¿Qué aprenderá?
En este tutorial aprenderá cómo puede usar AWS Glue para crear ETLs con historia a nivel de dimensiones. Igualmente aprenderá cómo puede conectar AWS Glue con bases de datos RDS en AWS.
¿Qué construirá?
Construirá sobre el ETL del taller anterior, esta vez incluyendo el manejo de historia para algunas de las dimensiones del modelo multidimensional.
¿Para qué?
Dentro de los procesos de ETL, es común que se presenten dimensiones que puedan presentar cambios a través del tiempo para las cuales es necesario tener un plan de manejo de historia. Por lo tanto, es esencial saber cómo realizar este manejo en las distintas herramientas de ETLs.
En este tutorial, utilizará AWS Glue para crear y ejecutar un ETL con historia. Para completar este taller, es necesario que haya completado el taller anterior, creación de un ETL sin historia, pues se construirá sobre el mismo. Recuerde que, si lo necesita, puede consultar la documentación de AWS Glue en https://docs.aws.amazon.com/glue/index.html
¿Qué necesita?
Los datos y el código a ejecutar lo puede encontrar en el repositorio: https://github.com/MIAD-Modelo-Datos/Recursos/tree/main/Glue
- AWS: glue, RDS. Los costos asociados deberán ser asumidos por los estudiantes, bajo ningún motivo la universidad garantizará estos recursos
- Servidor SQL Express
- Azure data studio
- Archivos CSV de WWI
- Archivo .py a ejecutar
- Conocimientos básicos sobre bases de datos relacionales
- Pyspark 3 y python 3
Para iniciar este tutorial, debe crear una base de datos en AWS. Para esto, ingrese a AWS y busque RDS en la barra de búsqueda, una vez en RDS diríjase a Databases, en el panel izquierdo:
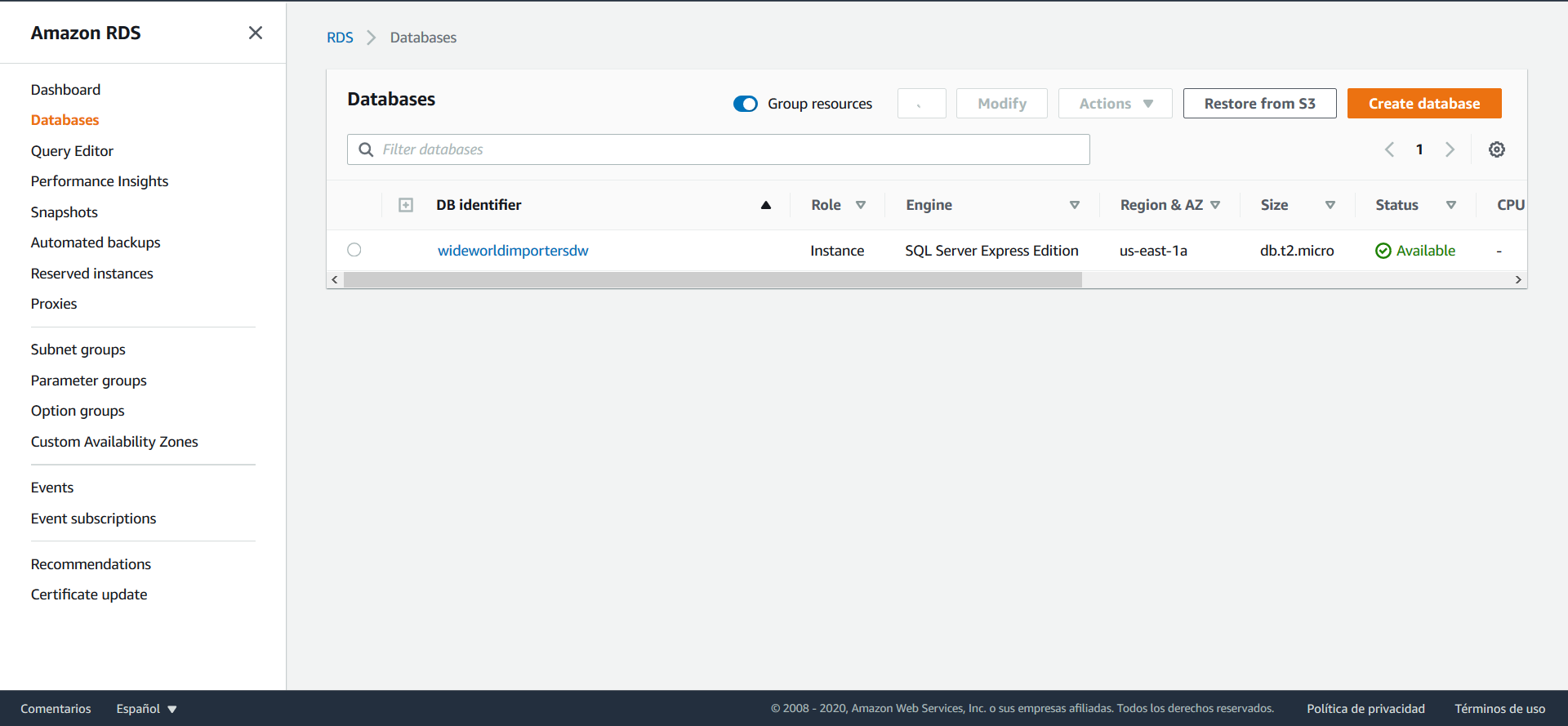
Haga clic sobre el botón Create database y en la página que se abre seleccione las opciones: Easy Create, Microsoft SQL Server y Free tier. Después proceda a nombrar la base de datos a su gusto y a crear el usuario administrador con el usuario y contraseña que usted desee:
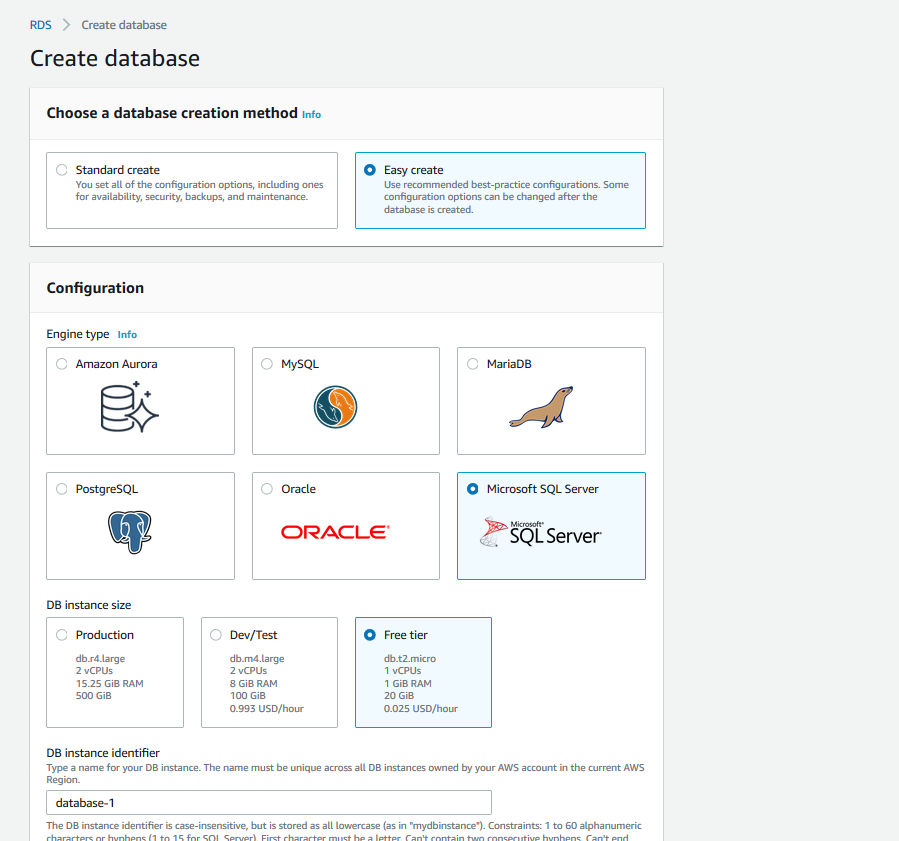
Una vez finalizado este proceso, seleccione su base de datos y haga clic en la opción Modify:
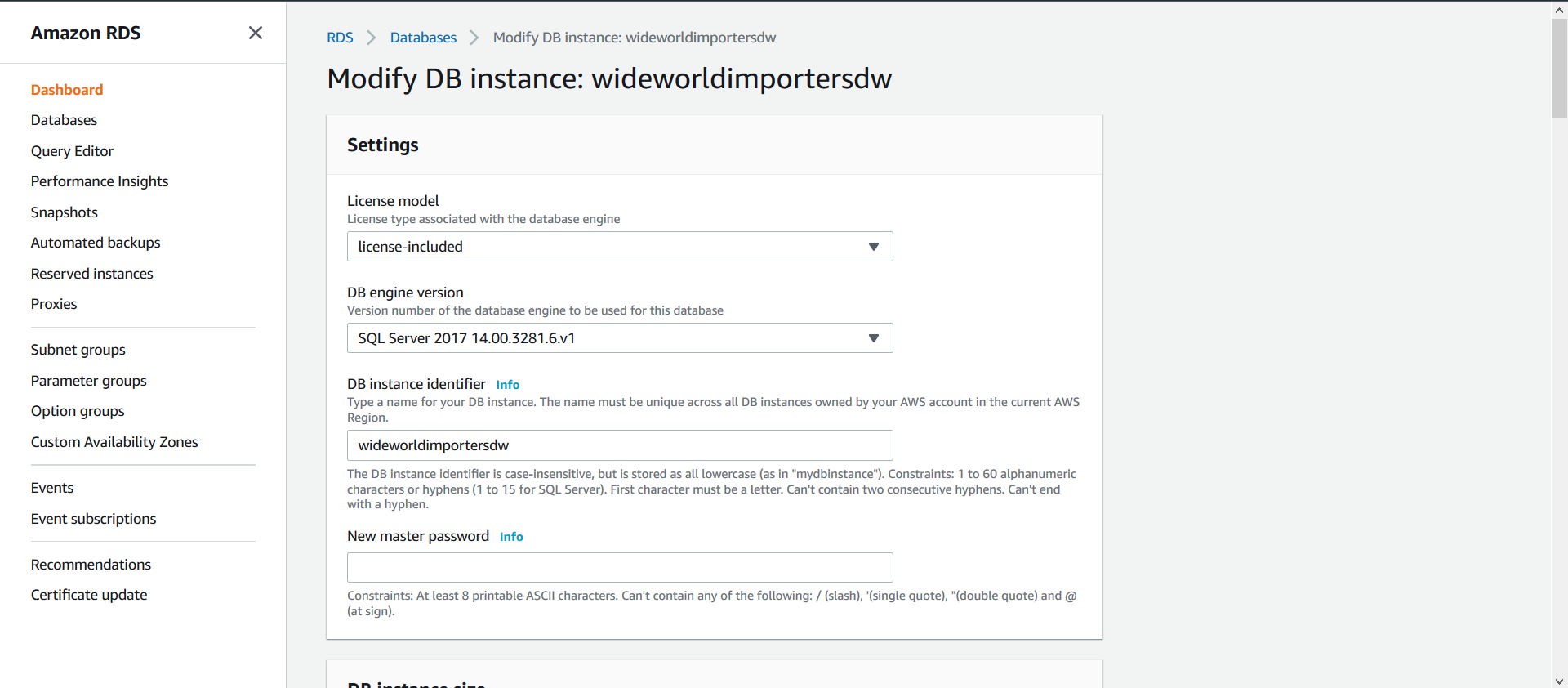
Ahora, busque la opción Connectivity, expanda las opciones haciendo clic sobre Additional configuration, allí seleccione la opción Publicly accesible y guarde sus cambios.
