¿Qué aprenderá?
En este tutorial aprenderá a configurar la herramienta AWS Glue y la forma de crear un proceso de ETL básico.
¿Qué construirá?
Construirá Un ETL que tomará datos crudos de WideWorldImporters y los limpiará de acuerdo a un modelo multidimensional definido para usted.
¿Para qué?
La construcción de ETLs que se ajusten a modelos multidimensionales es un paso necesario dentro de un proceso de integración de datos, pues permite tomar los datos crudos de una fuente, generalmente transaccional, para transformarlos en datos limpios que puedan utilizarse para la toma de decisiones.
En este tutorial, utilizará AWS Glue para crear y ejecutar un ETL. Este es un servicio en la nube, ofrecido por Amazon Web Services, diseñado para crear, ejecutar y monitorear flujos ETL. AWS Glue ofrece una herramienta gráfica para crear ETLs, como también permite crearlos programando scripts en Spark o PySpark. Si quiere conocer más sobre qué es AWS Glue, puede consultar el siguiente enlace: https://aws.amazon.com/glue/
¿Qué necesita?
Los datos y el código a ejecutar lo puede encontrar en el repositorio: https://github.com/MIAD-Modelo-Datos/Recursos/tree/main/Glue
- Archivos CSV de WWI
- Archivo .py a ejecutar
- AWS: S3, Glue. Los costos asociados deberán ser asumidos por los estudiantes, bajo ningún motivo la universidad garantizará estos recursos
- Cuenta AWS educate o propia
Adquisición de una cuenta AWS
Antes de iniciar este tutorial, debe conseguir una cuenta de AWS. Para esto, ingrese a la página web https://aws.amazon.com/education/awseducate/ y haga clic en la opción Unirse a AWS Educate.
Ingrese su rol, en este caso estudiante, y complete la información que le solicitan. Asegúrese de utilizar su correo de la Universidad de los Andes.
Una vez su cuenta haya sido aprobada, inicie sesión en AWS educate, vaya a la opción AWS Account y allí, haga clic en AWS Educate Starter Account.
Esto abre una nueva pestaña, en la nueva pestaña seleccione la opción AWS Console, con lo que se accede a AWS.
II. Creación de un espacio de almacenamiento con AWS S3
Para poder utilizar el servicio de AWS Glue, es conveniente tener los datos con los que se va a trabajar en la nube. Para esto, se utiliza AWS S3, esto es un servicio de AWS que permite almacenar archivos en la nube.
Para aprovisionar este servicio, busque el término S3 en la pantalla principal de AWS y seleccione el servicio S3.
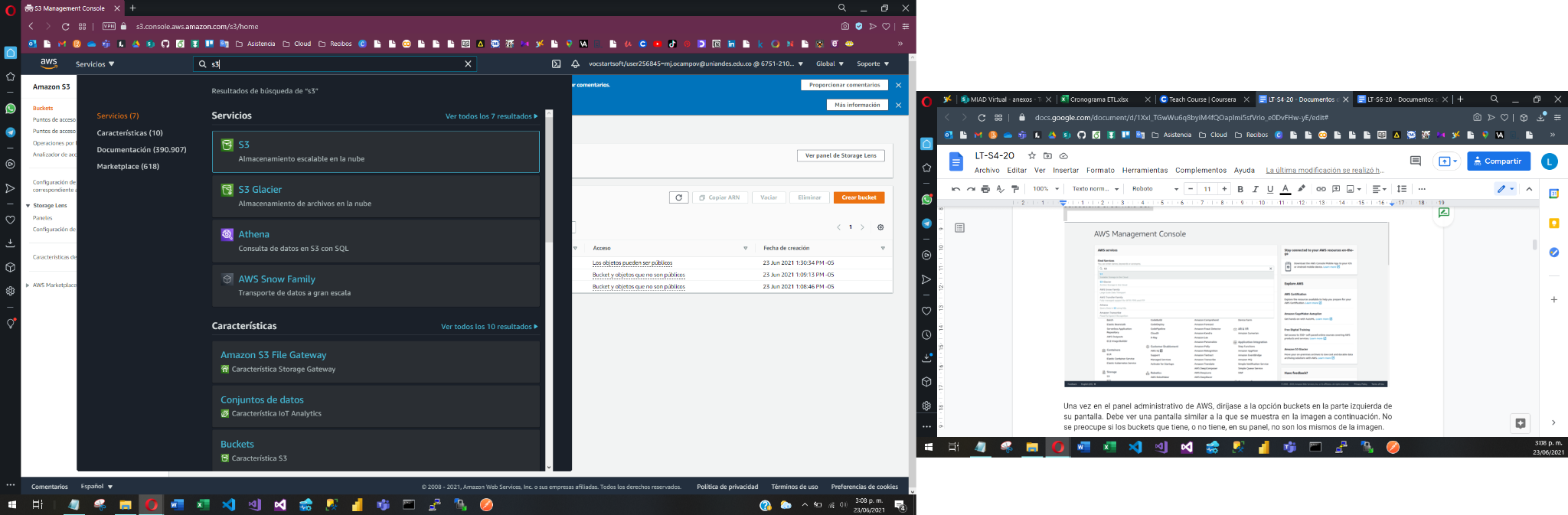
Una vez en el panel administrativo de AWS, diríjase a la opción buckets en la parte izquierda de su pantalla. Debe ver una pantalla similar a la que se muestra en la imagen a continuación. No se preocupe si los buckets que tiene, o no tiene, en su panel, no son los mismos de la imagen.

Ahora, proceda a crear dos buckets. Uno de estos buckets se usa para almacenar los datos crudos, sacados de la base de datos transaccional de WideWorldImportersTransactional mientras que el otro sirve para guardar los datos limpios en WideWorldImportersDWH, tras haber pasado por el ETL. Para crear un bucket, haga clic sobre el botón Create bucket, proceda a nombrar los buckets como wideworldimports y worldwideimportersdw respectivamente, y deje todas las demás opciones en su valor por defecto.
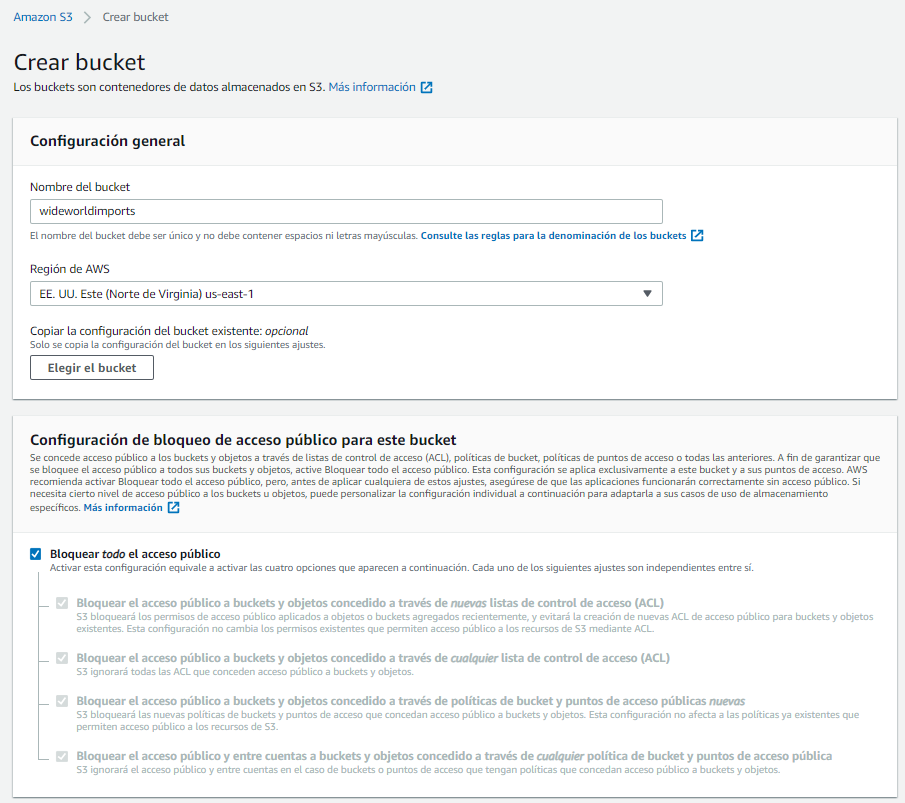
Una vez creados sus buckets, diríjase al bucket wideworldimports y suba los archivos csv correspondientes a las tablas de WideWorldImportersTransactional que se adjuntan en este tutorial.
