La fecha límite de entrega del proyecto es el 7 de febrero de 2021 a las 11:59 PM Hora Colombia (GMT-5).
Siga las instrucciones a continuación para crear los entregables que serán calificados en el proceso de evaluación.
Para cumplir con las actividades del proyecto es necesario que cuente con ciertas herramientas instaladas en su máquina personal.
- Postman (https://www.postman.com/)
- Git (https://git-scm.com/). No olvide configurar su usuario de git para que las entregas estén marcadas con este.
- Python 3.9 (https://www.python.org/)
- IDE de su elección. Puede definirlo con su equipo de trabajo.
- JMeter (https://jmeter.apache.org/)
Se ha decidido realizar un proceso de migración a la nube desde la solución on-premises de la compañía. Para tal propósito el arquitecto en jefe decidió hacer una migración por etapas: inicialmente se va a desplegar la solución actual en contenedores y en etapas posteriores se van a realizar desarrollos de nuevos requerimientos usando una nueva arquitectura completamente nativa en la nube.
Para hacer una proyección de costos se deben realizar ejercicios de capacidad y escalabilidad sobre el nuevo modelo de despliegue a utilizar. Se les ha encomendado la misión de realizar un despliegue del monolito con el que cuenta la compañía en contenedores mediante kubernetes y realizar este análisis de costos para poder presentar un informe a los gerentes de la compañía.
En esta entrega del proyecto usted deberá:
- Desplegar la base de datos relacional de la compañía en un servicio autogestionado de base de datos en la nube.
- Realizar un despliegue del monolito en contenedores haciendo uso de kubernetes para el despliegue y el aseguramiento de la escalabilidad de la aplicación.
- Realizar pruebas de capacidad y escalabilidad sobre la infraestructura desplegada.
- Realizar un informe de capacidad y costos asociados a la nueva plataforma. Este informe debe estar sustentado en el tráfico actualmente recibido por la plataforma de la compañía y las proyecciones de crecimiento de esta.
A continuación, se detallan estos pasos y se le otorgan los datos necesarios para completar el proyecto.
El monolito (o La Roca como lo conocen en el equipo de TI) está desarrollado sobre el framework Flask haciendo uso de Python 3.9. Actualmente el código está almacenado en un repositorio Git que se utiliza en los procesos de desarrollo y despliegue on-premises.
Actualmente el monolito expone los siguientes servicios:
- Login (login): dado un usuario y contraseña hace la validación de estos y retorna un token de sesión en caso de que la validación sea exitosa.
- Sesión (sessions): dado un token de sesión da información básica del usuario si este es válido.
- Productos página principal (landing-products): Retorna los productos que deben ser mostrados al usuario en la página principal del sitio.
- Consulta de producto (get-product): Dado un id de producto, retorna los detalles de este.
- Búsqueda productos (search-products): Dadas unas palabras claves retorna una lista de productos resultado para ser mostrados al usuario. Estos productos incluyen el detalle básico para ser mostrados.
Estos servicios deberán ser utilizados en el análisis de capacidad y proyección de costos.
