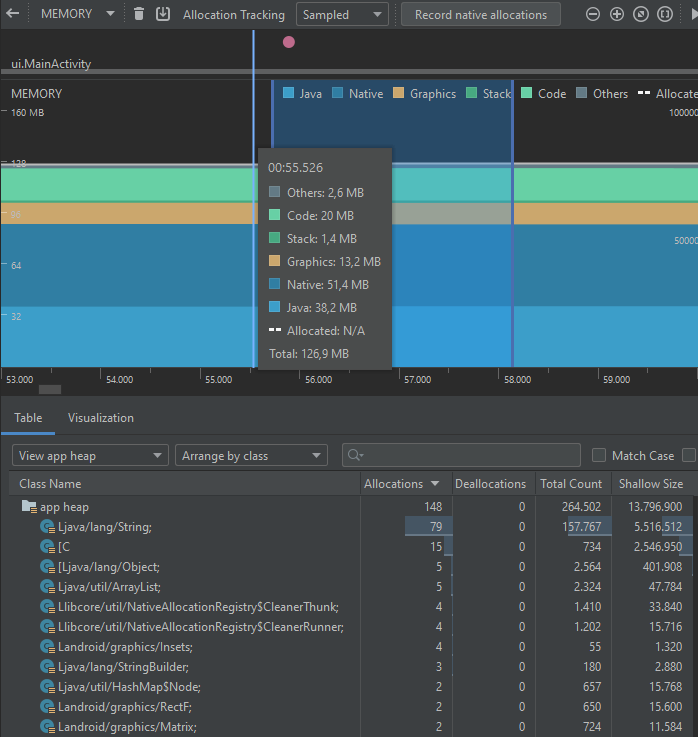
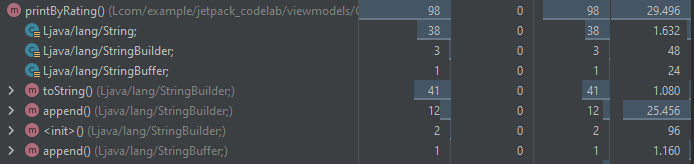
Por su parte, la segunda implementación permite obtener los siguientes resultados:

Es posible ver, entonces, que existe una reducción en el consumo de CPU que viene con la nueva versión del código, dado que se reduce el número de cálculos que debe hacer el sistema en el condicional, al extraer una variable extra con el uso del método forEach.
Así mismo, aunque el número de allocations de objetos de tipo String, StringBuilder y Object son mayores en la segunda implementación, el tamaño en memoria que ocupan los objetos de estos tipos es menor. Si bien este número puede depender de muchos factores y operaciones previas, los resultados en ambas ejecuciones fueron capturados siguiendo los mismos pasos y tratando de replicar las mismas condiciones del entorno del sistema. Además, con las gráficas que muestran la memoria agrupada por callstack se puede ver que la primera implementación ocupa 29.496 bytes, mientras que la segunda ocupa 9.632 bytes de memoria.
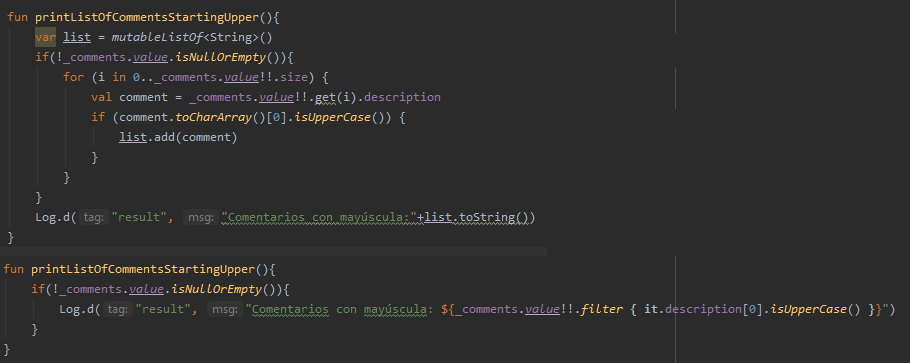
El último de estos puntos corresponde a la activación del método printListOfCommentsStartingUpper a partir del botón LOG CAPITALIZED. Allí también es posible ver una diferencia en la implementación, como se muestra a continuación:
Al ejecutar el perfilamiento de la primera implementación, se obtienen los siguientes resultados:
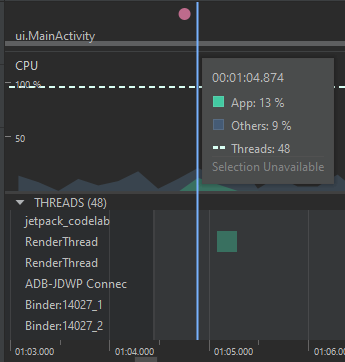
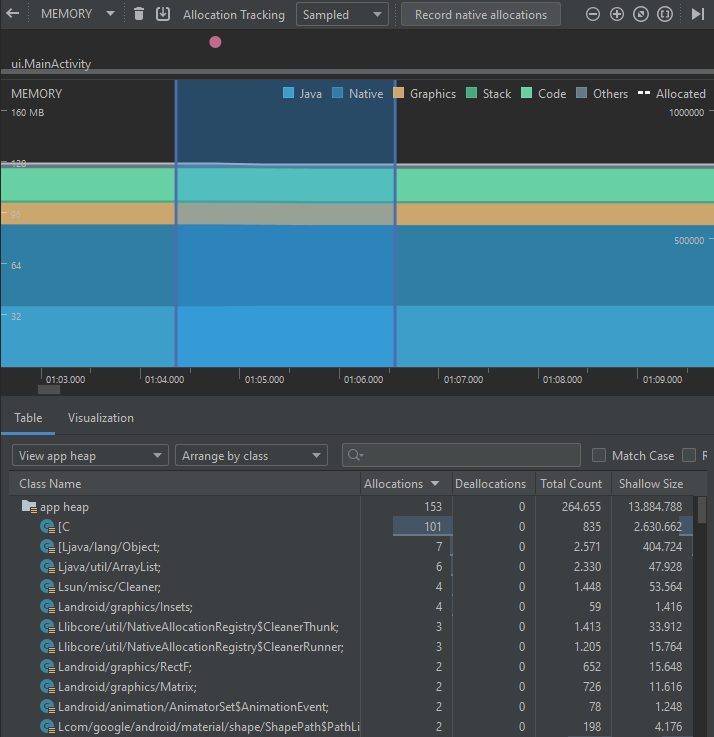