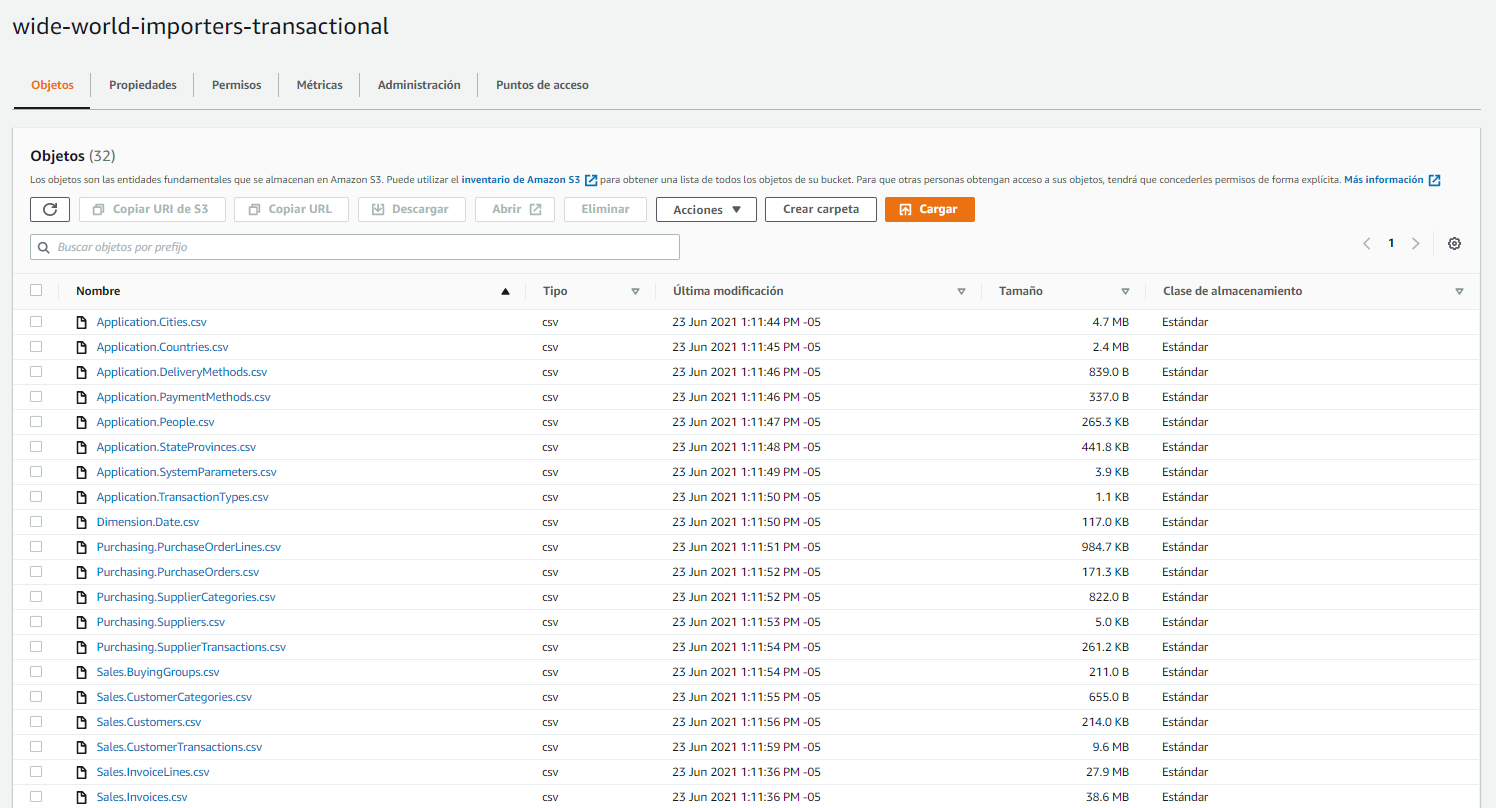
Ahora, diríjase a su bucket de datos limpios y cree las siguientes carpetas:
• city
• customer
• date_table
• employee
• fact_order
• package
• stockitem
Estas carpetas serán utilizadas más adelante para guardar los resultados del proceso ETL.
III. Configuración del Rol IAM
Un rol IAM es una serie de permisos asignados a un usuario o aplicación que permiten que esta acceda a servicios de AWS. Como se quiere crear un ETL en AWS Glue que lea los datos crudos y escriba los datos limpios en AWS S3, es necesario crear un rol de IAM con permisos sobre S3 y Glue.
Para empezar, busque el término IAM, en la página principal de AWS.
Una vez esté en el panel de IAM diríjase a Roles en la parte izquierda de su pantalla, allí puede encontrar listados varios roles que existen en AWS por defecto.