El tráfico actual que reciben estos servicios se puede ver en la siguiente tabla:
Servicio | Min RPM | Max RPM |
login | 10 (0,06%) | 1000 (0,20%) |
sessions | 10000 (63,05%) | 300000 (61,10%) |
landing-products | 5000 (31,53%) | 60000 (12,22%) |
get-product | 800 (5,04%) | 120000 (24,44%) |
search-products | 50 (0,32%) | 10000 (2,04%) |
La distribución de tráfico de todos los microservicios se resume de la siguiente manera:
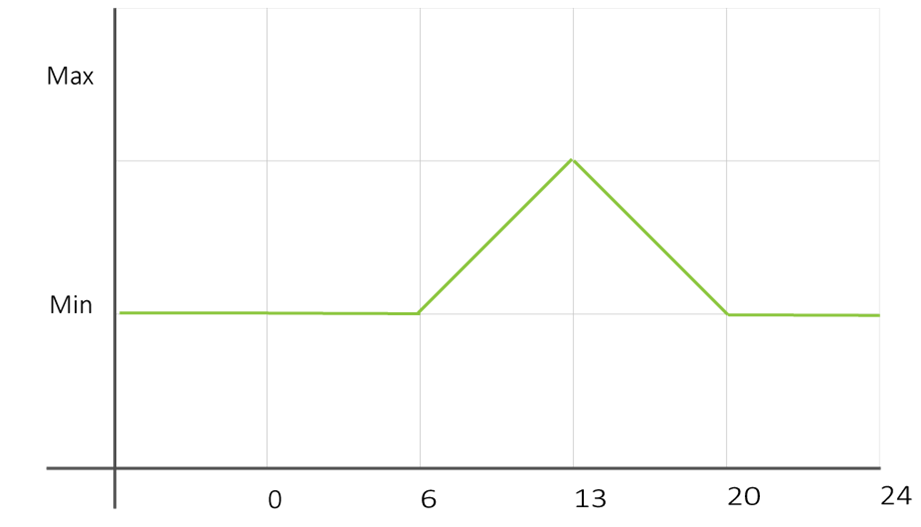
- 00:00 hasta 06:00 -> Tráfico estable entre [Min-RPM, 1.05 Min-RPM].
- 06:00 hasta 13:00 -> Tráfico linealmente creciente desde Min-RPM al inicio hasta Max-RPM con incrementos esporádicos del 5%.
- 13:00 hasta 20:00 -> Tráfico linealmente decreciente desde Max-RPM al inicio hasta Min-RPM al final con incrementos esporádicos del 5%.
- 20:00 hasta 24:00 -> Tráfico estable entre [Min-RPM, 1.05 Min-RPM].
El tráfico puede verse en una gráfica como la siguiente
La compañía proyecta duplicar el tráfico de la plataforma cada 300 días. El crecimiento del tráfico se comporta según la ecuación
T(t)=2^(t/(300 día))×T_origen
donde T(t) es el tráfico proyectado en el día t de operación y T_origen es el tráfico en el día inicial de la proyección.
Ejecute las actividades hasta el Entregable II durante la primera semana del curso
Ambiente: Local
Como primer paso, vamos a desplegar el monolito localmente contra una base de datos SQLite. Para lograrlo debe clonar el repositorio que contiene el monolito. Le recomendamos leer el documento README del proyecto para tener claridad de su configuración y funcionamiento.
En el GitHub del curso, debe encontrar un repositorio con el siguiente nombre
s202210-proyecto-entrega1-grupoX
El cual contiene el monolito y los archivos requeridos para el desarrollo del proyecto en su primera entrega. Debe clonar localmente el repositorio y asegurarse de que utiliza la rama entrega1 para todos los cambios que debe hacer en el proyecto.
Seguidamente instale las dependencias mediante el comando
pip install -r ./requirements.txt
Finalmente, ejecute el proyecto
python app.py
Con el servidor ejecutando utilice el archivo de postman ubicado en postman/tests.postman_collection.json para hacer pruebas sobre los servicios.
Ambiente: Nube GCP
La compañía decidió utilizar una base de datos PostgreSQL con redundancia en múltiples nodos para soportar el tráfico. El equipo de administradores de bases de datos (DBAs) se ha encargado de preparar un script para la carga de un corte de información contenido en estas bases de datos y así poder realizar el análisis de capacidad y costos del monolito.
Los DBAs se tomaron el trabajo de hacer ejercicios para la migración de las bases de datos a la nube, razón por la cual puede partir del supuesto que el script entregado ya se encuentra optimizado para funcionar adecuadamente en el servicio que se va a utilizar. Además, el equipo de DBAs ya preparó un informe de costos relacionados con el almacenamiento y consulta de información, de manera que su tarea será enfocarse exclusivamente en los costos de los servicios utilizados por el monolito en su despliegue.
Configuración para el despliegue
Debe realizar un despliegue de Cloud SQL con las siguientes características. Utilice el tutorial de SQL disponible en la semana 1 del curso.