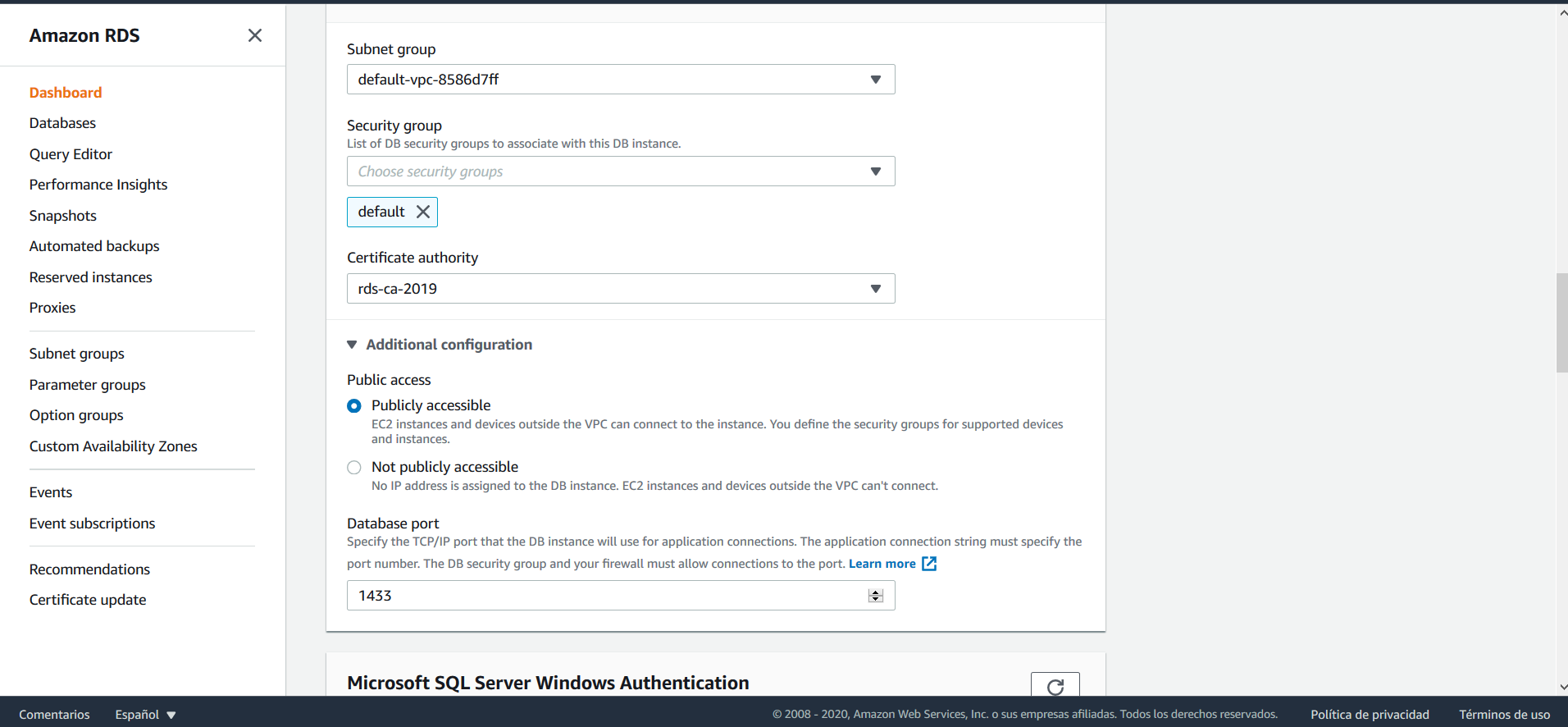
En el menú de las bases de datos, seleccione de nuevo su base de datos y haga clic sobre el nombre, esto abre un panel que muestra las configuraciones de la misma. Allí, diríjase a Connectivity and security > Security.
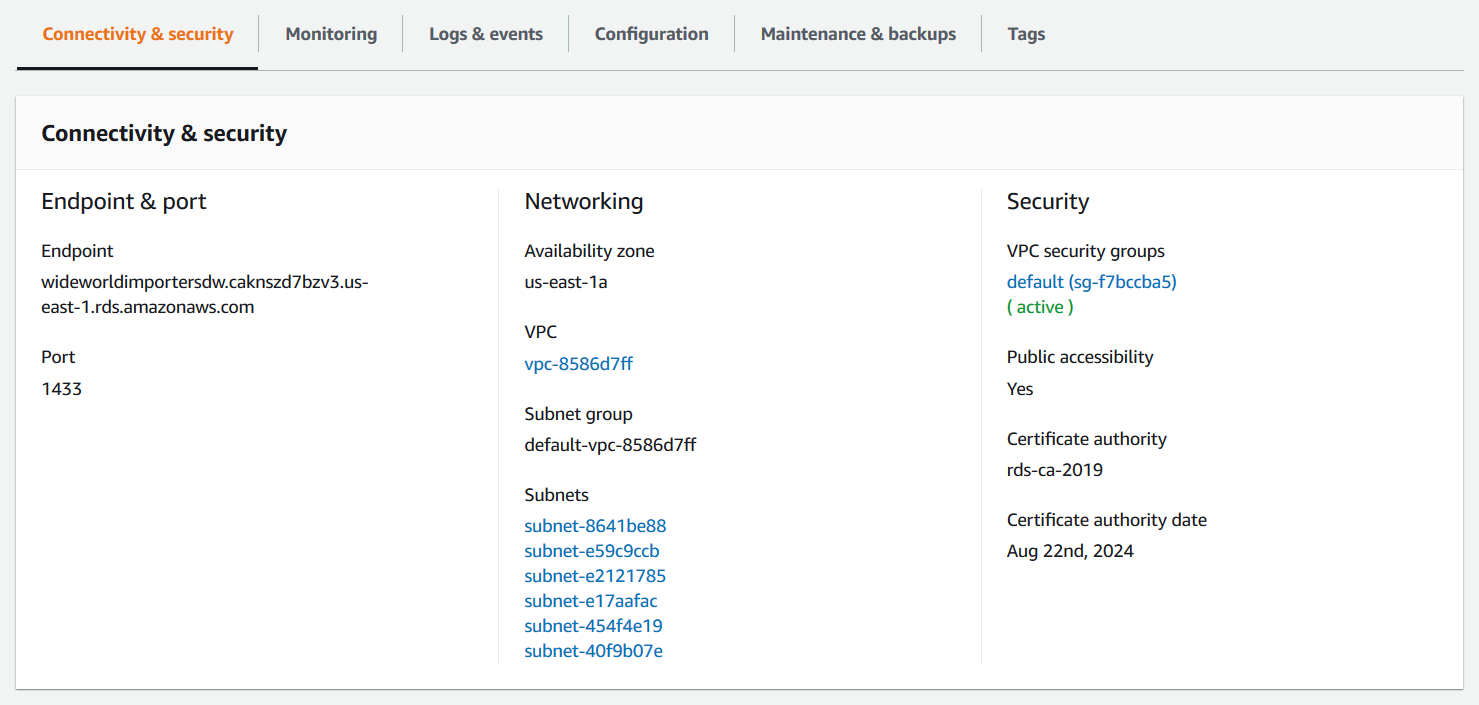
Haga clic sobre el VPC Security Group que aparece, esto abre la configuración del grupo de seguridad.
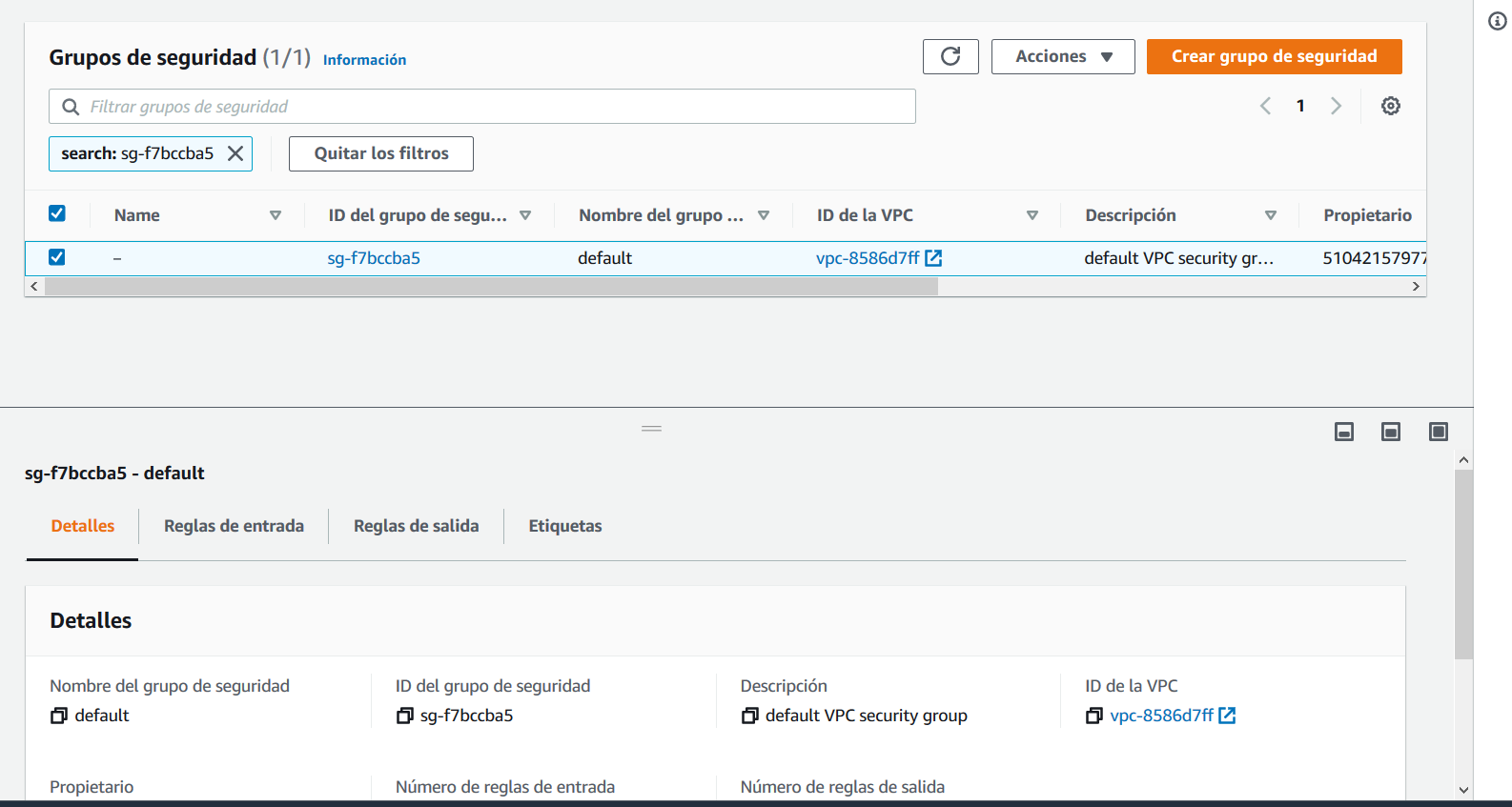
Vaya a la opción Reglas de entrada y haga clic sobre Editar reglas de entrada, cree ahora dos reglas de entrada, la primera debe ser de tipo Todos los TCP. En Origen especifique el mismo grupo de seguridad. La segunda debe permitir la entrada de todo el tráfico desde su IP o, si lo prefiere, desde cualquier IP, sin embargo, recuerde que habilitar el acceso desde cualquier IP es una mala práctica que no se debe aplicar a bases de datos con información que no sea pública.