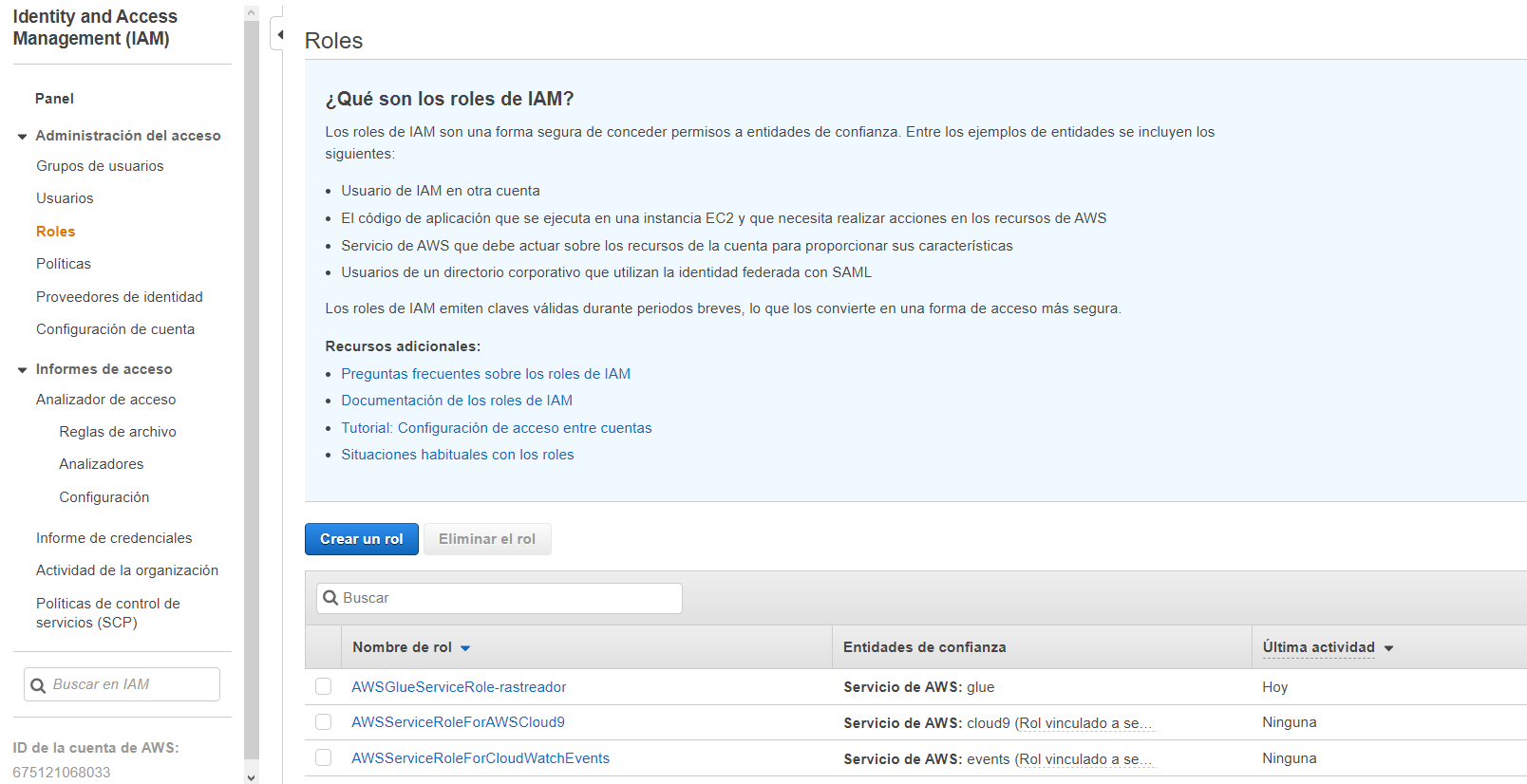
Haga clic sobre Crear un rol. En la nueva pantalla que se abre, para la opción Seleccionar el tipo de entidad de confianza elija Servicio de AWS y en la opción Elija un caso de uso seleccione Glue.
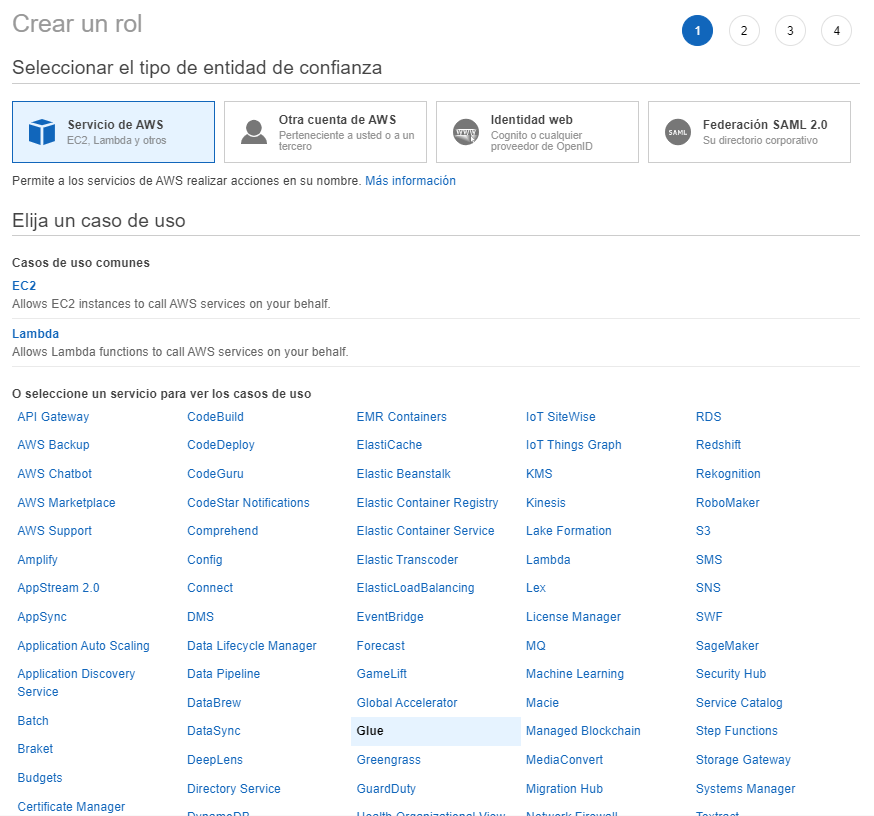
Haga clic en el botón Siguiente: Permisos, y en la lista de políticas busque y seleccione las políticas AmazonS3FullAccess y AWSGlueServiceRole.
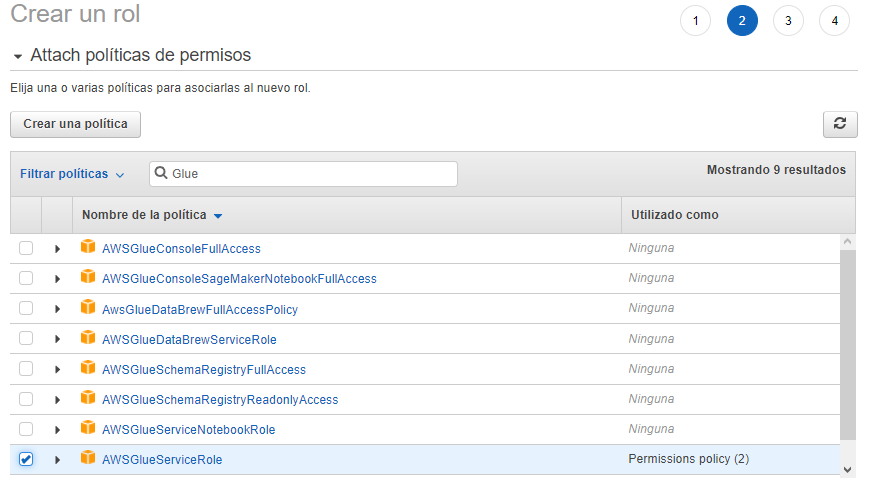
Una vez seleccionadas las políticas indicadas, haga clic sobre Siguiente dos veces, hasta llegar a la última pantalla, que le pide un nombre y una descripción para su nuevo rol. Asigne el nombre y descripción que desee, asegúrese que sea fácil recordar el nombre más adelante.
IV. Creación del esquema de datos
Para poder crear un ETL en AWS Glue, es necesario primero definir las bases de datos y las tablas de éstas. Para comenzar, busque AWS Glue en la página principal de AWS para dirigirse al servicio.