- Motor: PostgreSQL 14
- Región: us-central1 (Iowa)
- Disponibilidad zonal: Zona única
- Tipo de máquina: Núcleo compartido con 1.7 GB de RAM
- Almacenamiento SSD de 40 GB
- NO Habilitar los aumentos de almacenamiento automáticos
- IP pública no habilitada
- Sin copias de seguridad automática
Restauración backup
En el siguiente bucket encuentra el backup de postgres para restaurar la información de la base de datos para las pruebas de rendimiento.
gs://misw-4301-compartido/proyecto/semana-1/backup.sql
Para evitar la descarga y subida de la base de datos, se recomienda utilizar la herramienta de importación de datos en la consola de GCP. Vaya a la instancia de base de datos y de click en Importar:
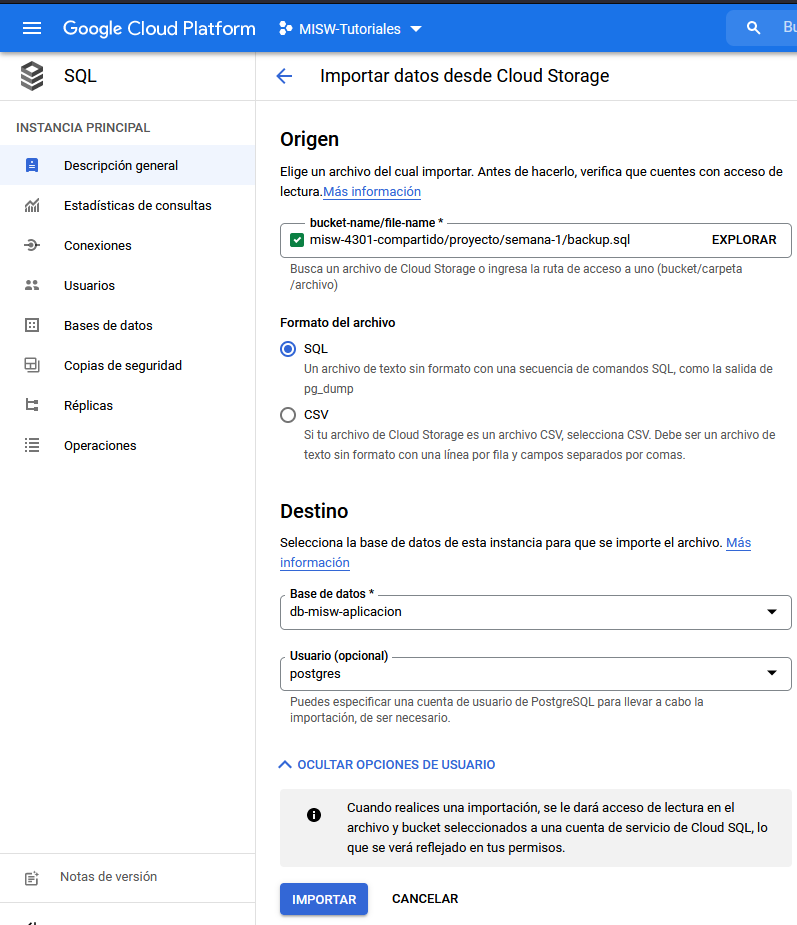
Una vez en el formulario de importación, llene las opciones con los siguientes datos:
- bucker-name/file-name:
misw-4301-compartido/proyecto/semana-1/backup.sql - Formato del archivo: SQL
- Destino - Base de datos: db-misw-aplicacion
- Usuario: postgres
El proceso toma alrededor de 30 minutos. Una vez terminado, la base de datos seleccionada contará con 4 tablas con las siguientes cantidades de registros:
Tabla | Registros |
palabra | 2451176 |
producto | 13791646 |
sesion | 3901101 |
usuario | 9990001 |
15 puntos
Debe entregar un documento de análisis que contenga las siguientes secciones:
1. Análisis del monolito
Debe presentar un análisis del monolito que incluya los siguientes elementos:
- Describa cada servicio de la aplicación.
- Catalogue el uso de recursos y liste las consideraciones de escalabilidad relacionadas con cada servicio.