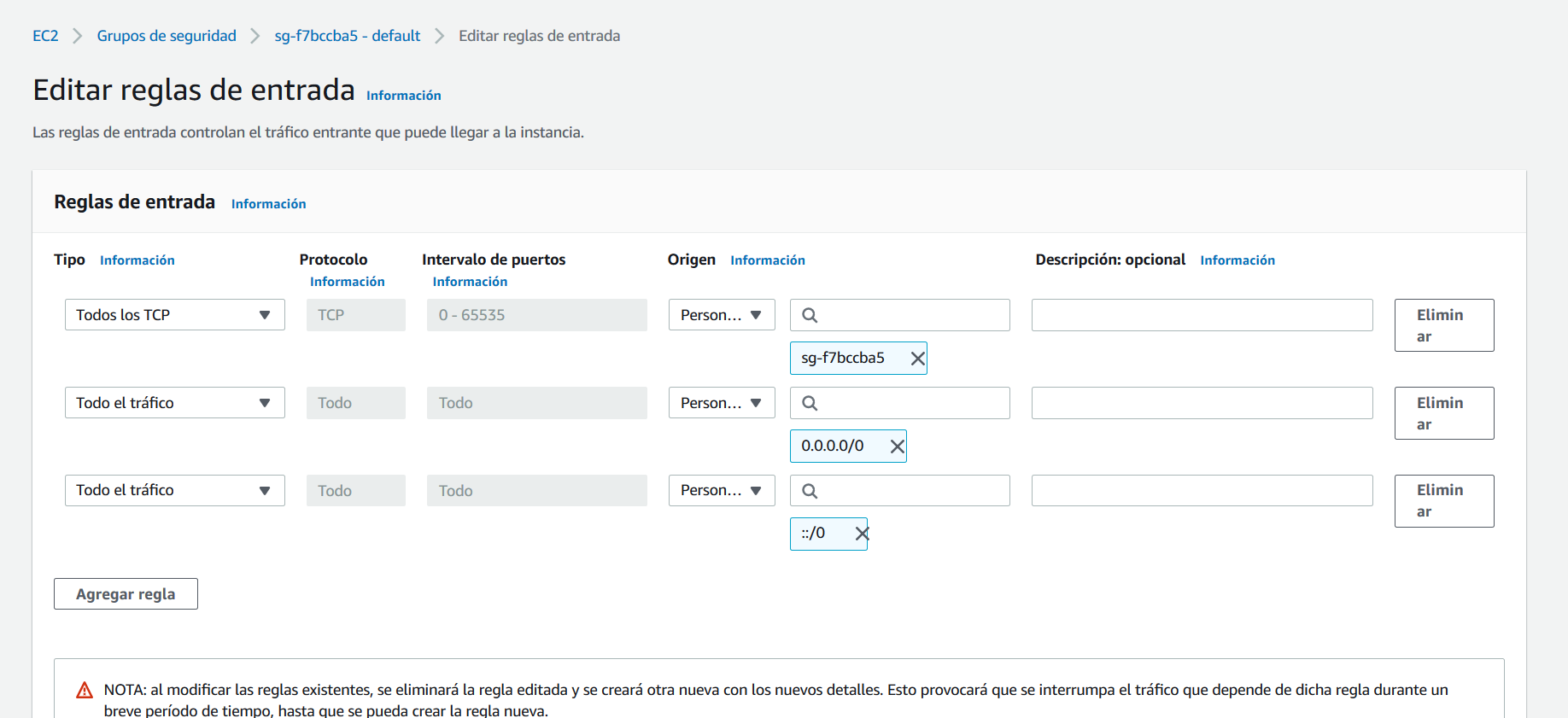
Realizado esto, ya es posible acceder a la base de datos para crear las tablas. A continuación, abra Azure Data Studio y haga clic sobre la opción new connection. Conéctese a la base de datos con el usuario y contraseña que creó anteriormente, la url de la base de datos es el Endpoint que aparece en Connectivity and Security.
Diríjase a la opción Extensions en la parte izquierda de la herramienta, busque e instale la extensión SQL Server Import.
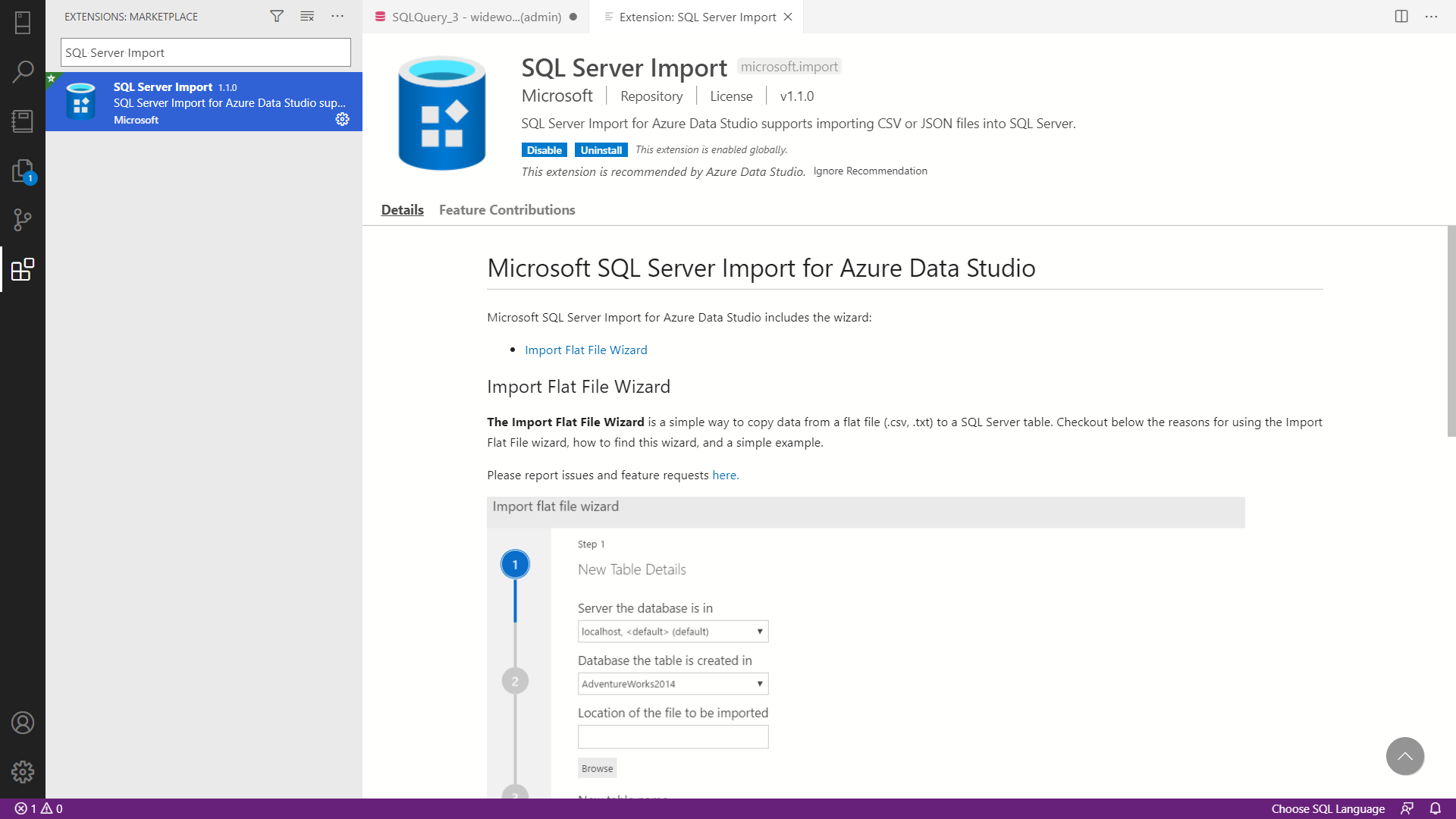
Una vez realizado esto, haga clic derecho sobre sobre su base de datos, vaya a la opción New Query y cree una nueva base de datos. Ahora, haga clic derecho sobre la nueva base de datos que creó y seleccione la opción Import Wizard. A continuación, importe todos los archivos .CSV adjuntos para crear la base de datos.
Una vez importadas las tablas, borre sus registros para evitar conflictos en el ejercicio de este taller usando las siguientes sentencias SQL:
DELETE FROM WWImportersDWH.dbo.city;
DELETE FROM WWImportersDWH.dbo.date_table;
DELETE FROM WWImportersDWH.dbo.employee;
DELETE FROM WWImportersDWH.dbo.fact_order;
DELETE FROM WWImportersDWH.dbo.package;
DELETE FROM WWImportersDWH.dbo.stockitem_historia_update;
A continuación, es necesario crear un nuevo Rol de IAM para ejecutar los flujos de Glue, no es posible utilizar el mismo que se tuvo en el taller anterior, pues esta vez el rol IAM necesitará acceso a las bases de datos relaciones. Busque IAM en la página de AWS, diríjase a Roles y después a Crear un rol. Como caso de uso, seleccione Glue y en permisos, otorgue los permisos: AWSGlueServiceRole, AmazonS3FullAccess, AmazonRDSFullAccess.
A continuación, en AWS diríjase a VPC y haga clic sobre la opción Endpoints que encuentra en el panel izquierdo.