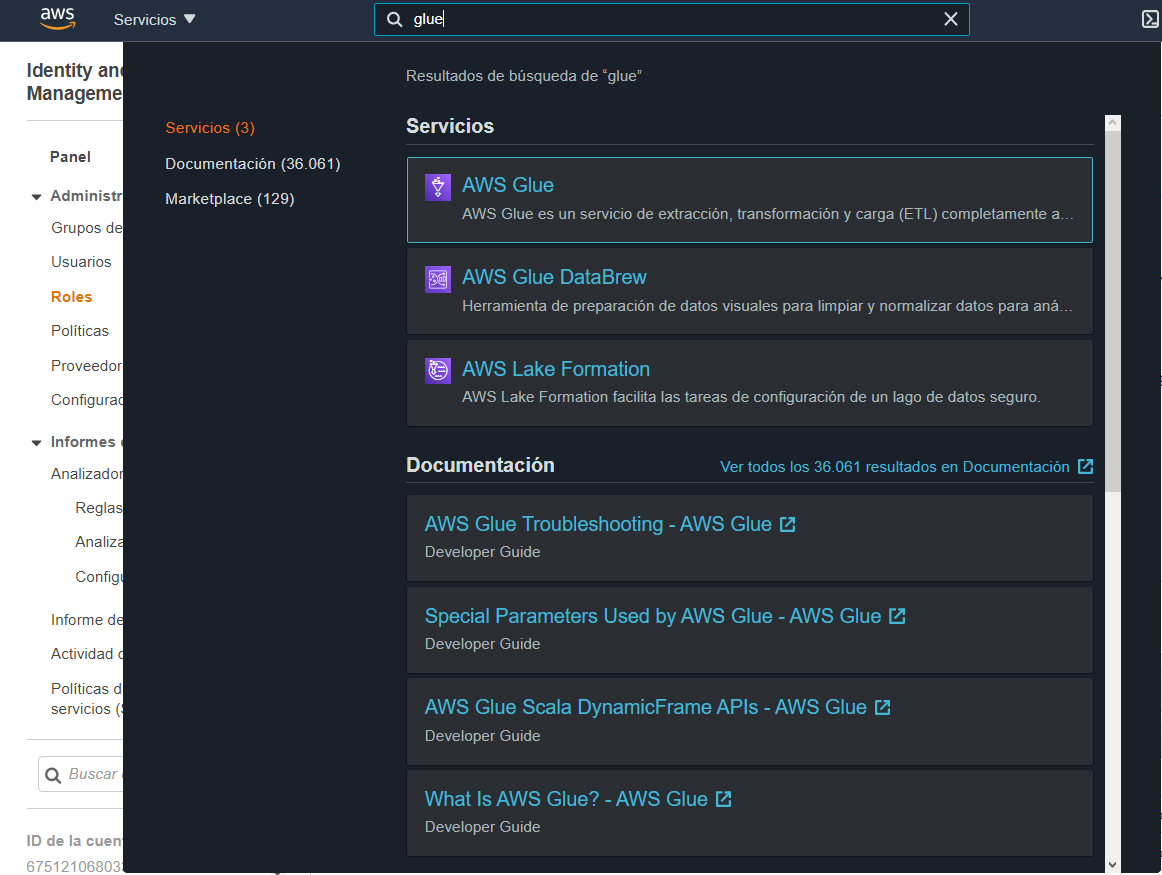
Una vez se encuentre en el panel de AWS Glue, diríjase a la opción Bases de datos en el panel izquierdo de la pantalla.
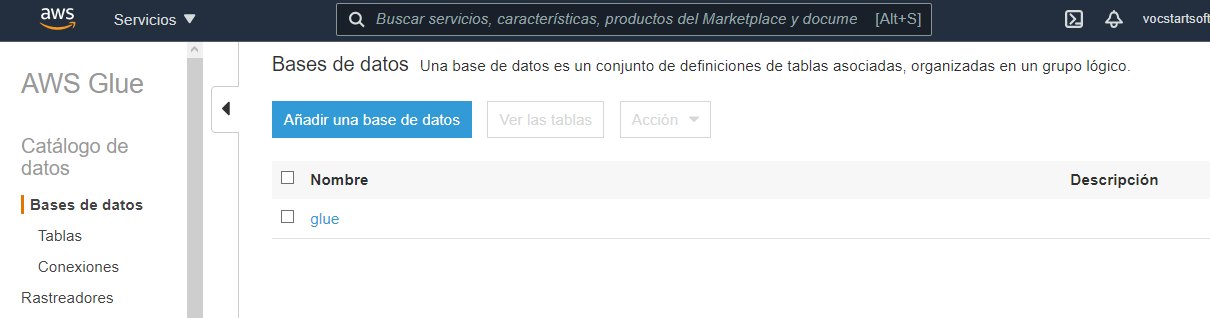
Ahora, cree una nueva base de datos, ingresando el nombre de su preferencia. Esta base de datos guardará los esquemas de los datos crudos que se subieron a AWS S3 en el bucket wideworldimports.
Una vez realizado esto, diríjase a la sección Rastreadores, que se encuentra en la sección izquierda de la pantalla. Un rastreador o crawler, sirve para leer nuestros datos crudos y, de esta forma, inferir el esquema de los mismos.

Proceda a crear un rastreador haciendo clic en la opción Añadir rastreador, seleccione el nombre que quiera para el rastreador, y haga clic en Siguiente.
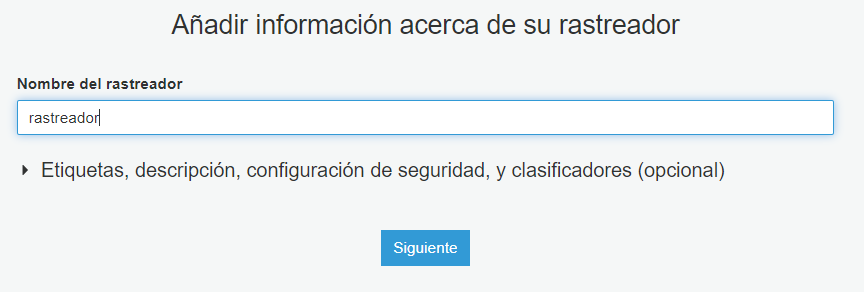
A continuación, en la configuración Crawler source type seleccione Data stores y en Repeat crawls of S3 data stores seleccione Crawl all folders. Tras seleccionar estas opciones, haga clic en Siguiente.
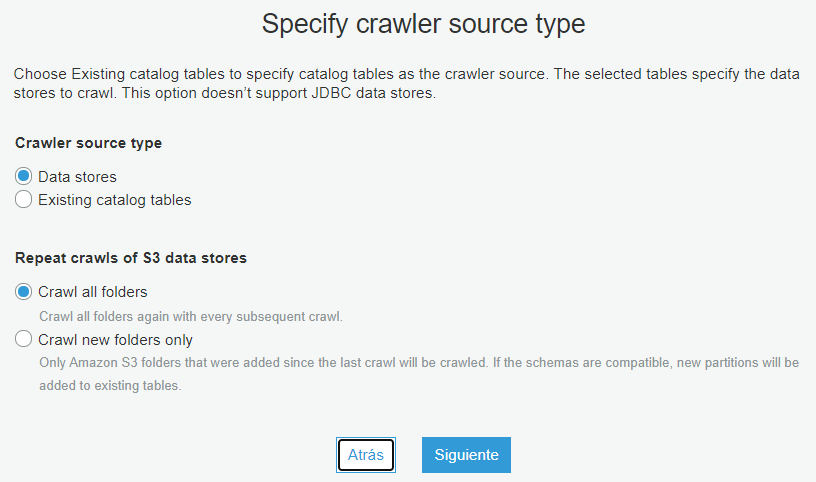
Ahora, debe configurar la fuente de datos. En la opción Elija un almacén de datos seleccione S3, deje el campo Conexión vacío, en la opción Rastree datos en seleccione Ruta especificada en mi cuenta.