2. Análisis de proyección de capacidad
Una sección en la que especifique claramente cómo va a realizar el cálculo de la capacidad requerida, en particular debe definirlo para una ventana de tiempo de una hora en la que conoce las condiciones del sistema. En particular, debe determinar cómo para una tupla de valores que represente las solicitudes máximas esperadas para cada servicio en un instante dado de tiempo, va a calcular la cantidad de pods/nodos requeridos por su modelo de despliegue para atender dicha demanda.
Debe incluir dos modelos para realizar el cálculo y definir cuál va a ser el utilizado en la proyección de capacidad que se entregará por su parte en este proyecto.
Evaluación
Los siguientes criterios se tendrán en cuenta en el proceso de evaluación y validación de este entregable:
- [5 puntos] Análisis del monolito: Se evaluará que las consideraciones de escalabilidad identificadas para cada servicio sean adecuadas y correspondan al comportamiento real del mismo.
- [10 puntos] Análisis de proyección de capacidad: Se evaluará que hayan dos modelos de cálculo de capacidad, que se haga una comparación entre estos y que se indique el racional para decidir optar por alguno de los dos. El racional debe ser correcto y estar bien justificado. Ambos modelos deben ser claros. No puede usar el modelo de ejemplo.
El objetivo de estas pruebas es determinar la cantidad máxima de solicitudes por minuto (RPMs) que alcanza un contenedor/nodo con el monolito desplegado y determinar el comportamiento del sistema para trazar las configuraciones de escalabilidad que se deben aplicar en producción y por lo tanto en la proyección de capacidad.
Para efectos de las pruebas de capacidad, el equipo de producto definió que es aceptable que el tiempo de respuesta del api del sistema sea de hasta 300 ms. Más allá de este tiempo de respuesta, se considera que hay afectación del servicio. En caso de que durante una prueba se generen más de un 1% de errores en las solicitudes de la prueba, se concluye que la aplicación NO soporta la cantidad de solicitudes de la prueba.
Objetivos
- Diseñar escenarios de prueba que permitan medir la capacidad máxima que pueden soportar algunos componentes del sistema. El resultado debe expresarse en el documento del plan de análisis de capacidad con el que se simula el acceso, la carga, el estrés y la utilización de la aplicación.
- Ejecutar las pruebas de estrés que permitan dimensionar la capacidad de una aplicación y su infraestructura de soporte con base al plan de pruebas.
Análisis de capacidad
Apache JMeter es una aplicación de código abierto desarrollada en Java. JMeter es una herramienta diseñada para realizar pruebas de estrés de aplicaciones Web HTTP. Es importante resaltar que JMeter no es un navegador web, es una herramienta que simula las peticiones a nivel del protocolo HTTP, por esta razón no compila el código embebido. JMeter facilita simular la carga de cientos de usuarios de una aplicación web.
Las pruebas de estrés evalúan: capacidad de procesamiento, tiempos de respuesta, y utilización. Estas tres métricas son indispensables para diseñar pruebas de estrés efectivas.
- Capacidad de Procesamiento (Throughput): la cantidad de trabajo realizado en un periodo definido de tiempo (Ejemplo: transacciones por minuto). En JMeter, el listener Summary Report reporta el throughput promedio para la totalidad de las transacciones y para cada una individualmente.
- Tiempo de Respuesta (Response Time): tiempo que transcurre desde que el usuario envía una transacción hasta que recibe la respuesta completa. En JMeter, el listener Summary Report reporta el Response Time promedio para la totalidad de las transacciones y para cada una individualmente.
- Utilización (Utilization): porcentaje que representa qué tan ocupado está un recurso (CPU, Mem, I/O, etc) en un momento específico. JMeter no reporta esta métrica; es necesario instalar el plugin Performance Monitoring pero se recomienda utilizar un Application Performance Management (APM) independiente.