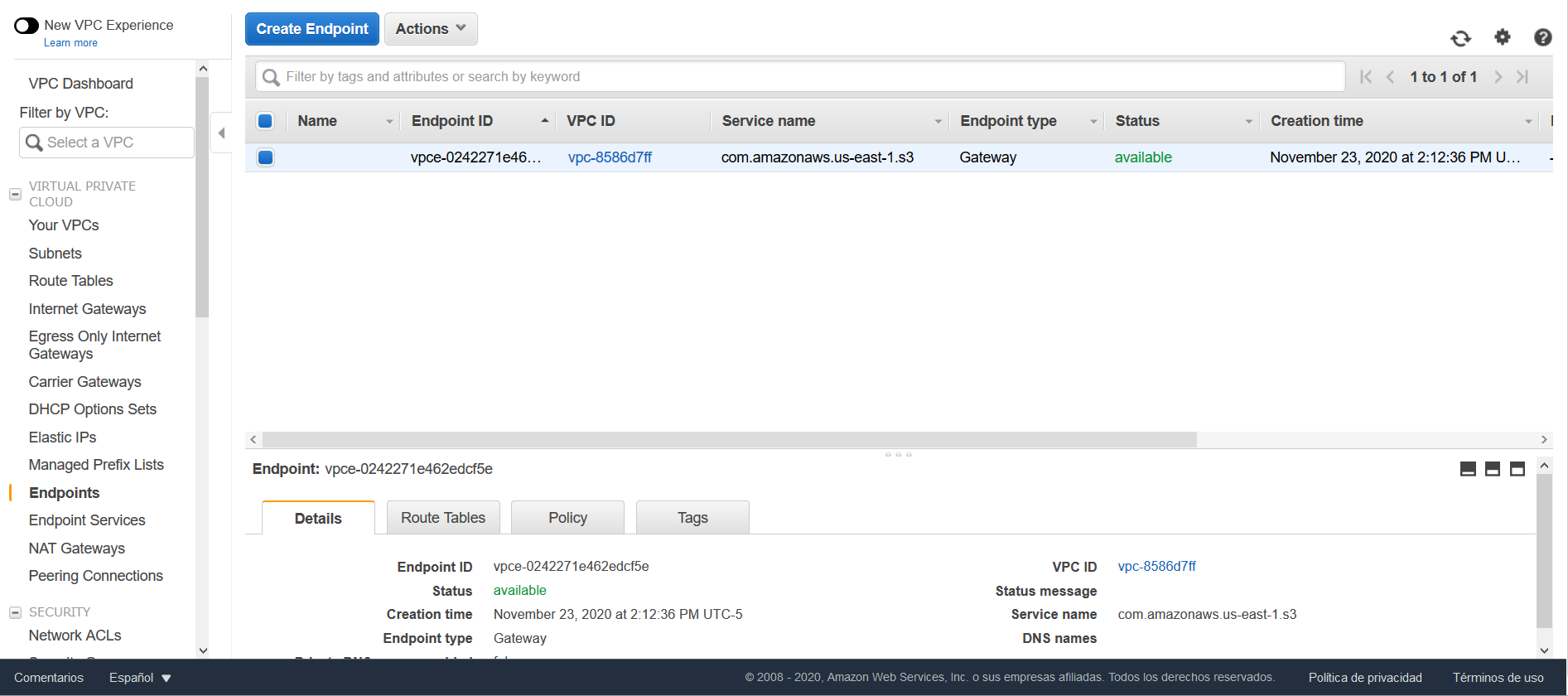
Haga clic en la opción Create Endpoint. En la opción Service category seleccione AWS services y en la opción Service Name seleccione com.amazonaws.us-east-1.s3.
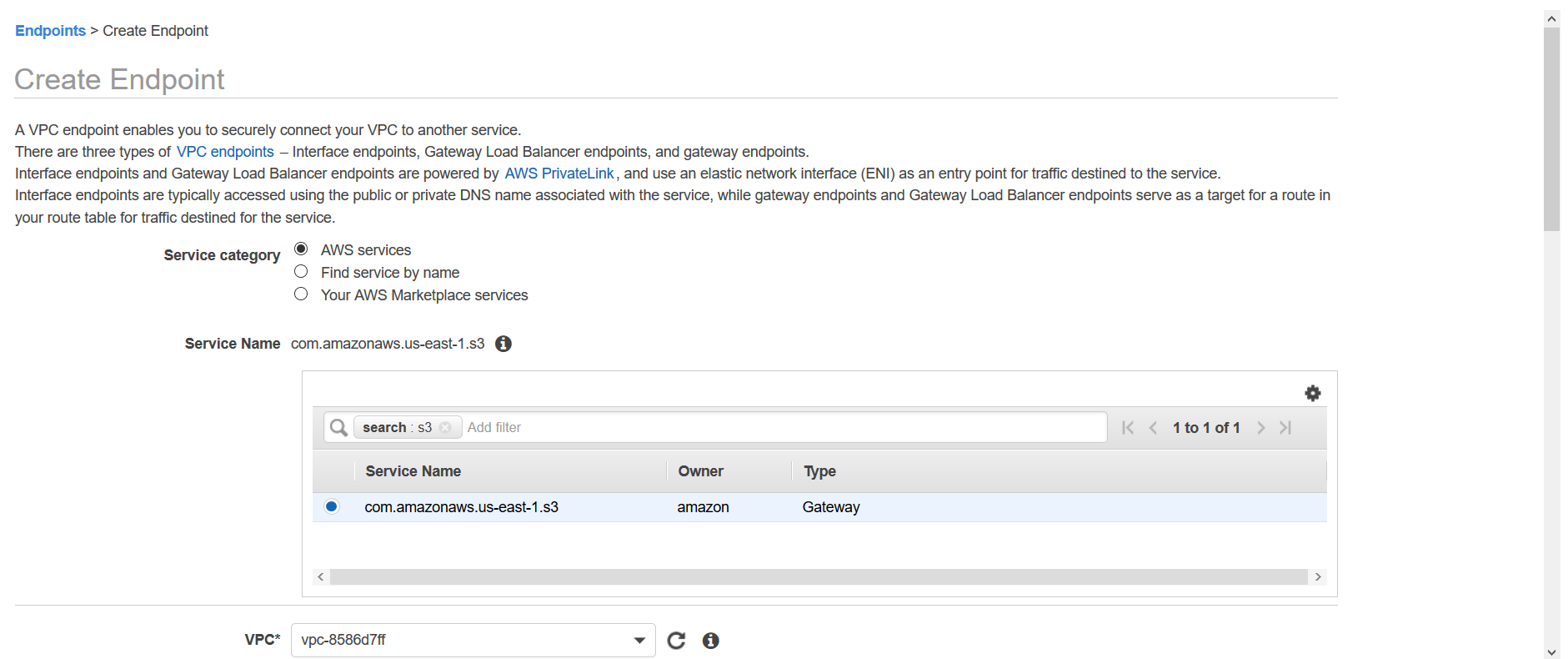
Ahora, diríjase a AWS Glue, vaya a conexiones y allí haga clic sobre la opción Añadir una conexión. En la opción Tipo de conexión seleccione Amazon RDS y para Motor de base de datos seleccione Microsoft SQL Server.
La instancia que seleccione debe ser la instancia de RDS que fue creada al principio del tutorial y el nombre de la base de datos es la que se creó utilizando Azure Data Studio.
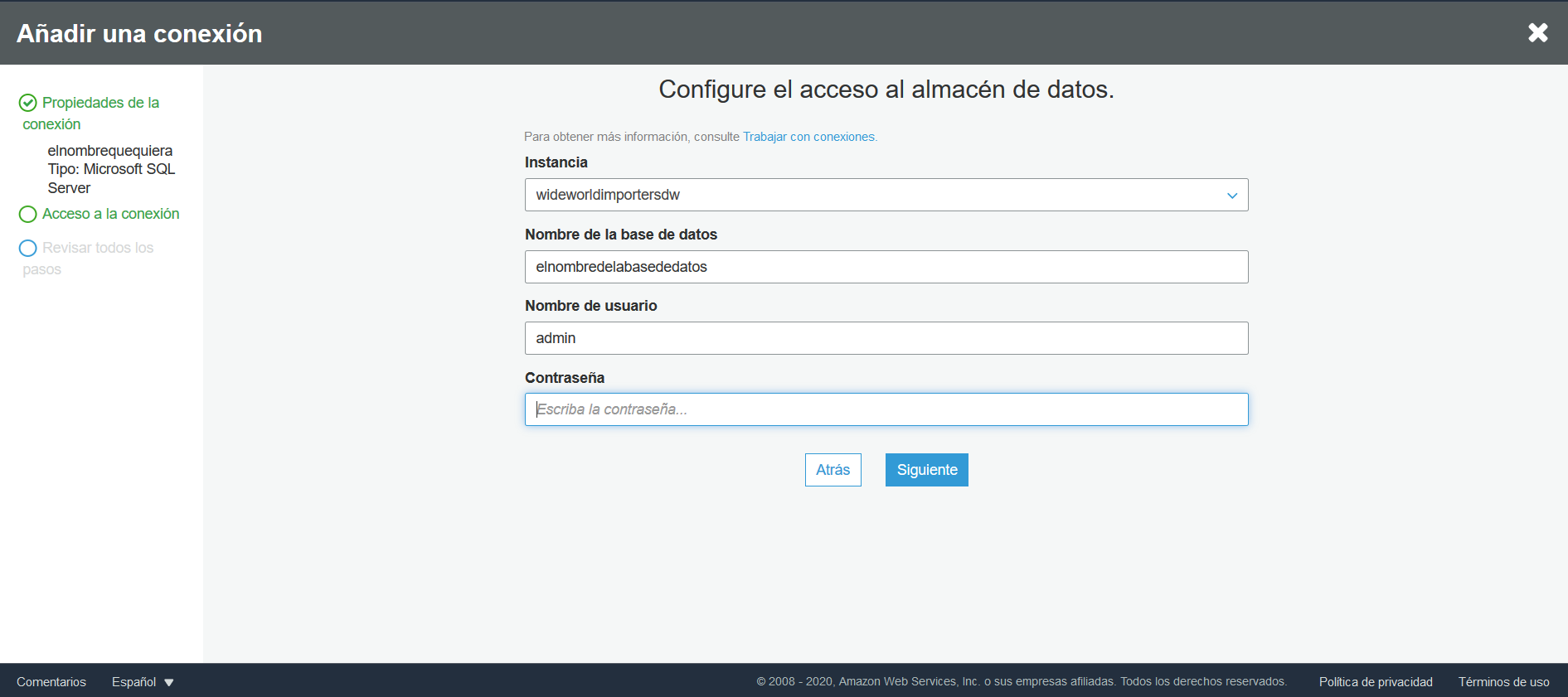
Una vez creada y probada la conexión, se debe crear un rastreador. Para esto, diríjase a la opción Rastreadores y Añadir un rastreador. Especifique el nombre que quiera, en la sección Specify crawler source type mantenga las opciones que salen por defecto, en la sección de Añada un almacén de datos seleccione JDBC como almacén de datos y de conexión escoja la que fue creada anteriormente, en Ruta de inclusión ingrese el nombre de su base de datos, después haga clic en siguiente.