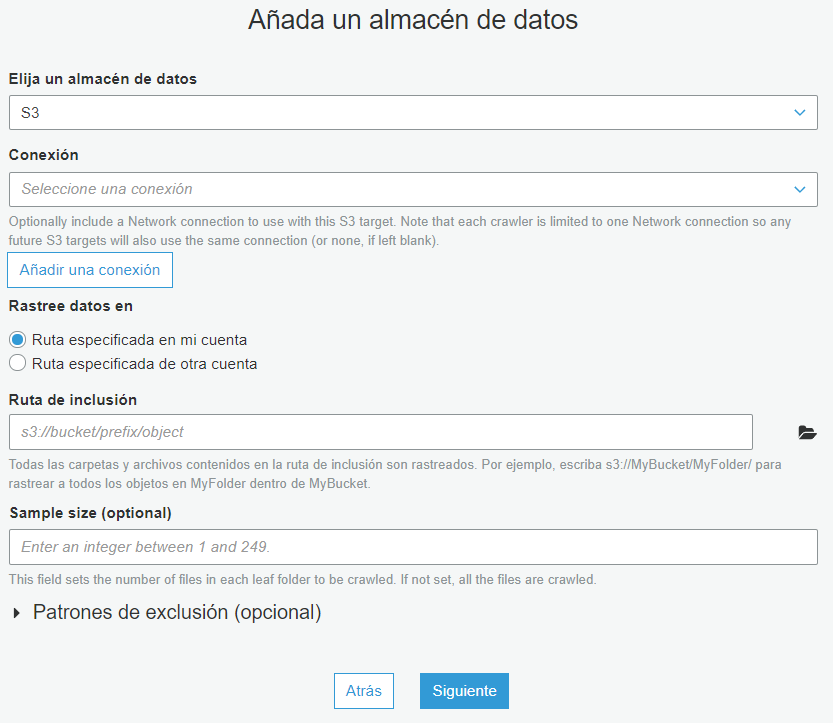
Ahora, para seleccionar el bucket de S3 correcto, haga clic sobre la carpeta que puede ver al lado derecho de la opción Ruta de inclusión. Esto despliega una lista de todos sus buckets en AWS S3. Aquí, debe seleccionar el bucket wideworldimports en donde almacenó los archivos csv previamente
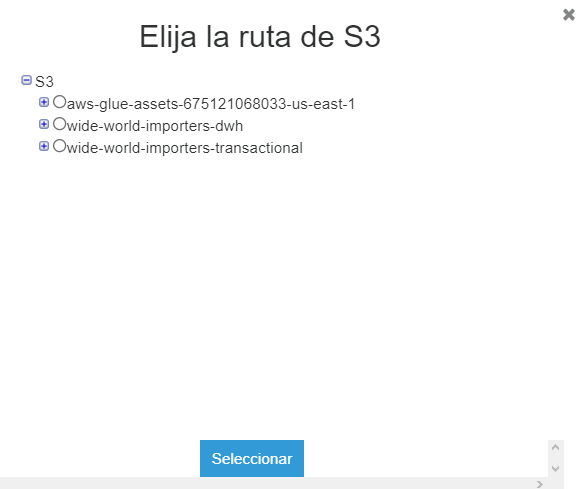
Haga clic en Seleccionar. A continuación, en la pregunta de si quiere añadir otra fuente de datos. Seleccione No, y haga clic en Next.

A continuación, debe ingresar el rol IAM que para el rastreador. Este no debe ser el mismo rol IAM que creó anteriormente. Seleccione la opción Create an IAM role y nombre al rol como quiera.
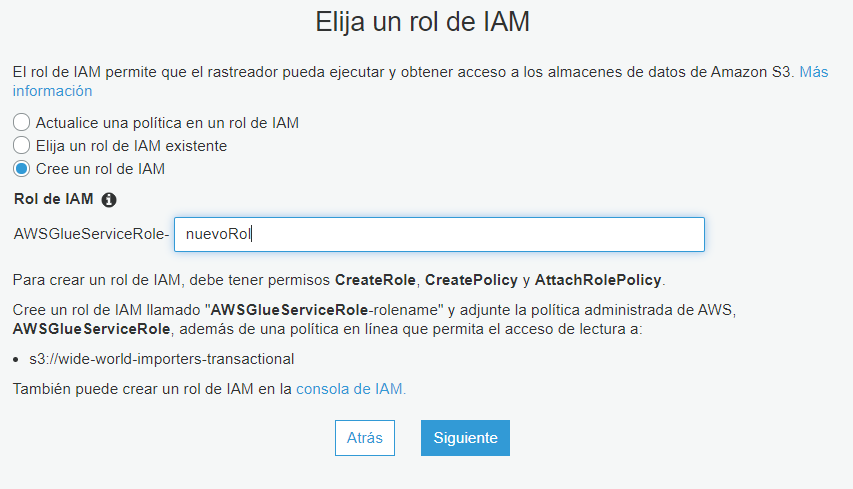
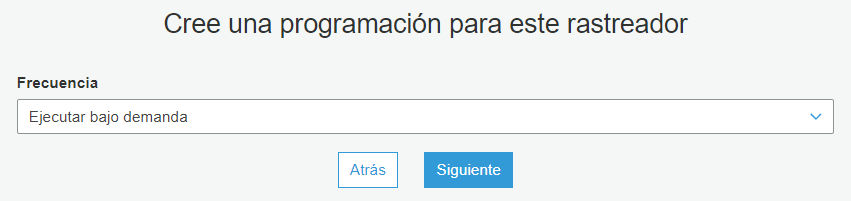
Ahora debe seleccionar la frecuencia con la que quiere ejecutar el rastreador. Seleccione la opción Ejecutar bajo demanda y haga clic en Siguiente.
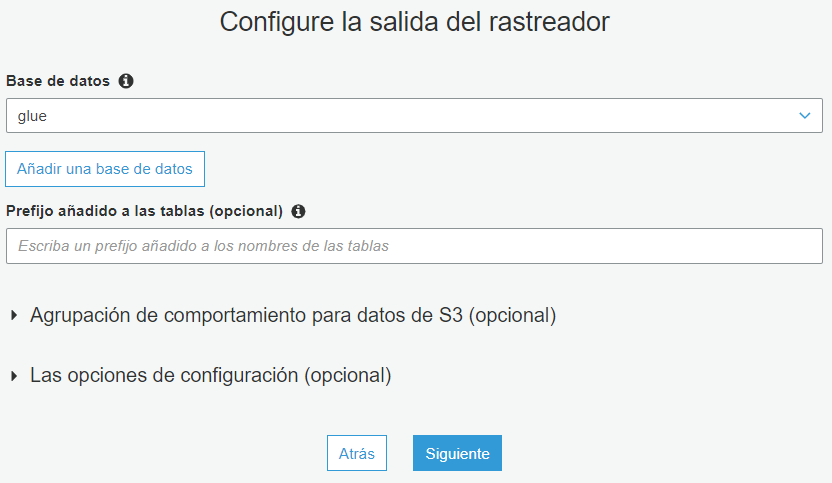
La salida del rastreador debe guardarse en una base de datos. Es decir, las tablas y los esquemas que el rastraeador decte. Seleccione la base de datos de Glue que creó anteriormente y haga clic en Siguiente.
Finalmente, revise que la información es correcta en el resumen y haga clic en finish.
Una vez creado el rastreador, selecciónelo en la lista de rastreadores y haga clic en Ejecutar rastreador. Ahora diríjase a bases de datos haga clic en su base de datos y luego en Tablas en <nombre de su base de datos>. Ahí, puede ver los esquemas de todos los csv que subió previamente a AWS S3.