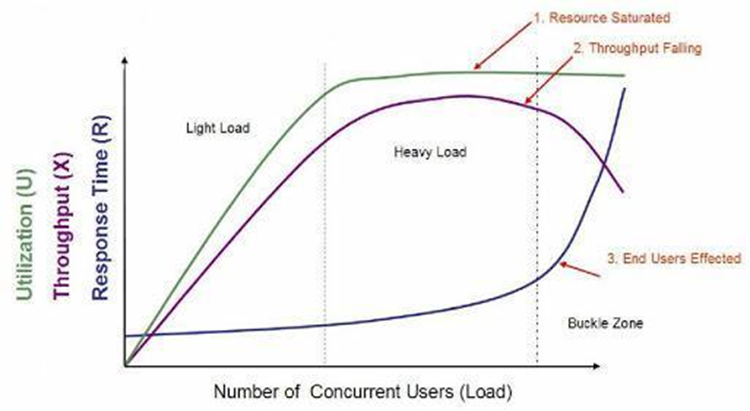
Ilustración: Ejemplo, comportamiento de las métricas en un escenario de estrés.
Para todas las entregas del proyecto usted deberá realizar pruebas de estrés, con el objetivo de comprender cómo la aplicación web y su infraestructura responden a varios niveles de carga de usuarios. Con estas pruebas se desea medir la capacidad de procesamiento, el tiempo de respuesta y utilización, mientras se simula la concurrencia de usuarios en la aplicación y cargas de trabajo artificiales.
Las pruebas de estrés deberán responder a interrogantes como: ¿la aplicación responde rápidamente? ¿Cuál es el volumen de usuarios puede manejar la aplicación con la infraestructura que actualmente la soporta?
En la ilustración puede analizar el comportamiento de las tres métricas mencionadas en función de la carga artificial creada (simulación de usuarios). Los incrementos en la carga impactan la capacidad de procesamiento, el tiempo de respuesta y utilización. Inicialmente, la relación tiende a ser lineal con baja carga; a medida que la carga aumenta hacen que el comportamiento de las métricas sea no-lineal.
Este ejemplo ilustra la saturación de una CPU cuando el número de procesos supera la capacidad de la CPU. El tiempo de respuesta aumentará a razón del número de procesos en cola, y como consecuencia, genera que la capacidad de procesamiento disminuya y se afecte la experiencia de un usuario.
25 puntos
Teniendo en cuenta la sección anterior, se deben definir escenarios de prueba para responder a los objetivos del proyecto. En particular el plan de pruebas definido por usted debe cumplir con los siguientes objetivos:
- Determinar cúal es la cantidad máxima de solicitudes (RPMs) que puede soportar un pod/nodo sin producir degradación del servicio.
- Establecer la línea base con la que se estimará la cantidad de pods/nodos desplegados según su Análisis de proyección de capacidad del Entregable I.
Teniendo en cuenta la sección anterior, es necesario diseñar una carga efectiva (estrés) e interpretar los resultados correctamente, para esto responda las siguientes preguntas orientadoras:
- [3 puntos] ¿Cuál es el objetivo de las pruebas de capacidad? Determine las preguntas a las que espera responder con los resultados. Establezca cuales son las condiciones necesarias en los escenarios según cada objetivo. Determine la variabilidad entre servicios representativos y cómo simular esa variabilidad, definir datos de prueba y establecer qué métricas se deben recopilar.
- [3 puntos] ¿Cuál es su entorno de prueba? Identifique las características y limitaciones de la infraestructura donde se despliegue su aplicación en producción, así como las características de las herramientas que soportan su aplicación. Es necesario identificar estos aspectos para el equipo de prueba. El entorno físico incluye configuraciones de hardware, software y red. Tener un conocimiento profundo de todo el entorno de pruebas desde el principio permite un diseño y una planificación de pruebas más eficientes y le ayuda a identificar los desafíos de las pruebas al principio del proyecto.
- [4 puntos] ¿Cuáles son los criterios de aceptación? Identifique los objetivos y limitaciones de tiempo de respuesta, rendimiento y utilización de recursos. El tiempo de respuesta es una preocupación del usuario, el rendimiento es una preocupación comercial y la utilización de recursos es una preocupación del sistema. Además, identifique los criterios de éxito del proyecto que pueden no ser capturados por esos objetivos y limitaciones; por ejemplo, utilizando pruebas de rendimiento para evaluar qué combinación de ajustes de configuración dará como resultado las características de rendimiento más deseables. Valide la información en base a sus escenarios de prueba.