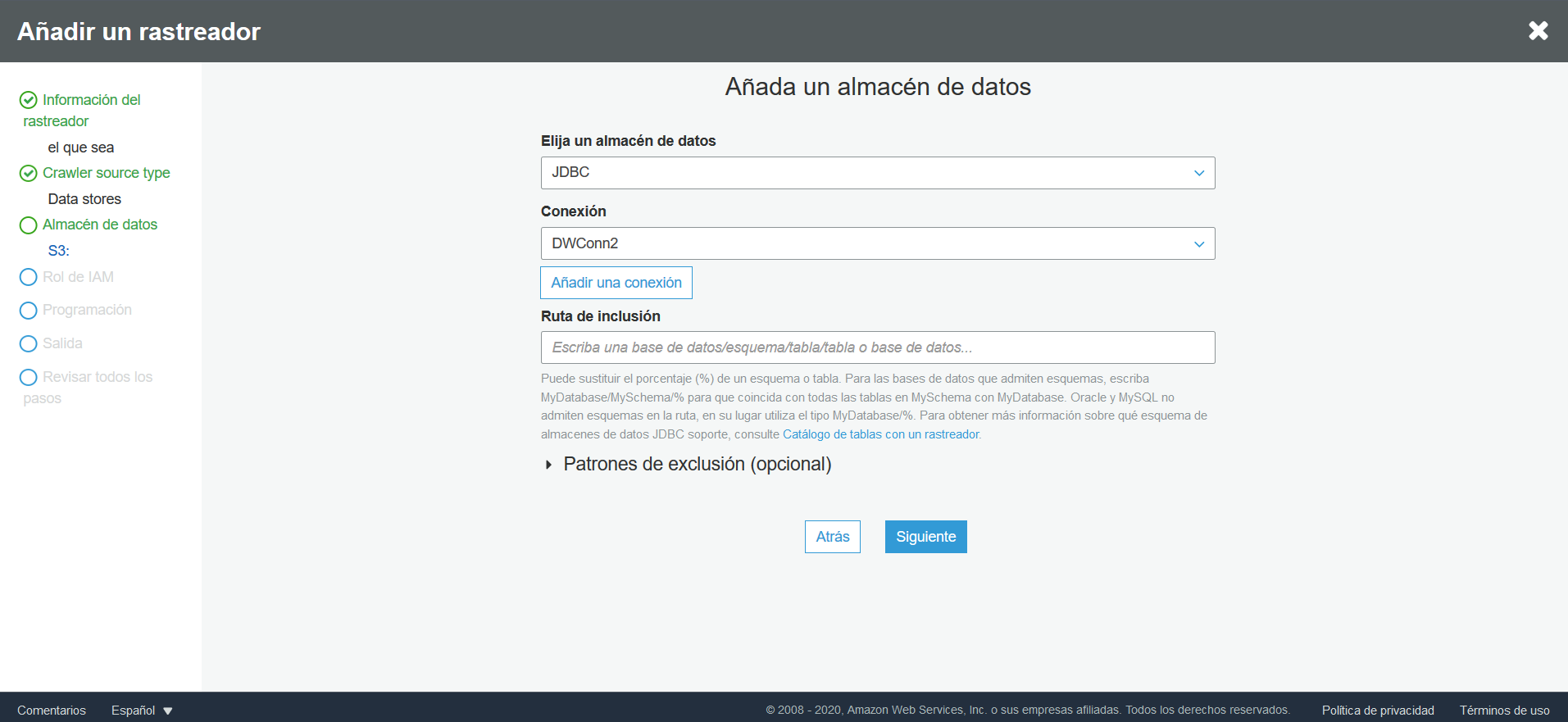
En la sección de Añadir otro almacén de datos seleccione No. Cuando se le pida que especifique el rol IAM, seleccione el que se creó en este tutorial. Finalmente, en frecuencia, seleccione ejecutar bajo demanda y cuando le pregunten la base de datos donde se guardarán los esquemas, cree una nueva.
Una vez creado el rastreador, ejecútelo.
WideWorldImporters ha determinado que existe la posibilidad de que un StockItem cambie su color. En vista de esto, se debe modificar el flujo de trabajo de AWS Glue para darle este manejo. Se ha decidido que el manejo que se le debe dar a la historia será tipo 2, es decir, por cada cambio en una entidad de la dimensión, se deberá insertar una nueva fila en la tabla.
De acuerdo con esto, es necesario modificar el flujo de ETL para realizar el manejo de historia. Puntualmente, es necesario añadir una serie de transformaciones en AWS Glue al final del flujo regular del ETL para la dimensión de Stockitems, se deben realizar las siguientes operaciones:
- Leer los datos ya existentes en el Data Warehouse y traer la última versión de cada Stockitem.
- Identificar los Stockitems que son nuevos e insertarlos en el Data Warehouse.
- Para los Stockitems para los que cambió el color, insertar un nuevo registro con el nuevo color y modificar el registro existente, cambiando el date_to para indicar que el registro existente se ha vencido.
En primer lugar, se cargan los datos ya existentes en la base de datos para Stockitems:
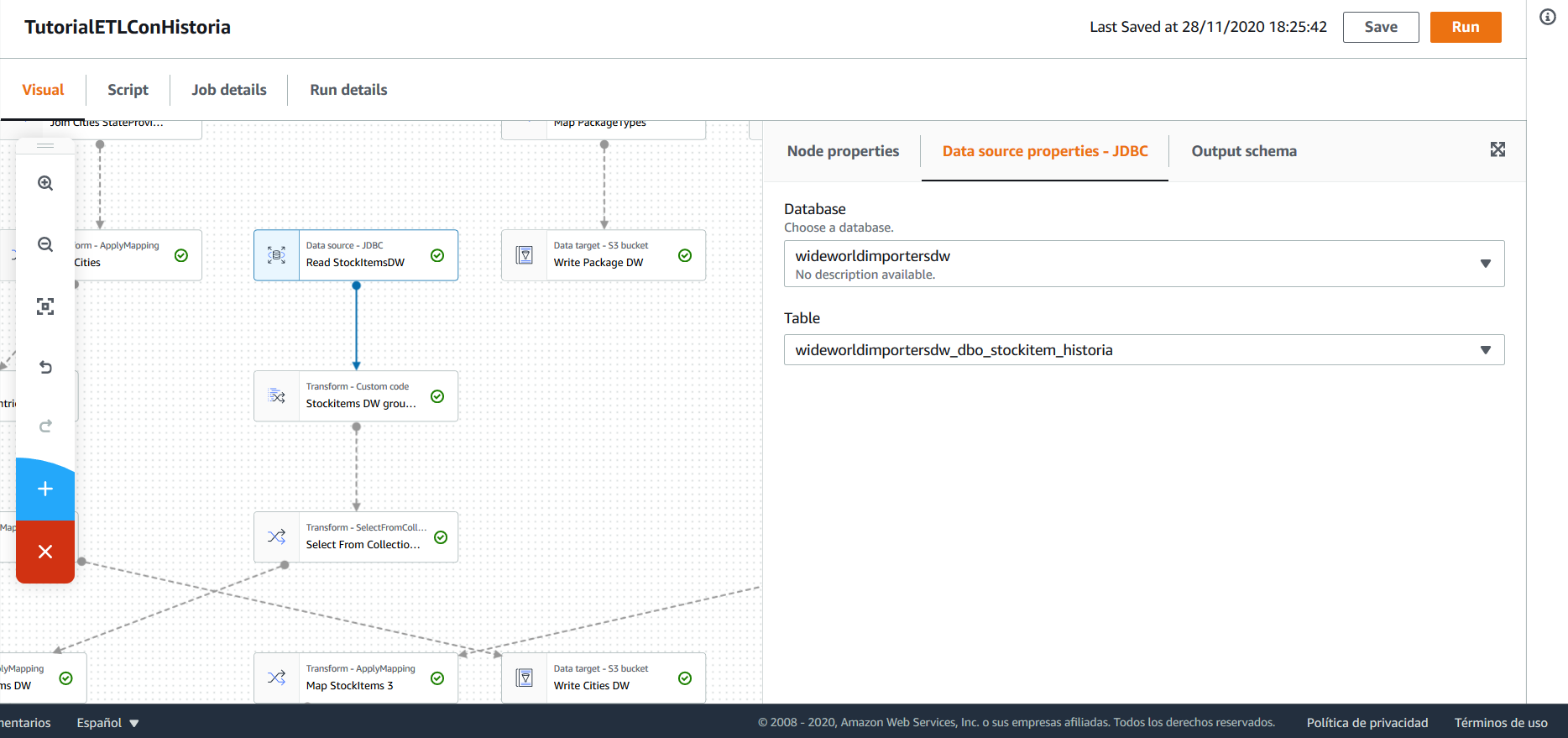
A continuación, se hace una transformación personalizada. En esta transformación, se utiliza la función partition de PySpark para obtener la última versión de cada Stockitem que haya en la base de datos.

El código de la transformación es el siguiente:
def StockItemsDWGroupByMax (glueContext, dfc) -> DynamicFrameCollection:
from pyspark.sql.window import Window
from pyspark.sql.functions import rank, col
df = dfc.select(list(dfc.keys())[0]).toDF()
window = Window.partitionBy(df['wwi_stock_item_id']).orderBy(df['_version'].desc())
df = df.select('*', rank().over(window).alias('rank')).filter(col('rank') == 1)
df = df.drop('rank')
df = DynamicFrame.fromDF(df, glueContext, "StockItemsDWGroupByMax")
return (DynamicFrameCollection({"StockItemsDWGroupByMax": df}, glueContext))
Tras esto, preparándose a realizar el join con los stockitems que se están procesando, se realiza un mapping tras el que se mantienen únicamente las columnas _version, color, date_from, date_to además de la llave natural y la llave subrogada, igualmente, se modifican los nombres de las columnas, añadiendo el prefijo pre.
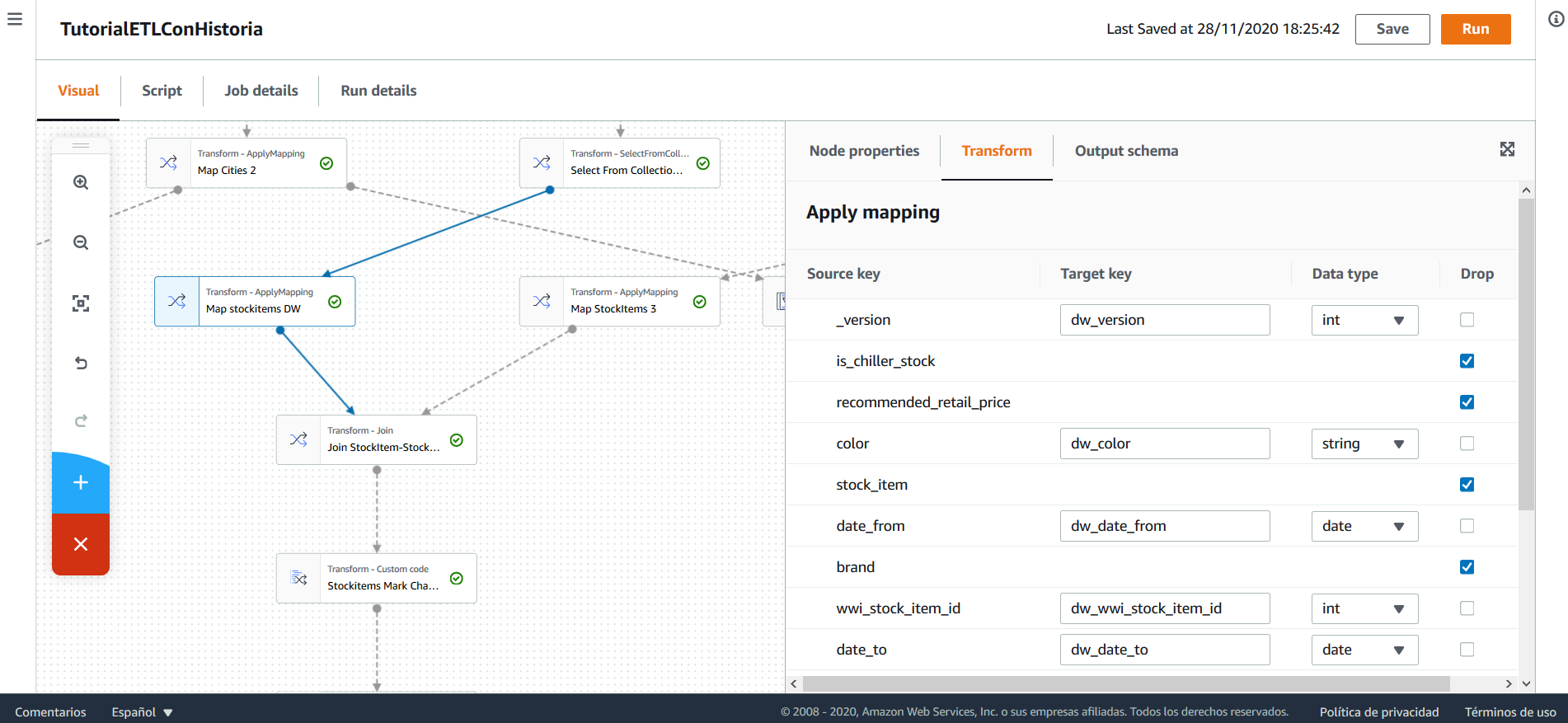
Se realiza un join entre las últimas versiones de los stockitems en el DW y los stockitems del archivo. El join se hace left, de modo que se mantengan todos los stockitems que se están procesando, pero se ignore cualquier registro que pueda existir en el DW pero no en el archivo que se procesa.