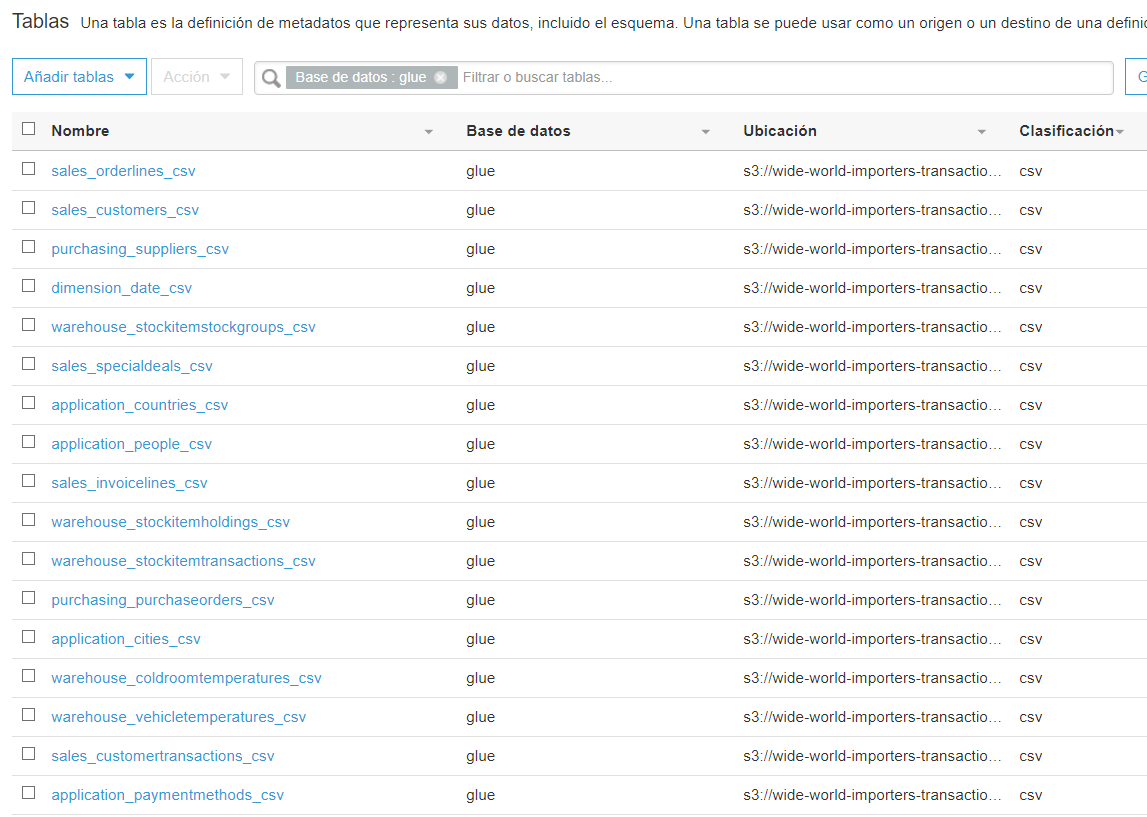
Si lo desea, explore un poco las tablas para entender la estructura y atributos de los datos. A pesar de que la estructura inferida suele ser muy confiable, existe la posibilidad de una equivocación. En este caso en particular, por ejemplo, el rastreador suele equivocarse en el tipo de atributo pickedbypersonid de la tabla sales_orders_csv.
Para arreglar esto último, diríjase a la tabla sales_orders_csv y verifique que el tipo del atributo pickedbypersonid sea string. Si este no es el caso, haga clic en el botón Editar la tabla, que aparece en la parte superior derecha de la pantalla.
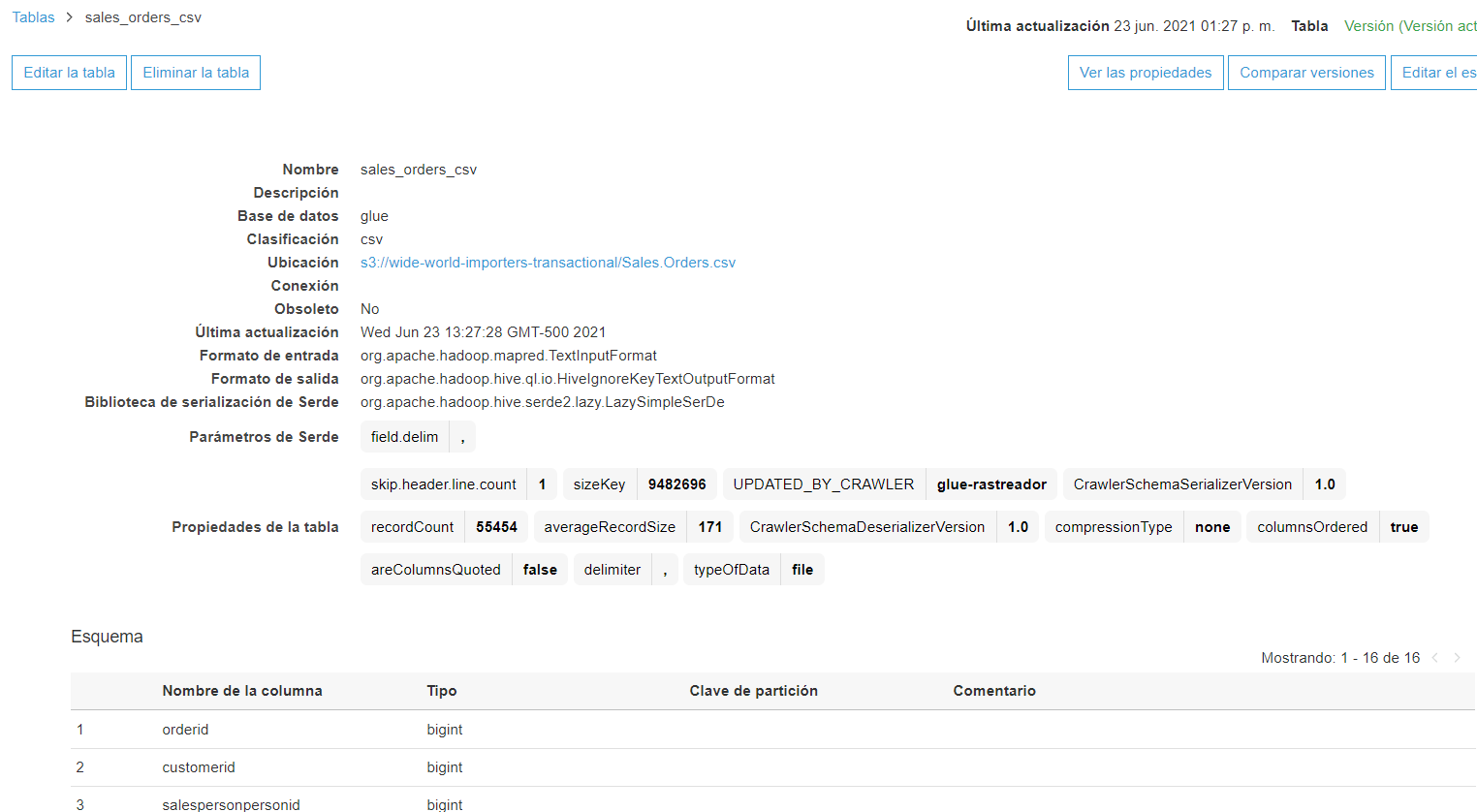
Tras hacer clic en Editar la tabla seleccione el tipo correcto para el atributo y guarde sus cambios.