- [15 puntos] (Corregido de 18 a 15 por un error en el establecimiento de los puntos) ¿Cuáles son los escenarios de prueba? Identificar escenarios con base a los objetivos planteados. Consolide esta información en uno o más modelos de uso del sistema para implementar, ejecutar y analizar. Debe definir un conjunto de escenarios basado en su propuesta de modelo para la proyección de capacidad definida en el entregable 1. Para hacer pruebas de estrés se debe utilizar la herramienta JMeter que podrá instalar en un entorno local.
Evaluación
Ejecute las actividades hasta el Entregable V durante la primera semana del curso
Ambiente: Nube GCP
Cree el archivo Dockerfile que permita desplegar la aplicación, siguiendo las instrucciones de los tutoriales de Docker, y ubíquelo dentro del repositorio del proyecto.
Utilice el tutorial de Artifact-Registry para crear la imagen del monolito que va a desplegar y depositarla en un registro de contenedores para el equipo. Utilice el nombre proyecto-entrega1-monolito para la imagen.
Una vez creada, despliegue la imagen localmente utilizando el comando:
docker run -p 3000:3000 <imagen>
Una vez desplegada la imagen, realice pruebas con el archivo de postman.
Ambiente: Nube GCP
Objetivos
- Realizar un modelo de despliegue de una aplicación usando contenedores.
- Realizar el despliegue del monolito mediante un orquestador de contenedores.
- Conectar un contenedor con una base de datos SQL autogestionada.
Enunciado
Para esta parte del proyecto usted debe tomar el monolito de la compañía y desplegarlo haciendo uso de un orquestador de contenedores. Siga cada uno de los pasos de las siguientes secciones.
Preparación
Mediante el tutorial de creación de proyectos en GCP, cree un proyecto para albergar el proyecto del curso. Llame a este proyecto misw-ann-proyecto.
Despliegue
Con la imagen registrada en el Artifact Registry es momento de crear el archivo de configuración (archivo .yml) para desplegar el clúster en Kubernetes.
Debe crear un archivo de configuración: config-test.yaml que se utilizará sólamente para la ejecución del plan de pruebas para determinar la carga máxima que soporta el monolito según los escenarios que ustedes hayan definido en el entregable I.
Para probar la aplicación puede realizar despliegues de prueba en GKE. Sin embargo, tenga la precaución de detenerlos cuando termine la prueba de manera que no consuma recursos innecesarios de su bono de GCP.
7 puntos
Con el despliegue en k8s funcionando, debe realizar un video en el que sustente lo siguiente:
- En la consola de GCP el artifact registry para la imagen del monolito
- En la consola de GCP el cluster en GKE
- Los servicios desplegados con sus pods
- La dirección IP de entrada del cluster
- La prueba de los servicios expuestos por el monolito mediante postman, asegurándose de utilizar la IP pública de su cluster. No olvide describir los resultados obtenidos, los cuales serán los descritos en las entregas anteriores.
El video no debe tener una duración superior a los 20 minutos.
Evaluación
Los siguientes criterios se tendrán en cuenta en el proceso de evaluación y validación de este entregable:
- [4 puntos] Componentes desplegados: En el video se evidencia el despliegue de los componentes diseñados en el plan de pruebas. Se deben ver en las listas de recursos de la consola del proveedor.
- [3 puntos] Prueba de funcionalidad: Se muestra el sistema funcionando según el enunciado y el diseño entregado en el Entregable I. El archivo de postman con el que se exhibe y prueba la funcionalidad corresponde al entregado en el proyecto.
30 puntos
1. Análisis de las pruebas de capacidad
Con el monolito desplegado, debe ejecutar las pruebas de capacidad definidas por ustedes en el entregable II.