Por su parte, la segunda implementación permite obtener los siguientes resultados:
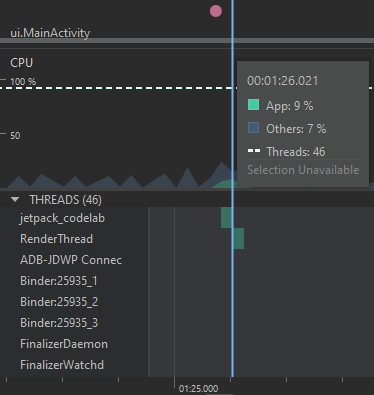
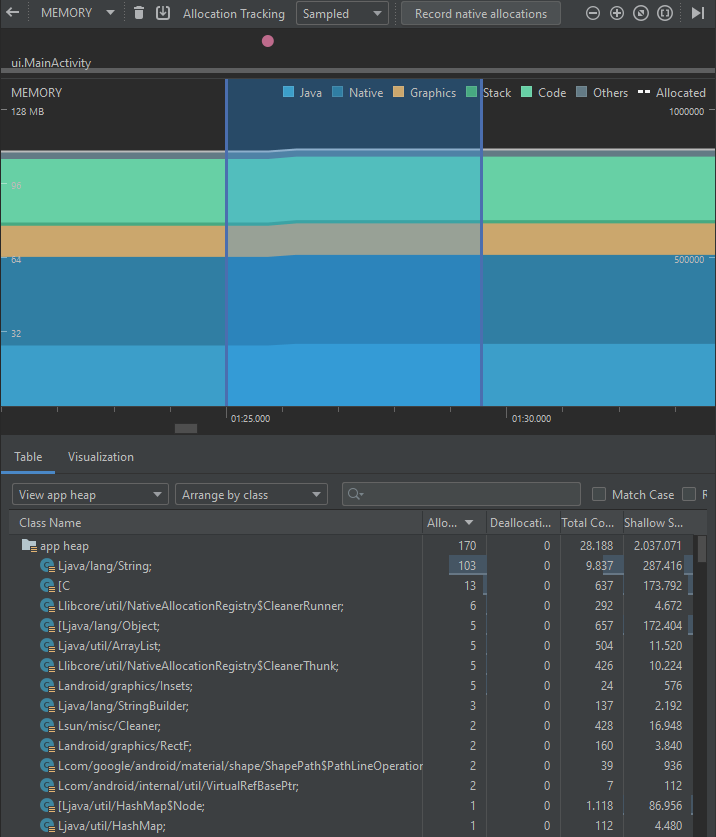

Es posible ver, entonces, que también existe una reducción del uso de CPU en la segunda implementación, dado que se reduce el número de invocaciones a métodos y variables auxiliares del ciclo original, aprovechando las características del método filter de la colección. En este caso, también se puede apreciar un aumento en el número de allocations de objetos de clase String. En cuanto a las clases Object y ArrayList, la reducción es ínfima. A pesar de esto, las gráficas que muestran la memoria agrupada por callstack muestran también que la primera versión utiliza 86.424 bytes de memoria, mientras que la segunda solo utiliza 12.576 bytes, y no utiliza el método toString(), el cual representa gran cantidad de la creación de objetos.
Nota: los resultados mostrados en este tutorial fueron capturados con un dispositivo físico con 4GB de RAM. Estos resultados pueden variar según las capacidades físicas del dispositivo y otras condiciones de la ejecución como los pasos tomados o el uso compartido de recursos en el dispositivo.
¡Felicidades!
Al finalizar este tutorial, pudo familiarizarse con las herramientas de perfilamiento del rendimiento de una aplicación en Android Studio. Además, pudo aprender a explorar e interpretar los resultados obtenidos con ellas
Ahora podrá generar perfiles del desempeño de otras aplicaciones con Android Studio, teniendo en cuenta las métricas de uso de CPU, uso de memoria, uso de red y uso de energía.
Créditos
Versión 1.0 - Mayo 30, 2021
Juan Sebastián Espitia Acero | Autor |
Norma Rocio Héndez Puerto | Revisora |
Mario Linares Vásquez | Revisor |