Una vez terminada la configuración, ya puede comenzar a trabajar en el ETL. Para hacer esto, diríjase a AWS Glue Studio, en la parte izquierda de la pantalla de AWS Glue. Una vez haya abierto AWS Glue Studio, seleccione la opción Create and manage jobs.
Para crear un nuevo job puede hacer clic sobre la opción Create.
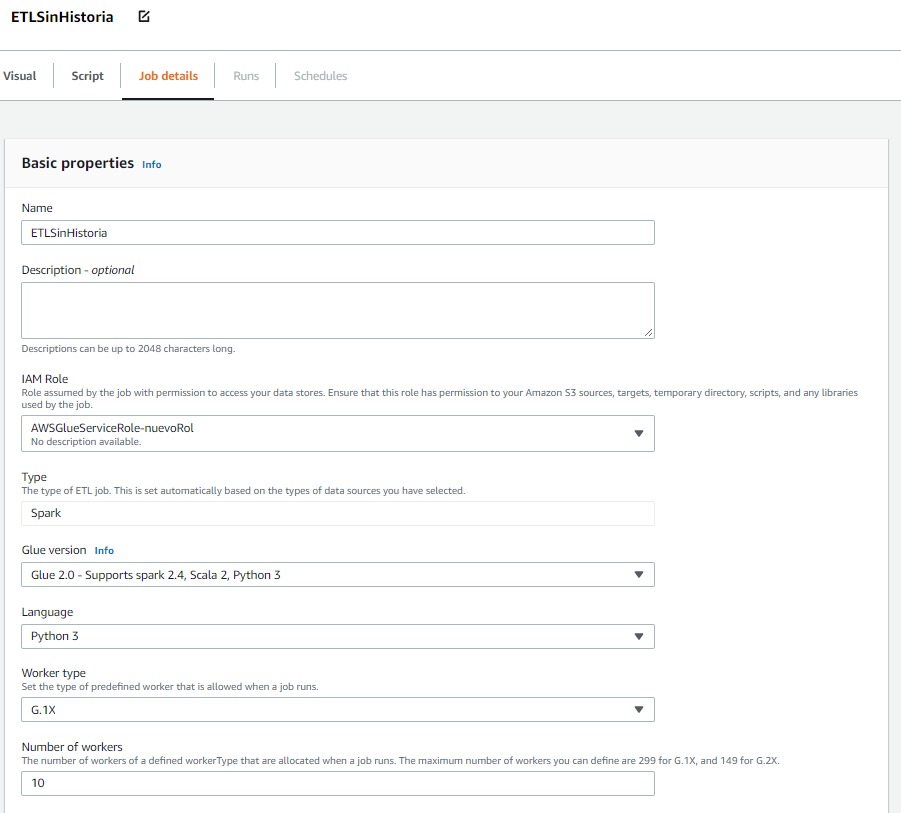
Esto abre un editor en el que podrá crear sus ETL creando y conectando nodos. En la pestaña Job details, puede editar la descripción, el rol IAM y otros detalles técnicos. Es necesario que seleccione el rol IAM que creó anteriormente.
AWS Glue cuenta con tres tipos de nodos: Data source, Data target y transform. Los nodos de tipo Data source sirven para leer información de una base de datos registrada en Glue. Los nodos tipo Data target sirven para escribir la información de Glue, sea en una base de datos de registrada en Glue o directamente en AWS S3. Finalmente, los nodos Transform son los que aplican las transformaciones en si.
Algunas de las transformaciones disponibles son:
- ApplyMapping: Permite renombrar y eliminar columnas.
- SelectFields: Permite seleccionar las columnas que se quieren mantener y descarta las demás columnas.
- DropFields: Permite eliminar columnas.
- RenameField: Permite cambiar el nombre de una columna.
- Spigot: Permite hacer muestreo de los datos y escribir la muestra en un bucket de AWS S3.
- Join: Permite unir dos tablas.
- Filter: Permite filtrar una tabla.
- Custom Transform: Permite hacer una transformación personalizada programando una función de Python.
1. Construcción de un ETL para WideWorldImporters
Ahora, se presenta un ejemplo de un ETL completo desarrollado en AWS Glue. Suponga que WideWorldImporters requiere de un proceso ETL que le permita extraer los datos de órdenes desde unos archivos CSV y los almacene en un modelo dimensional tal que, les permita realizar análisis OLAP. A continuación, se presenta el modelo multidimensional que se desea obtener:
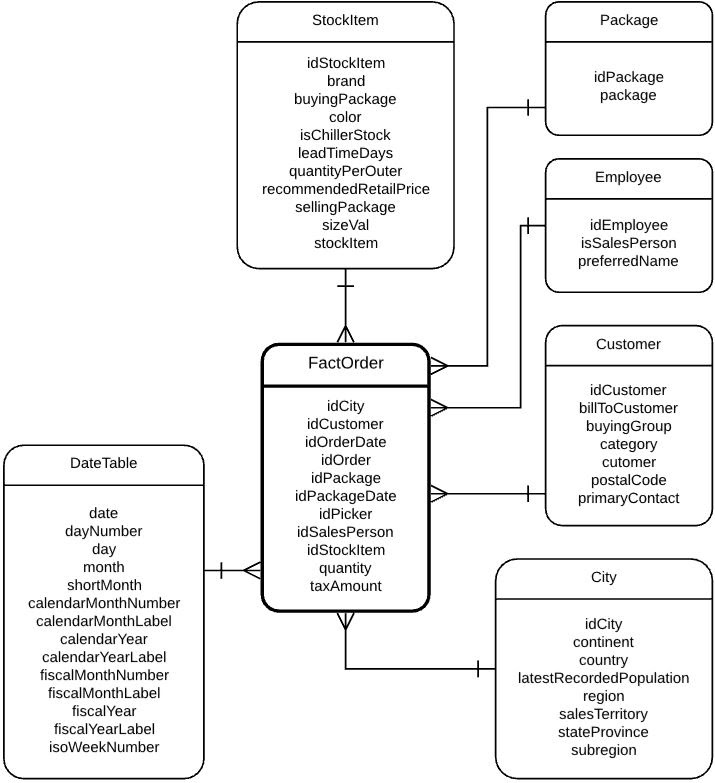
En el script adjunto, encuentra el código que limpia los datos crudos para poblar la fact table y todas las dimensiones de este modelo, con la única excepción de la dimensión customer.
Si quiere explorar el script, cree un nuevo job vacío en AWS Glue Studio, tras esto, vuelva a la pantalla de AWS Glue, vaya a la sección jobs, seleccione el job que acaba de crear y haga clic en Actions seguido de edit script.