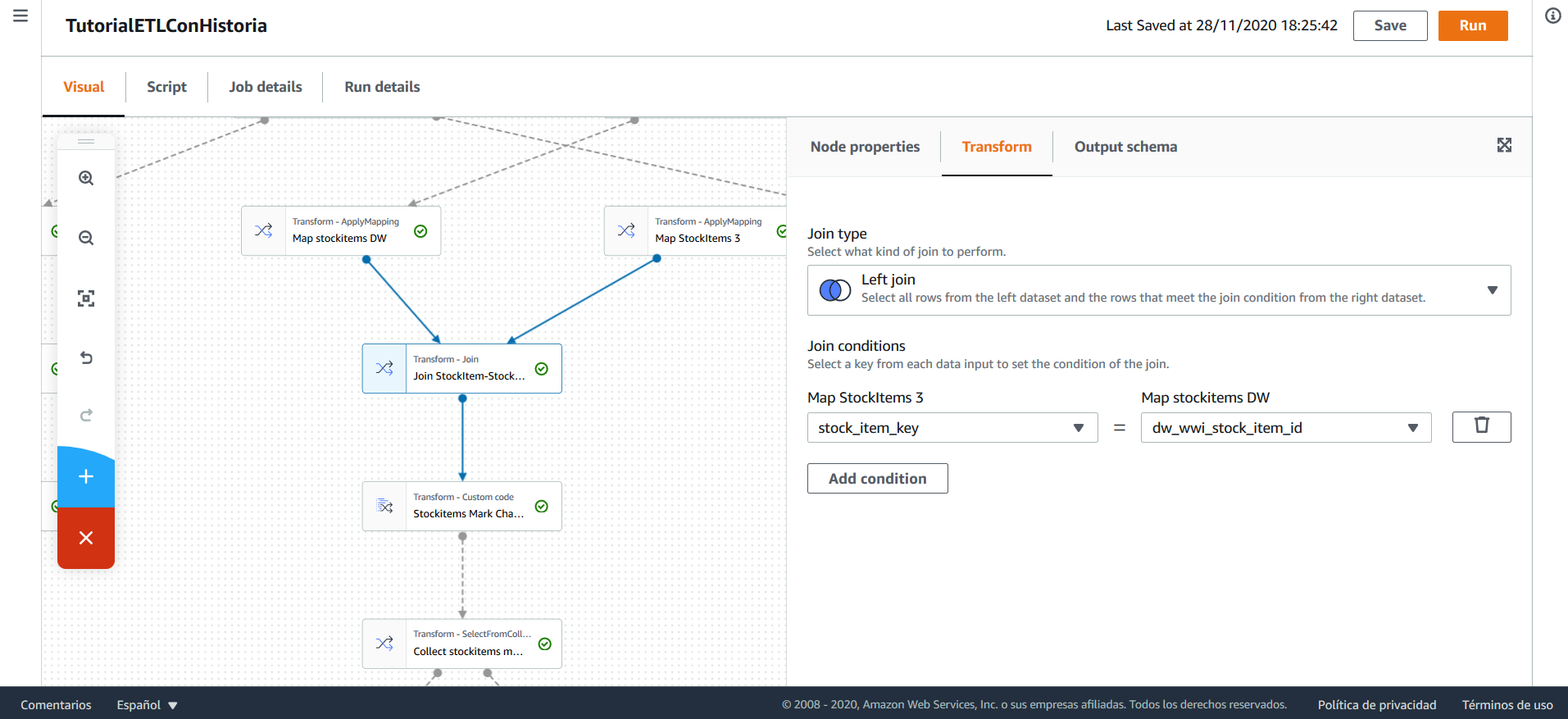
A continuación, se realiza una transformación personalizada, que tiene varias tareas:
- Identifica tres tipos de registros, (a) los registros nuevos -cuya llave natural no existe en el Data Warehouse-, (b) los registros cuya llave natural ya existe pero presentan cambios y (c) los registros cuya llave natural ya existe y no presentan cambios.
- En el caso (a): marca la fecha date_from como el día de ejecución del flujo, date_to como el 2199-12-31, _version como 1 y crea un nuevo id subrogado.
- Duplica cada registro del caso (b). Una de las copias se usa para actualizar los registros ya existentes en el Data Warehouse (b.1), manteniendo toda la información del DW pero actualizando date_to al día de la ejecución del flujo. La otra copia se usa para insertar un nuevo registro en el DW (b.2), este tiene date_from como el día de ejecución del flujo, date_to como el 2199-12-31, _version como la última versión que se tenía sumado 1, y crea un nuevo id para el registro.
- Ignora los registros del caso (c)
- Marca los registros del caso (a) y (b.2) como registros que se deben insertar, los del caso (b.1) como registros que se deben actualizar.
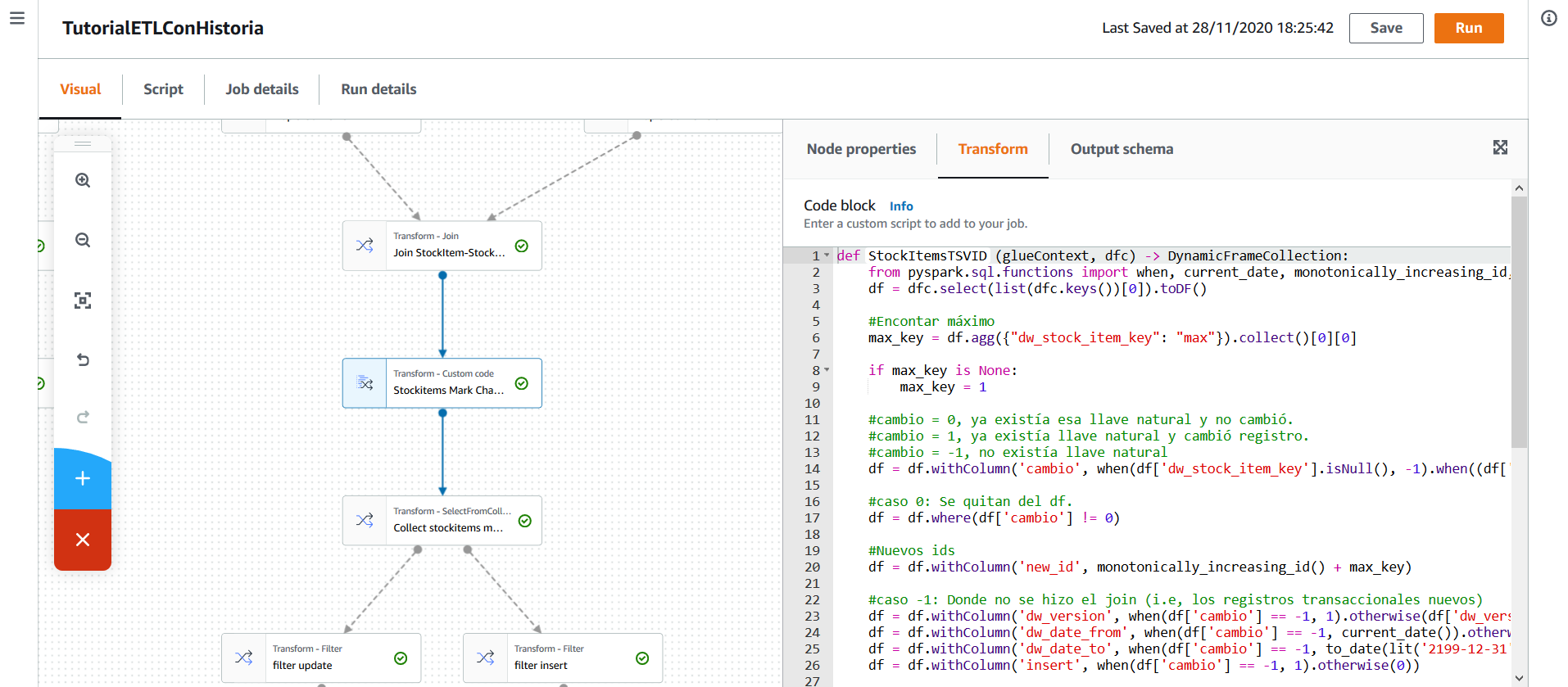
El código de la transformación es el siguiente:
def StockItemsTSVID (glueContext, dfc) -> DynamicFrameCollection:
from pyspark.sql.functions import when, current_date, monotonically_increasing_id, to_date, lit
df = dfc.select(list(dfc.keys())[0]).toDF()
#Encontar máximo
max_key = df.agg({"dw_stock_item_key": "max"}).collect()[0][0]
if max_key is None:
max_key = 1
#cambio = 0, ya existía esa llave natural y no cambió.
#cambio = 1, ya existía llave natural y cambió registro.
#cambio = -1, no existía llave natural
df = df.withColumn('cambio', when(df['dw_stock_item_key'].isNull(), -1)\
.when((df['dw_stock_item_key'].isNotNull()) & ((df['color'] == df['dw_color']) | (df['color'].isNull() & df['color'].isNull())), 0)\
.otherwise(1))
#caso 0: Se quitan del df.
df = df.where(df['cambio'] != 0)
#Nuevos ids
df = df.withColumn('new_id', monotonically_increasing_id() + max_key)
#caso -1: Donde no se hizo el join (i.e, los registros transaccionales nuevos)
df = df.withColumn('dw_version', when(df['cambio'] == -1, 1).otherwise(df['dw_version']))
df = df.withColumn('dw_date_from', when(df['cambio'] == -1, current_date()).otherwise(df['dw_date_from']))
df = df.withColumn('dw_date_to', when(df['cambio'] == -1, to_date(lit('2199-12-31'), 'yyyy-MM-dd')).otherwise(current_date()))
df = df.withColumn('insert', when(df['cambio'] == -1, 1).otherwise(0))
#caso 1:
# 1.1 Es necesario editar existentes: poner dw_date_to como fecha actual. Después, actualizar en la base de datos (NO INSERTAR)
# 1.2 Es necesario crear nueva fila, identica a anterior excepto que : _version = _version + 1, date_from = hoy, date_to = 2199-12-31
df_dup = df.where(df['cambio'] == 1)
#1.2
df_dup = df_dup.withColumn('dw_version', df_dup['dw_version'] + 1)
df_dup = df_dup.withColumn('dw_date_from', current_date())
df_dup = df_dup.withColumn('dw_date_to', to_date(lit('2199-12-31'), 'yyyy-MM-dd'))
#df_dup = df_dup.withColumn('dw_color', df_dup['color'])
df_dup = df_dup.withColumn('insert',lit(1))
#Juntar tablas
df = df.union(df_dup)
df = df.drop('cambio')
df = DynamicFrame.fromDF(df, glueContext, "StockItemsTSVID")
return (DynamicFrameCollection({"StockItemsTSVID": df}, glueContext))
Habiendo identificado los registros que se deben actualizar, se realiza un filtro que mantiene únicamente estos registros.