Incluya un análisis del resultado de cada escenario de pruebas con los siguientes elementos:
- El escenario y los resultados de las pruebas de estrés deberán ser documentados con gráficas que ilustran cómo se comporta el sistema a medida que el número de solicitudes se incrementa hasta llegar al punto de degradar completamente el rendimiento de esta.
- la gráfica de consumo de recursos (CPU, RAM) para el pod. Esta se puede ver en la consola de GCP para la carga de trabajo.
- Un resumen del resultado de la prueba (e.g: este escenario tuvo como resultado que el monolito llega a una degradación del tiempo de respuesta al cumplirse alguna condición).
- Una conclusión sobre el resultado respecto a las respuestas de las preguntas del entregable II.
2. Modelo de despliegue
Basado en los resultados de la ejecución del plan de pruebas debe crear un modelo de despliegue para producción con Deployments, Services y reglas de autoescalamiento que permitan atender la demanda proyectada que recibirá el monolito durante los próximos 18 meses.
Debe realizar una definición a alto nivel de los pods, implementaciones, servicios y reglas de escalabilidad de kubernetes que definió para la solución del proyecto.
- Debe incluir las características técnicas de los pods a ser utilizados en cada despliegue. Debe haber una justificación clara basado en el comportamiento del monolito, el resultado de las pruebas, o los racionales de diseño sobre las decisiones tomadas.
- Agregue un diagrama de despliegue que refleje las decisiones tomadas.
- Agregar una explicación de los modelos de autoescalamiento seleccionados para cada implementación. La explicación debe incluir la métrica sobre la que están definidos y un racional explicando la decisión tomada. Estas decisiones deben estar sustentadas en los resultados de las pruebas de capacidad.
Debe crear un archivo config-prod.yaml que deberá contener la información de despliegue que se utilizará en producción según el diseño que ustedes hayan definido en el modelo de despliegue. Este archivo debe contener una configuración de acuerdo a las decisiones de diseño que tomó. También debe agregar los archivos de autoescalamiento horizontal para los servicios según lo haya definido.
Evaluación
Los siguientes criterios se tendrán en cuenta en el proceso de evaluación y validación de este entregable:
Análisis de las pruebas de capacidad
- [12 puntos] El análisis del resultado de cada escenario de prueba debe estar completo, ser claro y realizar conclusiones concretas sobre el comportamiento del monolito en el respectivo escenario.
Modelo de despliegue
- [4 puntos] Descripción de los pods. Debe haber una justificación clara para la selección de las características técnicas de los pods.
- [10 puntos] Diagrama: Se evaluará que el modelo de despliegue presentado resuelva la necesidad planteada. Las reglas de autoscaling definidas deben ser consecuencias de los hallazgos del Análisis del monolito y la proyección de capacidad.
- [4 puntos] Debe explicar y mostrar claramente cómo las reglas de scaling definidas para los servicios en el config.yaml están sustentadas en el resultado de las pruebas.
18 puntos
En GitHub debe crear un Pull Request entre la rama entrega1 y la rama main de tal manera que se evidencie el desarrollo hecho para la primera entrega. Este Pull Request debe estar en cada repositorio del proyecto y será utilizado para evaluar el desarrollo. Se tendrán en cuenta los siguientes elementos:
- Cambios necesarios para crear una imagen del contenedor que contiene el monolito.
- config-prod.yaml diseñado según las decisiones de diseño expresadas en el modelo de despliegue.
- Yaml utilizado en las pruebas de capacidad.
Evaluación
Los siguientes criterios se tendrán en cuenta en el proceso de evaluación y validación de este entregable:
- [2 puntos] Dockerfile de la imagen del monolito.
- [6 puntos] Archivo de configuración para las pruebas de capacidad.
Config-test.yaml. Se evaluará que el archivo entregado corresponda al diseño del modelo de despliegue planteado en el entregable IV. - [10 puntos] Archivo de configuración para producción
config-prod.yaml. Debe incluir también los archivos para configurar el autoescalamiento. Se evaluará que el archivo entregado corresponda al diseño del modelo de despliegue planteado en el entregable IV.