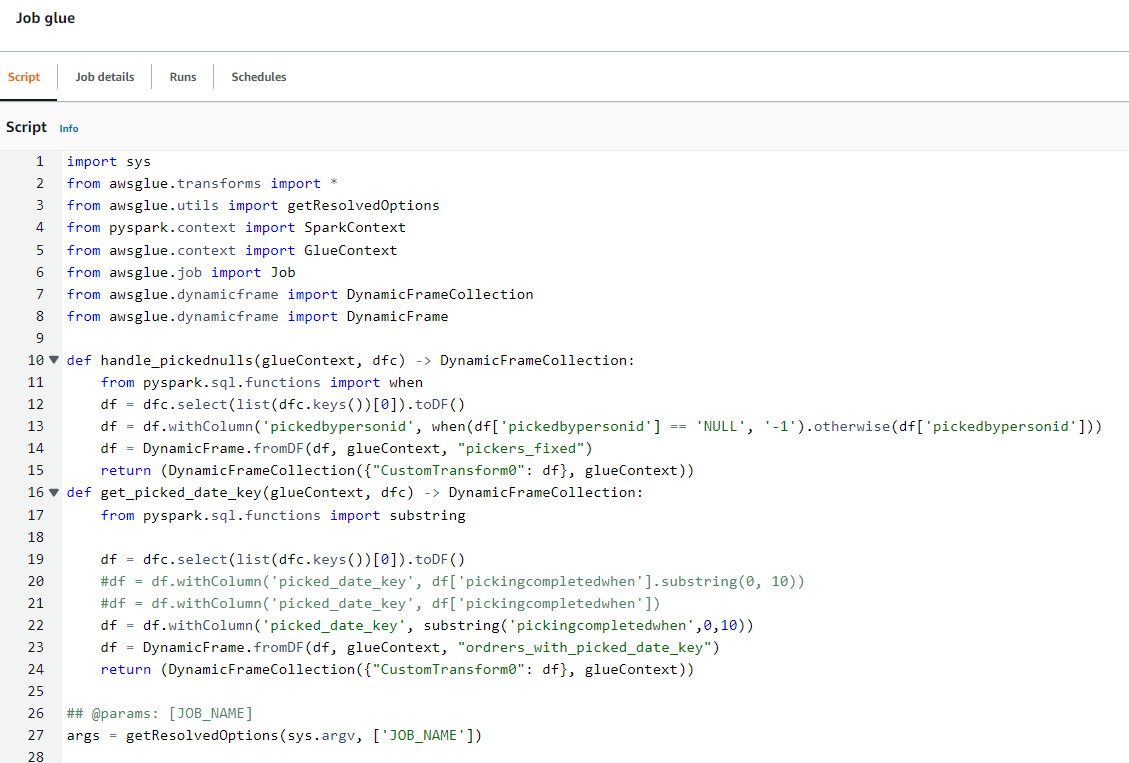
Finalmente, pegue el script en la pantalla resultante. Si lo desea, puede ejecutar este job, pero debe asegurarse de cambiar los sources del mismo por la base de datos de AWS Glue que contiene los esquemas de los datos crudos y los targets por las carpetas de su bucket de S3 correspondiente a los datos limpios (worldwideimportersdw). Para hacer esto, revise que todas las funciones glueContext.create_dynamic_frame.from_catalog tengan la base de datos y tabla apropiada y que todas las funciones glueContext.write_dynamic_frame.from_options apunten a la dirección correcta en S3.
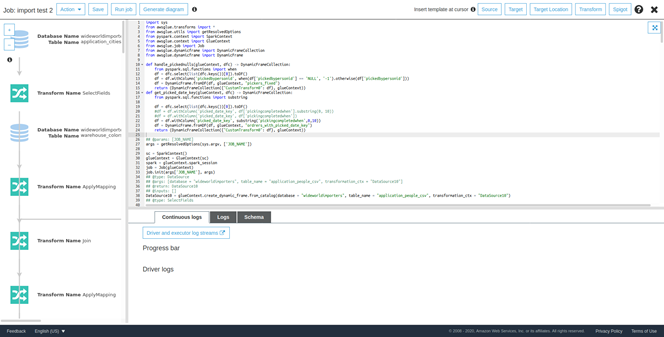
Desafortunadamente, en este momento no es posible importar scripts a AWS Glue Studio, por lo que no se puede explorar el script usando esta opción.
Ahora, se explica el proceso que se utiliza para limpiar los datos de la dimensión employee.
El proceso inicia leyendo los datos crudos de los empleados. Para esto, se utiliza un nodo S3 de tipo Source.
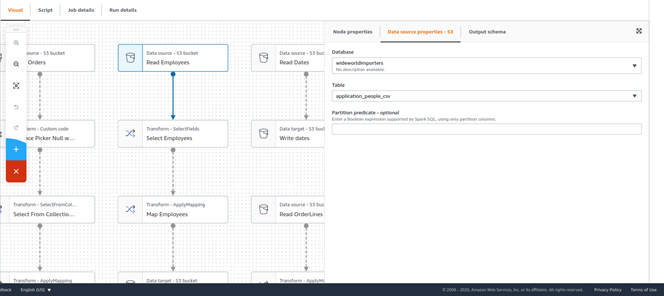
La tabla que se lee contiene más campos de los que exige el modelo multidimensional, por lo tanto, ahora se utiliza un nodo Select de tipo Transform para seleccionar únicamente las columnas relevantes.
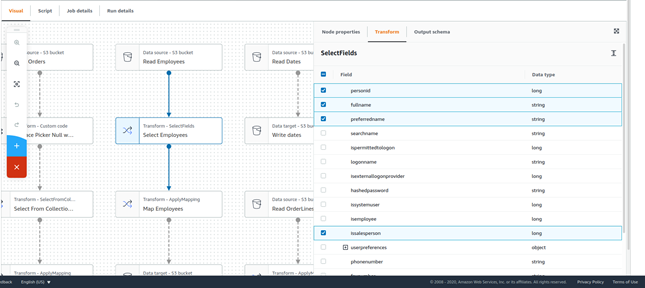
Tras esto, se utiliza una transformación ApplyMapping para renombrar las columnas restantes de modo que concuerden con el modelo multidimensional.
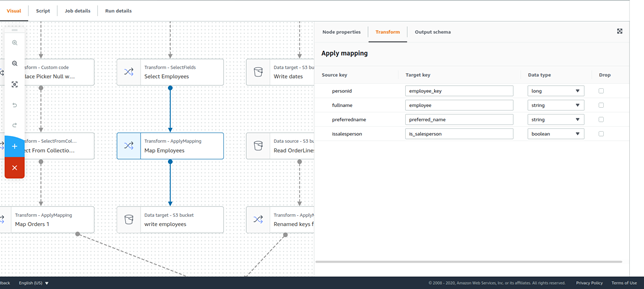
Finalmente, se escribe la tabla resultante en S3 usando un nodo S3 de tipo Target.
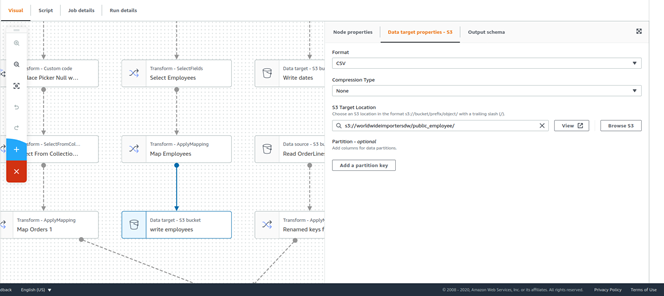
Ahora, desarrolle un ETL que utilice la tabla cruda de customers para poblar la dimensión customer del modelo multidimensional. Para esto, es necesario usar transformaciones como Select y ApplyMapping, además de esto, tendrá que hacer join con las tablas sales_buyinggroups y sales_customercategories.
Al completar este tutorial ya sabe cómo configurar y realizar ETL básicos en AWS Glue. Ya conoce cómo puede utilizar AWS S3 como almacén de datos para AWS Glue, y conoce las funcionalidades que ofrece esta herramienta.
Si quiere conocer más sobre AWS Glue, puede consultar la documentación oficial enhttps://docs.aws.amazon.com/glue/index.html
I. El ETL se ejecuta correctamente, pero los resultados no se escriben en S3.
Verifique que el rol IAM se haya configurado correctamente, y que esté ejecutando el ETL con este rol.