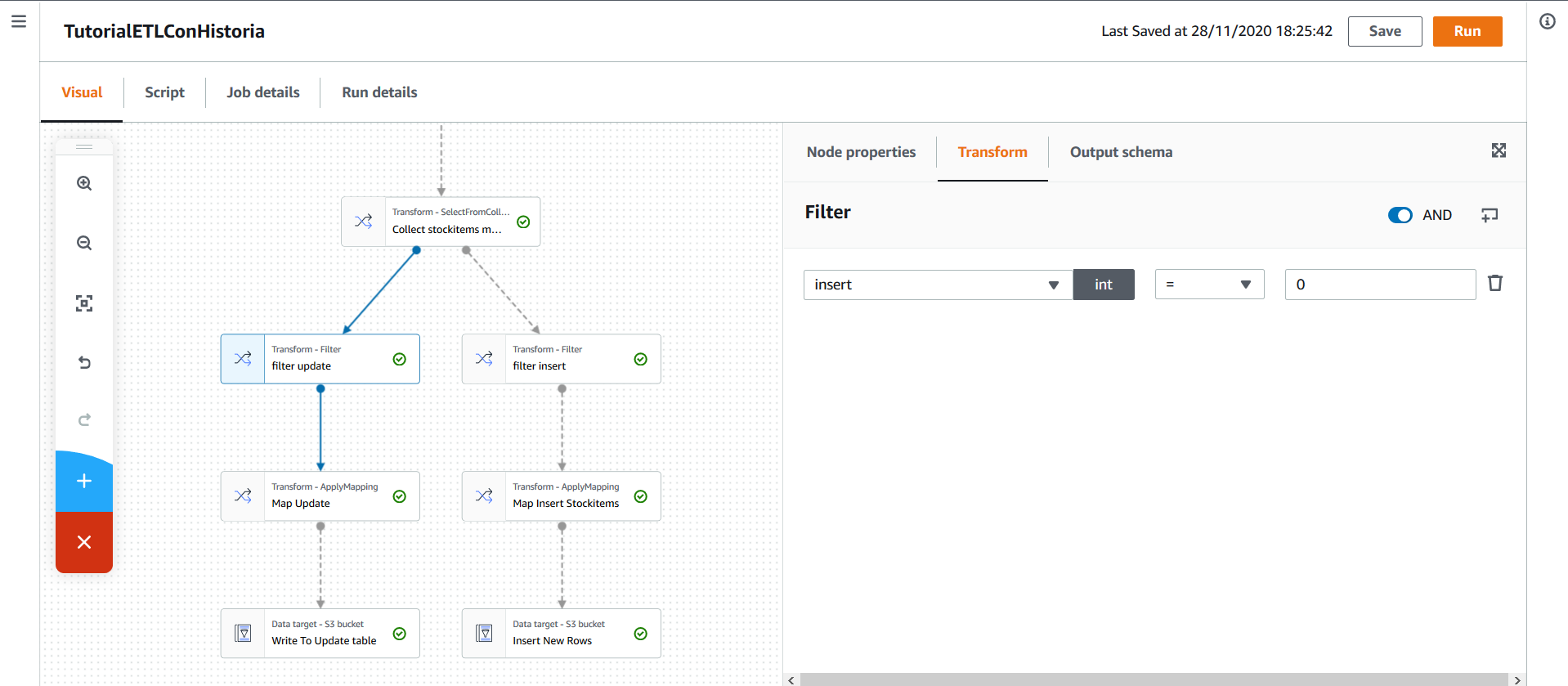
Tras esto, los nombres de las columnas se cambian. Como se debe actualizar únicamente date_to, se mantiene las columnas correspondientes a la llave subrogada y a la fecha.
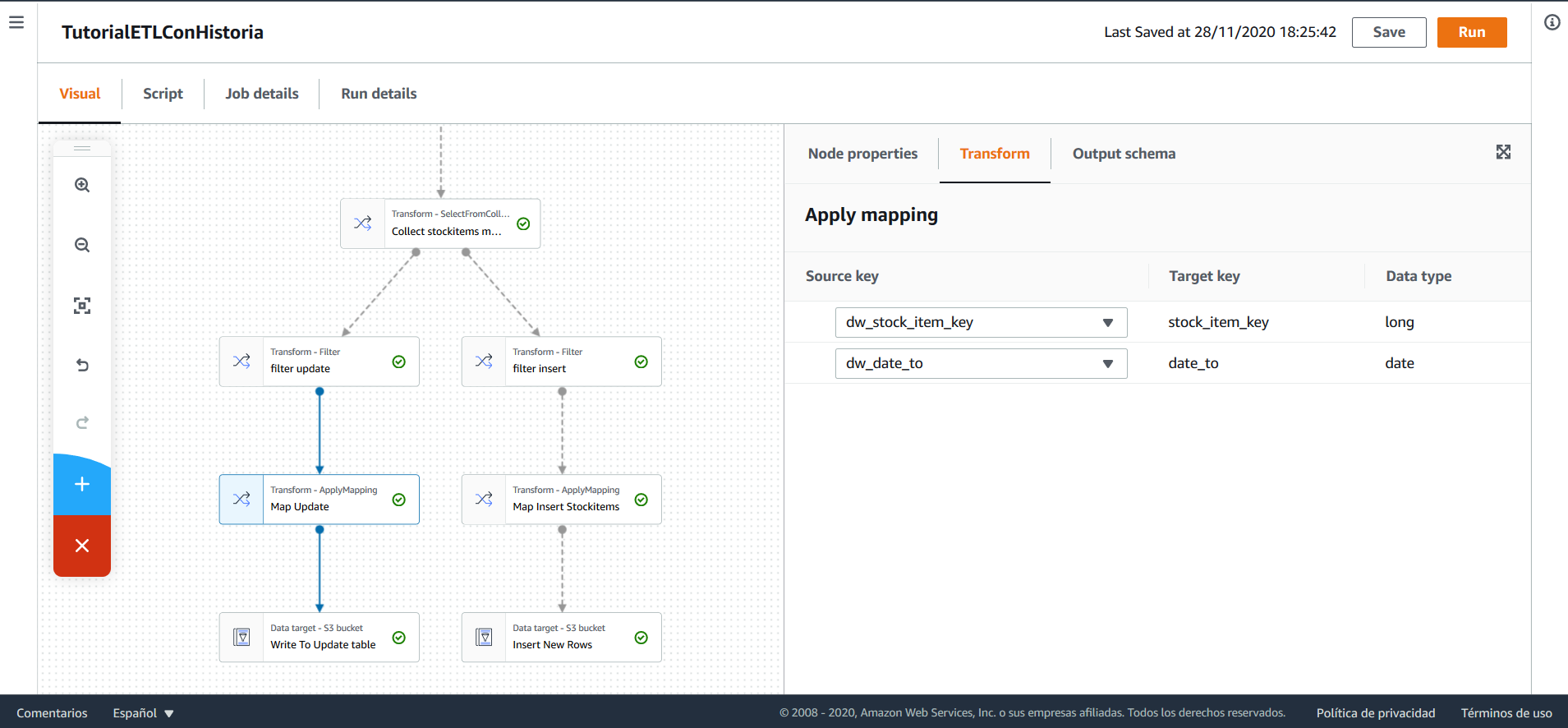
Debido a que AWS Glue no soporta actualizar tablas directamente, es necesario que los registros correspondientes a las actualizaciones se inserten en una tabla auxiliar y después, utilizando una sentencia SQL, actualizar la tabla original a partir de la auxiliar.
Para esto, los registros que se deben actualizar, se insertan en una tabla en el Data Warehouse de nombre stockitems_historia_update. Esta tabla contiene únicamente las columnas date_from y stock_item_key, que corresponden a la fecha de vencimiento de un registro y a la llave subrogada del mismo.
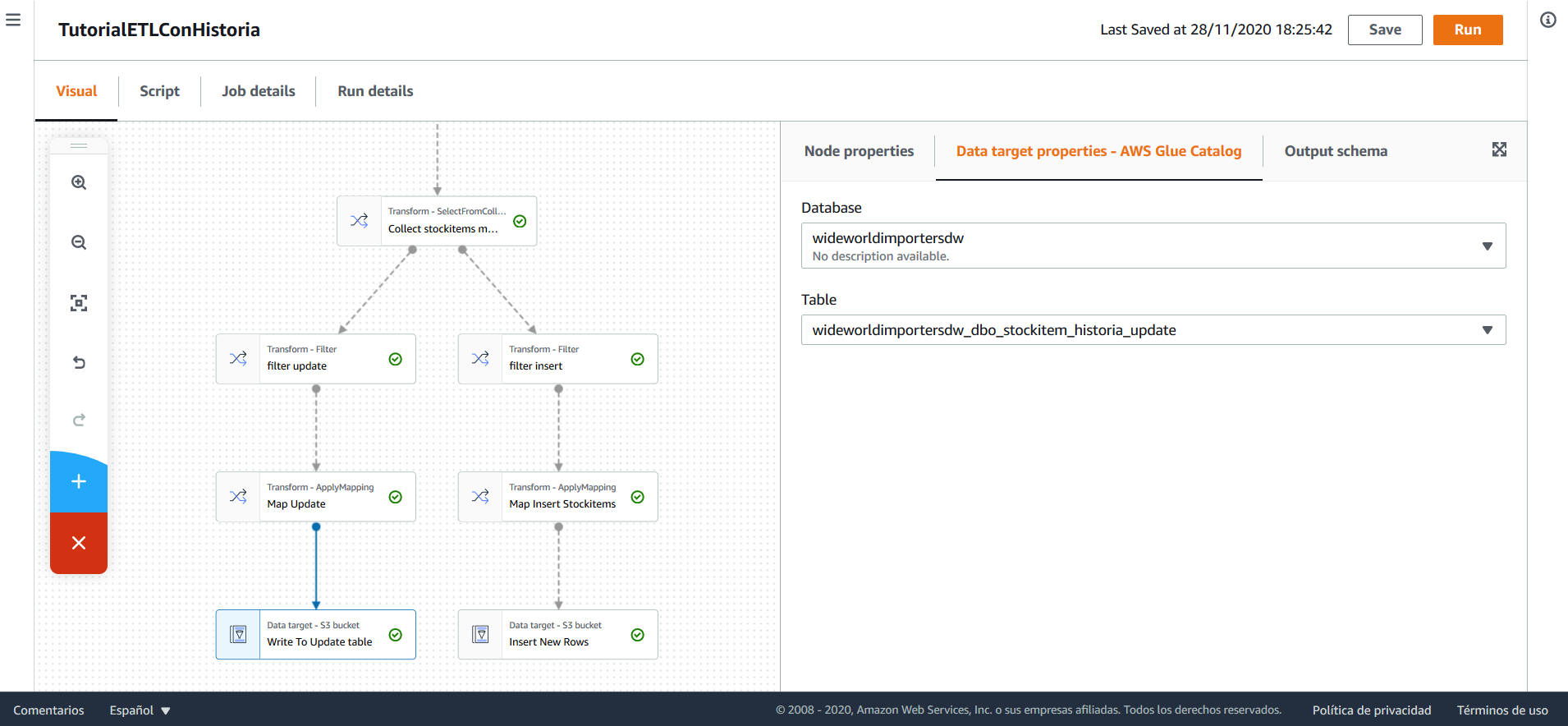
Una vez ejecutado el flujo en AWS Glue, es necesario ejecutar una sentencia SQL para actualizar la tabla de stockitem_historia a partir de la tabla auxiliar stockitem_historia_update:
UPDATE
Table_A
SET
Table_A.Date_to = Table_B.date_to
FROM
WideWorldImportersDW.dbo.stockitem_historia AS Table_A
INNER JOIN WideWorldImportersDW.dbo.stockitem_historia_update AS Table_B
ON Table_A.Stock_Item_Key = Table_B.Stock_Item_Key;
Tras esto, borrar los registros de la tabla auxiliar con:
TRUNCATE TABLE WideWorldImportersDW.dbo.stockitem_historia_update;
Igualmente, se hace el filtro de los registros que se deben insertar.
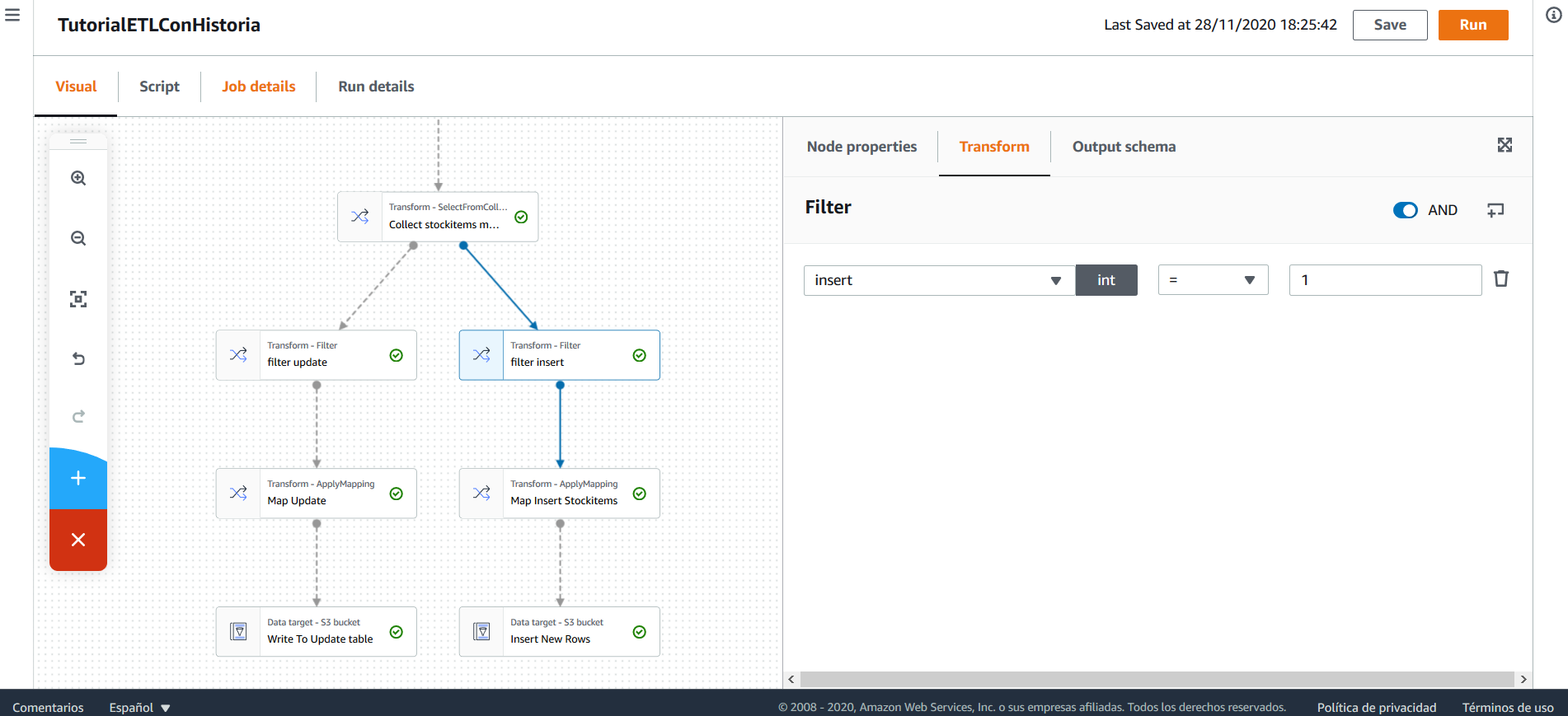
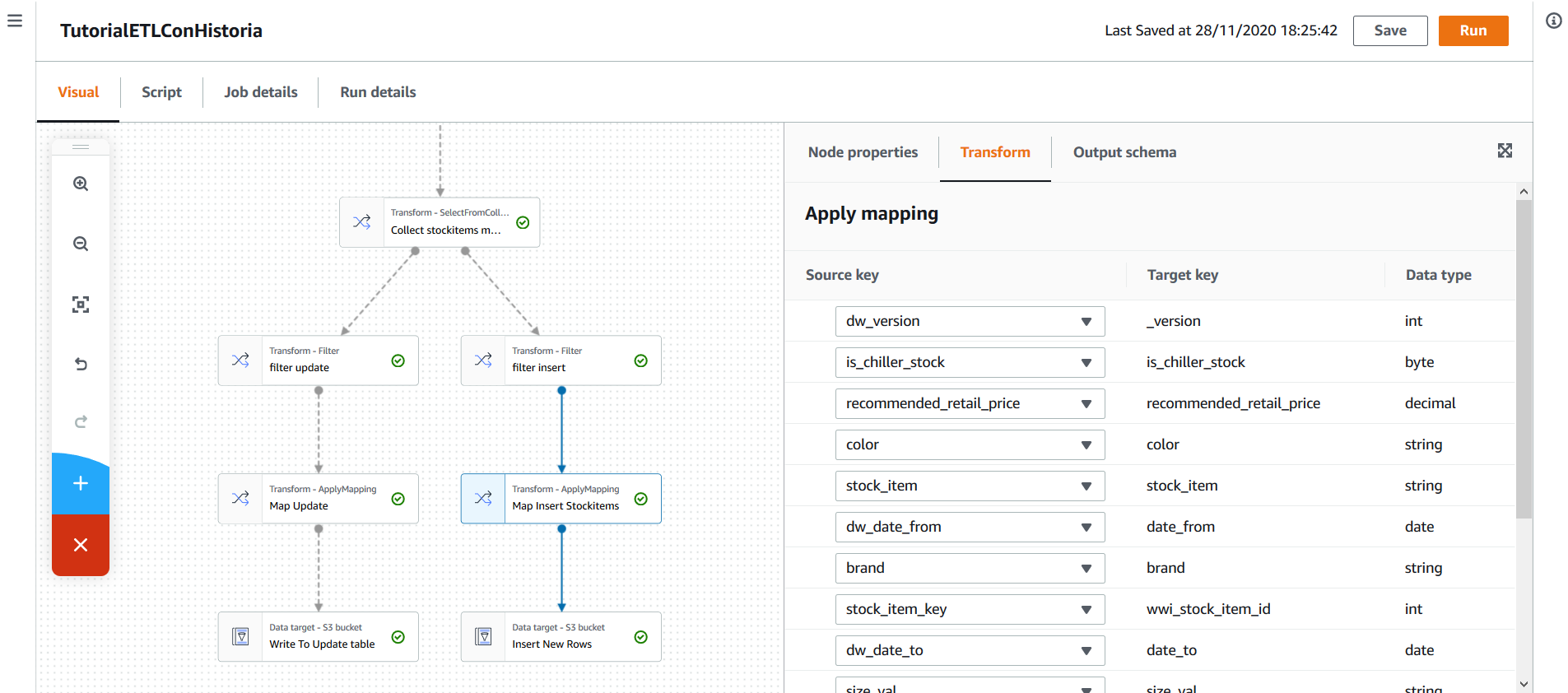
Tras esto, se hace un mapping para darle el nombre correcto a las columnas y, finalmente, se insertan en la tabla stockitem_historia.
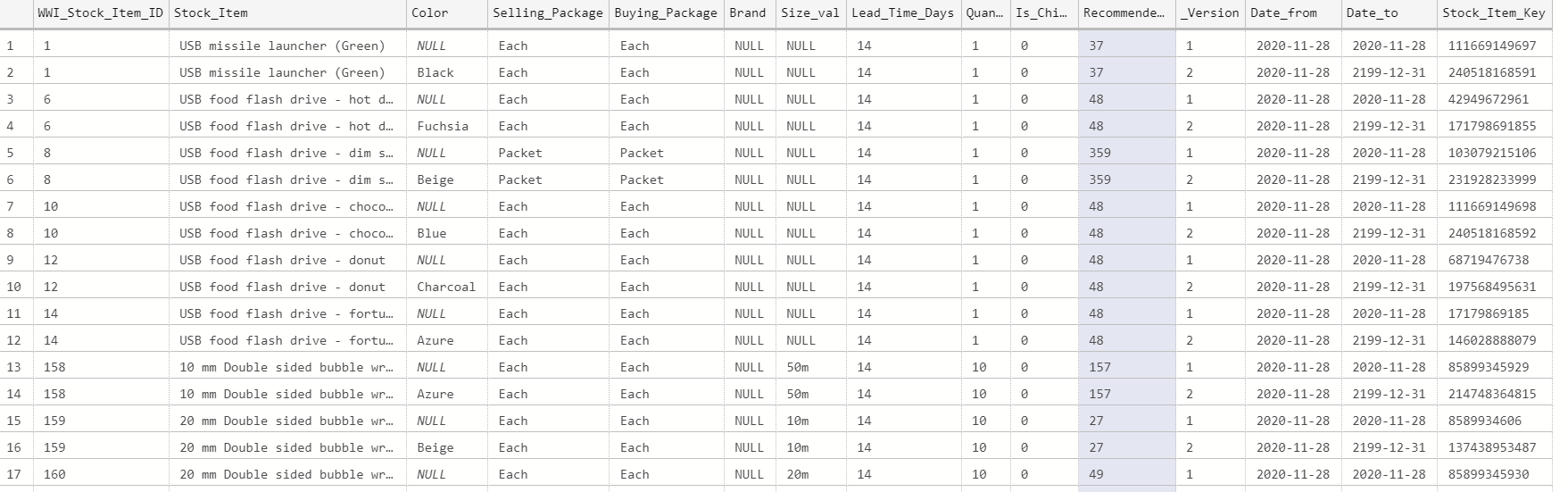
Al ejecutar el flujo y la sentencia de SQL, puede observarse, en el Data Warehouse, los cambios que se presentaron en la historia de la dimensión:
Si desea explorar a detalle el flujo, podrá encontrar el script en los anexos.
Se ha determinado que el atributo CustomerCategory de un cliente puede cambiar. Sin embargo, se quiere comparar este manejo de historia con el de otro tipo, Seleccione otro tipo y compare las dos alternativas. Modifique el flujo que construyó en taller anterior y utilice la base de datos que aprovisionó en AWS para manejar adecuadamente la historia de este atributo. En anexos encontrará los archivos Sales.Customers.csv y Sales.Customers_incremental.csv, el primero deberá usarlo para la carga inicial y el segundo para la incremental. El entregable correspondiente a este laboratorio es el script de Python generado por AWS Glue.
Al terminar este tutorial, ya sabe cómo configurar y realizar ETLs con historia en AWS Glue. Ya conoce cómo puede utilizar AWS RDS y cómo conectarlo con AWS Glue.
- Puede encontrar la documentación de AWS Glue en el siguiente enlace: https://docs.aws.amazon.com/glue/index.html
- Para saber más sobre las técnicas de manejo de historia, consulte el libro The Data Warehouse Toolkit, Third Edition. John Wiley & Sons, Inc, 2013 de Ralph Kimball y Margy Ross que podrá encontrar en la biblioteca de la universidad.